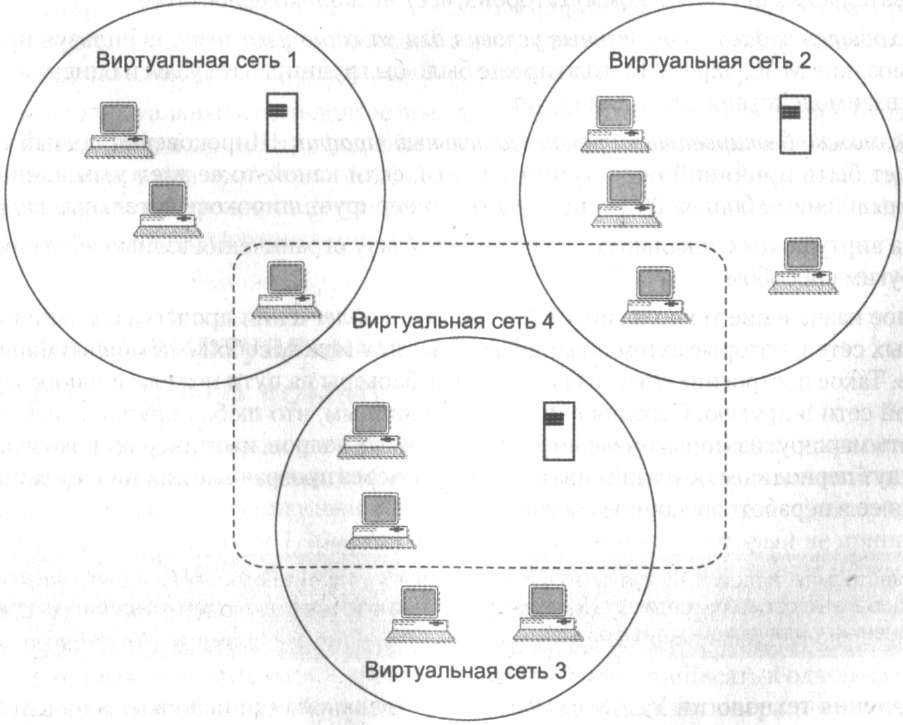
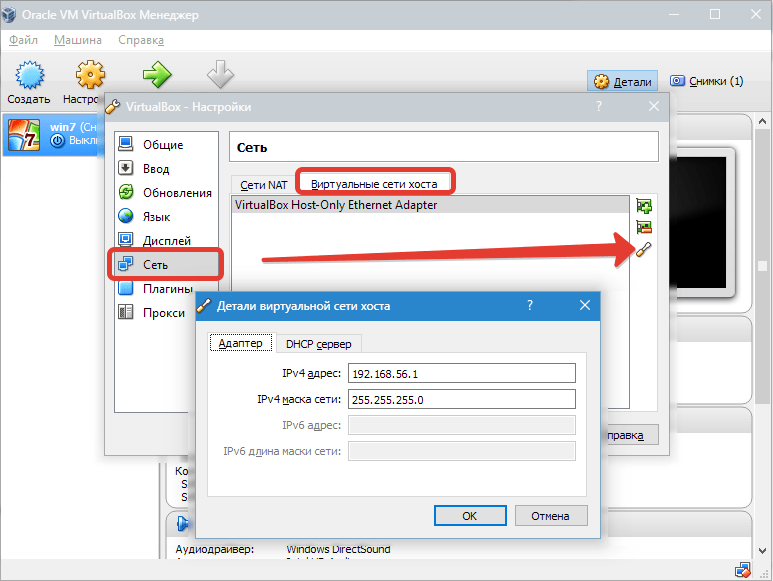
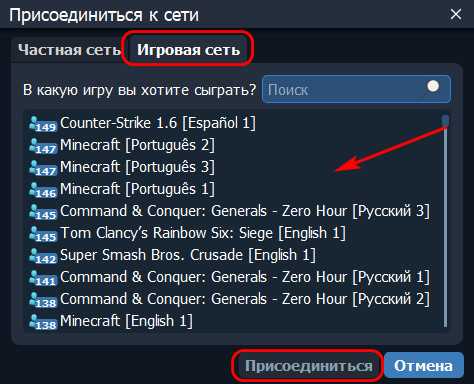
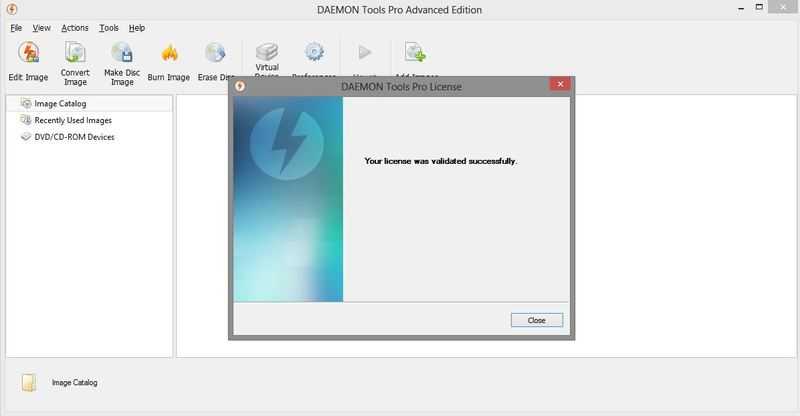
Добро пожаловать в мир компьютерной техники

Системное администрирование
Всё, что связано с системным администрированием. Полезные и интересные материалы, статьи. Делимся опытом.


Devops
Devops — методология активного взаимодействия специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимная интеграция их рабочих процессов друг в друга для обеспечения качества продукта.
DevOps-специалисты – одни из самых востребованных в российском ЕРАМ.
Все про Devops и особенности работы этой системы методов вы найдете на нашем сайте.