Future directions
The AWS Secret Controller PoC enables you to access secret from AWS Secrets Manager by running as an Init container during the pod start up. Future enhancements for this PoC include running a sidecar container in the pod to keep the secret updated whenever the secret is rotated by AWS Secrets Manager.
Secret store Container Storage Interface (CSI) driver enables mounting of secrets, passwords, and certificates from enterprise grade external secret stores as volumes. This project features a pluggable provider interface, which can be leveraged to integrate AWS Secrets Manager as an external secret store for Kubernetes secrets.
Как работает технология
Принципы устройства
Основы работы K8s – применение декларативного подхода. От разработчика требуется указать, чего необходимо достичь, а не способы достижения.
Помимо этого, в Kubernetes могут быть задействованы императивные команды (create, edit, delete), которые позволяют непосредственно создавать, модифицировать и удалять ресурсы. Однако, их не рекомендуется использовать для критически важных задач.
Для развертывания программного обеспечения в Kubernetes применяется база Linux-контейнеров (например, Containerd или CRI-O) и описание — сколько потребуется контейнеров и в каком количестве им потребуются ресурсы. Само развертывание контейнеров происходит на основе рабочих нод — виртуальных или физических машин.
Основные задачи Kubernetes
- Развертывание контейнеров и все операции для запуска необходимой конфигурации. В их число входят перезапуск остановившихся контейнеров, их перемещение для выделения ресурсов на новые контейнеры и другие операции.
- Масштабирование и запуск нескольких контейнеров одновременно на большом количестве хостов.
- Балансировка множества контейнеров в процессе запуска. Для этого Kubernetes использует API, задача которого заключается в логическом группировании контейнеров. Это дает возможность определить их пулы, задать им размещение, а также равномерно распределить нагрузку.
Преимущества K8s
- Обнаружение сервисов и балансировка нагрузок. Контейнеры могут работать через собственные IP-адреса или использовать общее имя DNS для целой группы. K8s может регулировать нагрузку сетевого трафика и распределять его, чтобы поддержать стабильность развертывания.
- Автоматическое управление хранилищами. Пользователь может задавать, какое хранилище использовать для развертывания по умолчанию — внутреннее, внешнего облачного провайдера (GKE, Amazon EKS, AKS), другие варианты.
- Автоматическое внедрение и откат изменений. Пользователь может на лету делать любые дополнения к текущей конфигурации контейнеров. Если это нарушит стабильность развертывания, K8s самостоятельно откатит изменения до стабильно работающей версии.
- Автоматическое распределение ресурсов. Kubernetes сам распределяет пространство и оперативную память из выделенного кластера нод, чтобы обеспечить каждый контейнер всем необходимым для работы.
- Управление паролями и настройками. K8s может служить приложением для безопасной обработки конфиденциальной информации, связанной с работой приложений — паролей, OAuth-токенов, SSH-ключей. В зависимости от способа применения, данные и настройки можно обновлять без создания контейнера заново.
- Самовосстановление при возникновении сбоя. С помощью особых метрик и тестов система может быстро опознать поврежденные или переставшие отвечать на запросы контейнеры. Вышедшие из строя контейнеры создаются заново и перезапускаются на том же поде.
Kubernetes – удобный инструмент оркестрации контейнеров. Однако, это решение, не работает само по себе, без подготовки и дополнительных настроек. Например, пользователям придется решать вопросы по миграции схем баз данных или разбираться с обратной совместимостью API.
DevOps
Armory – это система Spinnaker корпоративного уровня, которая помогает развертывать Kubernetes и обеспечивает представление центра обработки данных и среды AWS на едином экране. Spinnaker для Armory легко устанавливается с Amazon EKS и включает корпоративные функции и возможности интеграции, включая круглосуточную поддержку и обучение.
![]()
Сервер CircleCI 3.x на базе Amazon EKS создан в соответствии с самыми строгими ограничениями с точки зрения безопасности и соответствия требованиям, в том числе нормативным. Это решение с самостоятельным хостингом может масштабироваться в условиях тяжелых нагрузок внутри кластера Kubernetes вашей команды на AWS.
Начало работы | Подробнее
CloudBees Jenkins Enterprise можно интегрировать с Kubernetes в AWS, предоставляя разработчикам гибкое решение для непрерывной интеграции и непрерывного развертывания (CI/CD) с поддержкой разнообразных портфелей программного обеспечения, возможностью внедрения рекомендаций и унифицированного управления.
Начало работы | Подробнее | Смотреть демонстрацию
Codefresh можно использовать для создания, тестирования и развертывания приложений в Amazon EKS.
![]()
CloudBees CodeShip – это SaaS‑решение непрерывной интеграции и непрерывной доставки (CI/CD), которое позволяет техническим специалистам внедрять и оптимизировать непрерывную интеграцию и развертывание в облаке для всех типов приложений, от простых интернет‑приложений до современных архитектур микросервисов, чтобы обеспечить быструю, безопасную и частую доставку кода.
Начало работы | Подробнее
GitLab – решение для разработки и доставки программного обеспечения, созданное для Kubernetes. Оно предоставляет автоматизированные инструменты DevOps, панели развертываний, канареечные развертывания и другие средства для удобного развертывания приложения на Amazon EKS.
![]()
HashiCorp Terraform предоставляет операторам согласованный рабочий процесс выделения инфраструктуры AWS для поддержки Amazon EKS.
Документация | Начало работы | Смотреть демонстрацию
Hasura Gitkube позволяет разработчикам развертывать приложения в кластере Kubernetes с помощью команды `git push`.
JFrog Artifactory обеспечивает наглядное представление артефактов, позволяет прослеживать зависимости от кода до кластерной реализации, предоставляя универсальную поддержку для средств непрерывной интеграции и непрерывной доставки (CI/CD), и развертывает приложения Kubernetes в кластере Amazon EKS.
Начало работы | Подробнее | Смотреть демонстрацию
![]()
Платформа Rafay Kubernetes Operations предоставляет широкий набор операционных услуг, которые помогают командам корпоративных платформ эффективно и успешно управлять жизненным циклом кластеров Amazon EKS и современных приложений (как локально, так и в общедоступных облачных регионах). Она объединяет шесть ключевых сервисов, которые команды корпоративных платформ используют для оптимизации операций EKS и EKS Anywhere во всех регионах AWS в облаке и локально: мультикластерное управление, GitOps, доступ с нулевым доверием, управление политикой Kubernetes, резервное копирование и восстановление, видимость и мониторинг.
Основные компоненты
Схема взаимодействия основных компонентов K8s
Node (Нода)
Ноды или узлы — виртуальные или физические машины, на которых разворачивают и запускают контейнеры. Совокупность нод образует кластер Kubernetes.
Первая запущенная нода или мастер-нода непосредственно управляет кластером, используя для этого менеджер контроллеров (controller manager) и планировщик (scheduler). Она ответственна за интерфейс взаимодействия с пользователями через сервер API и содержит в себе хранилище «etcd» с конфигурацией кластера, метаданными и статусами объектов.
Namespace (Пространство имен)
Объект, предназначенный для разграничения ресурсов кластера между командами и проектами. Пространства имен — несколько виртуальных кластеров, запущенные на одном физическом.
Pod (Под)
Первичный объект развертывания и основной логический юнит в K8s. Поды — набор из одного и более контейнеров для совместного развертывания на ноде.
Группировка контейнеров разных типов требуется в том случае, когда они взаимозависимы и должны запускаться в одной ноде. Это позволяет увеличить скорость отклика во время взаимодействия. Например, это могут быть контейнеры, хранящие веб-приложение и сервис для его кэширования.
ReplicaSet (Набор реплик)
Объект, отвечающий за описание и контроль за несколькими экземплярами (репликами) подов, созданных на кластере. Наличие более одной реплики позволяет повысить устойчивость от отказов и масштабирование приложение. На практике ReplicaSet создается с использованием Deployment.
ReplicaSet является более продвинутой версией предыдущего способа организации создания реплик (репликации) в K8s – Replication Controller.
Deployment (Развертывание)
Объект, в котором хранится описание подов, количество реплик и алгоритм их замены в случае изменения параметров. Контроллер развертывания позволяет выполнять декларативные обновления (с помощью описания нужного состояния) на таких объектах, как ноды и наборы реплик.
StatefulSet (Набор состояния)
Как и другие объекты, например — ReplicaSet или Deployment, Statefulset позволяет развертывать и управлять одним или несколькими подами. Но в отличие от них, идентификаторы подов имеют предсказуемые и сохраняемые при перезапуске значения.
DaemonSet (Набор даемона)
Объект, который отвечает за то, чтобы на каждой отдельной ноде (или ряде выбранных) запускался один экземпляр выбранного пода.
Job/CronJob (Задания/Задания по расписанию)
Объекты для регулировки однократного или регулярного запуска выбранных подов и контроля завершения их работы. Контроллер Job отвечает за однократный запуск, CronJob — за запуск нескольких заданий по расписанию.
Label/Selector (Метки/Селекторы)
Метки предназначены для маркировки ресурсов. Позволяют упростить групповые манипуляции с ними. Селекторы позволяют выбирать/фильтровать объекты на основе значения меток.

По факту, метки и селекторы не являются самостоятельными объектами Kubernetes, но без них система не сможет полноценно функционировать.
Service (Сервис)
Средство для публикации приложения как сетевого сервиса. Используется, в том числе, для балансировки трафика/нагрузки между подами.
Мониторинг
![]()
AppDynamics тесно интегрирован с EKS. Этот инструмент автоматически обнаруживает развернутые приложения и позволяет группам DevOps устанавливать интеллектуальные пороговые значения и создавать предупреждения, чтобы отслеживать и устранять неполадки на стадии появления.
![]()
CloudHealth Technologies упрощает управление контейнерами, обеспечивая наглядность расходов и оптимизацию ресурсов для контейнерных сред.
Подробнее | Смотреть демонстрацию
Datadog отслеживает состояние кластеров Amazon EKS и приложений на основе контейнеров с использованием журналов, метрик и данных о производительности приложений.
Подробнее | Смотреть демонстрацию
![]()
Dynatrace обеспечивает подробный мониторинг и информационные панели для наглядного представления производительности и работоспособности приложений Kubernetes в режиме реального времени. ПО Dynatrace OneAgent готово к работе в среде на основе контейнеров и включает в себя встроенные возможности мониторинга сервиса Amazon EKS вплоть до уровня инфраструктуры (с возможностью мониторинга отдельных приложений).
Начало работы | Подробнее | Смотреть демонстрацию | Пробная версия
New Relic обеспечивает подробный мониторинг и информационные панели для наглядного представления производительности приложений Kubernetes в режиме реального времени.
SignalFx в режиме реального времени предоставляет метрики и панели управления, а также генерирует предупреждения для Amazon EKS.
Смотреть демонстрацию
Solarwinds выполняет мониторинг кластеров Kubernetes и состояния приложений в ЦОД. Средство обнаружения сервисов, интегрированное с EKS, отслеживает поды, развертывания и сервисы.
Splunk Connect для Kubernetes дополняет Amazon EKS, позволяя компаниям удобно собирать журналы, события и метрики для контейнеров и кластеров.
Подробнее | Смотреть демонстрацию
SumoLogic интегрирован с Kubernetes, работающим на AWS, чтобы обеспечивать непрерывную аналитику работы приложений в реальном времени.
Подробнее | Смотреть демонстрацию
Задание свойства кластера cluster-recheck-interval
указывает интервал опроса, с которым кластер проверяет наличие изменений в параметрах ресурсов, ограничениях или других параметрах кластера. Если реплика выходит из строя, кластер пытается перезапустить ее с интервалом, который связан со значениями и . Например, если для установлено значение 60 с, а для — 120 с, то повторная попытка перезапуска предпринимается с интервалом, который больше 60 с, но меньше 120 с. Мы рекомендуем установить для failure-timeout значение, равное 60 с, а для cluster-recheck-interval значение больше 60 с. Задавать для cluster-recheck-interval небольшое значение не рекомендуется.
Чтобы изменить значение свойства на , выполните следующую команду:
Важно!
Если у вас уже есть ресурс группы доступности, управляемый кластером Pacemaker, обратите внимание, что все дистрибутивы, использующие последний доступный пакет Pacemaker 1.1.18-11.el7, вносят изменение в поведение для параметра start-failure-is-fatal cluster, когда его значение равно false. Это изменение влияет на рабочий процесс отработки отказа
В случае сбоя первичной реплики ожидается, что будет выполнена отработка отказа кластера на одну из доступных вторичных реплик. Вместо этого пользователи увидят, что кластер продолжает попытки запустить первичную реплику с ошибкой. Если первичная реплика не включается (из-за постоянного сбоя), кластер не выполняет отработку отказа на другую доступную вторичную реплику. Из-за этого изменения рекомендуемая ранее конфигурация для установки параметра start-failure-is-fatal больше не действительна, и для этого параметра нужно вернуть значение по умолчанию . Кроме того, нужно обновить ресурс группы доступности для включения свойства .
Чтобы изменить значение свойства на , выполните следующую команду:
Измените существующее свойство ресурса группы доступности на выполнение (замените именем ресурса группы доступности).
Платформа
Banzai Cloud Pipeline позволяет разработчикам перейти от подтверждения к масштабированию за считаные минуты, превратив Amazon EKS в многофункциональную, ориентированную на приложения платформу, которая включает в себя CI/CD, централизованное ведение журналов, мониторинг, защиту корпоративного класса, автоматическое масштабирование и поддержку спотовых цен.
![]()
Spotinst упрощает процесс создания и масштабирования кластера Amazon EKS, автоматически подключая Elastigroup для управления базовыми инстансами EC2 с использованием инстансов Spot, что помогает экономить до 80 % средств на вычислительных ресурсах.
![]()
SUSE Cloud Application Platform (CAP) в Amazon EKS образует безопасную, стабильную и масштабируемую среду разработки и развертывания для микросервисов.
Смотреть демонстрацию
Creating secrets
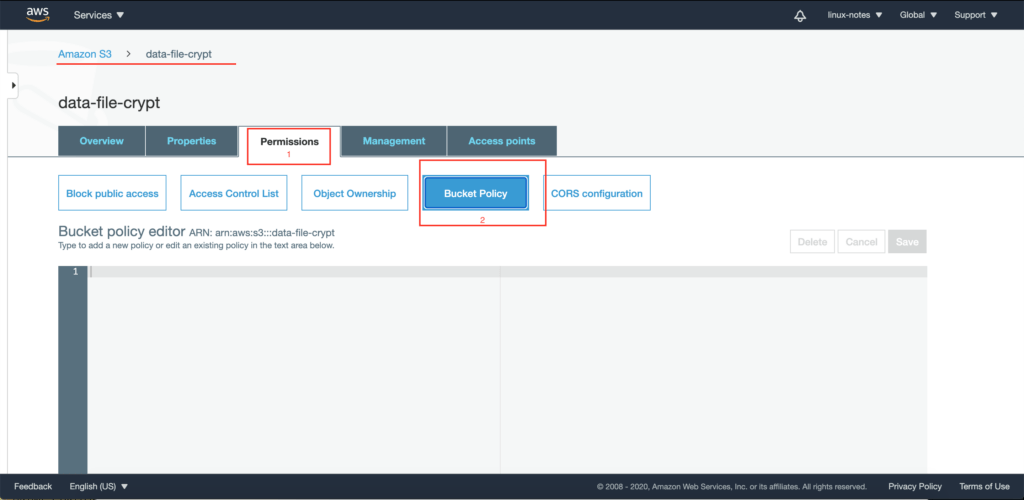
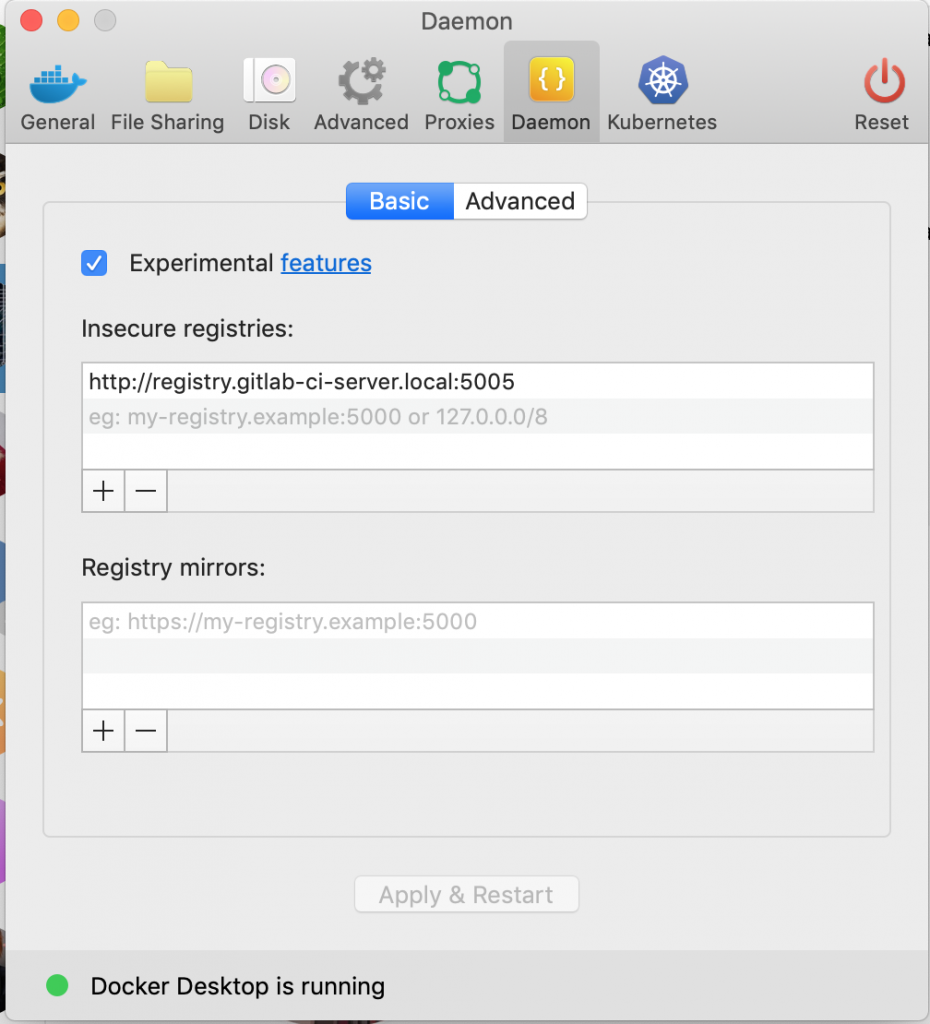
You can create and manage secrets in Secrets Manager using the native AWS APIs, however, you may want to manage AWS Secrets Manager secrets directly from Kubernetes. The Native Secrets (NASE) project is a serverless mutating webhook. It is implemented as a Lambda function with an HTTP API endpoint, which is registered with Kubernetes as part of the mutating webhook object. Calls to create and update native Kubernetes Secrets are “redirected” to the webhook which writes the secret in the secret manifest to Secrets Manager and returns the ARN of the secret to Kubernetes which stores it as a secret.
Solution overview
This proof of concept (PoC) makes use of the following Kubernetes constructs:
- Annotations are an array of non-identifying key-value pairs. In this instance, we’re using annotations to enable/disable the init container injector, specify the AWS ARN of the secret.
- The is a mechanism to get metadata about a pod. In this solution, we’re using it to retrieve the values of a set of key-value pairs in the annotation field of the pod.
- A is called when a pod is created. It is implemented as a pod that runs within the cluster. If the appears in the annotations field, the webhook will inject the init container into the pod.
- IAM Roles for Service Accounts (IRSA) is a way to assign an IAM role to a Kubernetes pod. This PoC uses IRSA to grant the pod access to retrieve a secret from Secrets Manager and decrypt that secret using a KMS key. It’s through the ServiceAccount that you can grant access to secrets in Secrets Manager.
- An init container is a container that runs and exits before the application container is started. In our PoC, the init container is used to fetch the secret from Secrets Manager and writes it to an emptyDir (RAM disk) volume that is subsequently mounted by the application container.
When a pod with the requisite annotations is deployed to the cluster, the webhook will update the pod to run the init container. Provided the ServiceAccount specified in the podSpec has access to the secret referenced in the the init container will retrieve the secret from Secrets Manager and write it to a RAM disk. This is done by specifying using as the medium for an volume. This prevents the secrets from being persisted to disk after pod is terminated. After the init container exits, the application container starts and mounts the RAM disk as a volume. When the application needs to read the secret, it reads it from the mounted volume. The diagram below depicts the webhook process flow the PoC follows:



![]()
Добавление ограничения совместного размещения
Почти каждое решение в кластере Pacemaker, например выбор места запуска ресурса, принимается путем сравнения оценок. Оценки вычисляются для каждого ресурса, а диспетчер ресурсов кластера выбирает узел с наивысшей оценкой для конкретного ресурса. (Если узел имеет отрицательную оценку для ресурса, последний не может выполняться в этом узле.) Используйте ограничения для настройки решений в кластере. Ограничения имеют оценку. Если ограничение имеет оценку меньше бесконечности (INFINITY), то это только рекомендация. Оценка, равная INFINITY, указывает на обязательный характер. Чтобы убедиться, что первичная реплика и ресурс виртуального IP-адреса находятся на одном узле, определите ограничение совместного размещения с оценкой INFINITY. Чтобы добавить ограничение совместного размещения, выполните приведенную ниже команду на одном узле.
Caveats
Although this PoC gives you a Kubernetes native way to consume secrets from AWS Secrets Manager, it has a few caveats that you ought to be aware of. First, there is a cost for storing and retrieving secrets. Second, Secrets Manager has limits around the size (64KB) of secrets and the rate at which they can be retrieved, e.g. the limit for GetSecretValue is 2,000 per second. Be sure that you’ve reviewed the costs and limits before implementing this solution.
The PoC is also more complex as compared to native Kubernetes secrets. For example, you need to install and register the mutating webhook. You also need to correctly annotate the pods that will consume secrets from Secrets Manager and they have to reference a Service Account that has the necessary permission to fetch the secret referenced in the annotation. That said, if you need a mechanism to provide granular access to secrets or you need to rotate your secrets, the additional overhead may be worth it.
Lastly, the purpose of this Poc is to demonstrate the type of integration that can be achieved between AWS Secrets Manager and Kubernetes. It is not meant to be used in production.
Настройка/Использование Spinnaker в Unix/Linux
И так, настройка прошла успешно. Открыли Spinnaker на http://localhost:9000. Домашняя станица Spinnaker-а выглядит следующим образом:
В поле поиска, можно поискать проекты, кластера, ЛБ, секьюрити группы и тд и тп. Например:
Приступим к использованию!
Создание Spinnaker пайплайна
Начну создание приложения под названием MyTestApp:
Нажимаем на кнопку «Create». Созданное приложение выглядит так:
Идем далее, создаем лоад баллансер, для этого клацаем по «Load Balancers» -> «Create Load Balancer»:
Во вкладке с «BASIC SETTINGS», заполняем:
- Account -> local.
- Namespace -> default.
- Stack -> prod.
Далее, во вкладке с «PORTS»:
В данной вкладке стоит прописать:
Далее, во вкладке с «ADVANCED SETTINGS»:
В данной вкладке, прописываем:
Нажимаем на «Create». Аналогичными действиями, создаем ЛБ с названием «dev», но только в последней вкладке стоит выбрать «ClusterIP»:
После чего, должно выти что-то типа следующего:
ЛБы готовы и теперь можно создавать pipeline, переходим в данную вкладку и нажимаем на «Create»:
Заполняем:
Нажимаем на «Create»:
Жмакаем на «Save Changes». Прокручиваем стрцницу вверх и кликаем на «Add stage»:
Заполняем:
Затем кликаем по «Add server group»:
Я выбрал:
Нажимаем на «Continue without a template»:
Нажимаем на вкладку «LOAD BALANCERS» и выбираем нужный (в данном случае — mytestapp-prod):
Переходим во «CONTAINER» вкладку и заполняем:
В данной вкладке, стоит открыть «Probes» и добавляем использование Readiness Probe и Liveness Probe:
И так, нажимаем на «Add» чтобы добавить наши ченджи. И потом, кликаем по «Save Changes».
Т.к я деплою nginx, а не приложение с кодом (так бы сработал триггер по коммиту), то запущу «Start manual execution»:
Выбераем параметры:
Нажимаем на «Run».
Получаем сервисы:
Чтобы проверить, работает ли деплоймент, пробросим прокси куба:
ЗАМЕЧАНИЕ: для того чтобы прокси работал в бэкграунде, выполняем:
Т.к я деплоил mytestapp-prod приложение, а оно находится на http://127.0.0.1:30294/ то кликаем по нему и попадаем собственно на задеплоенный nginx!
Стоит выполнить ряд действий для dev стейджа. Клацаем «Pipelines» -> «Create». Название выбираем название «DeployToDev»:
После чего. Нажимаем на «Save Changes». И кликаем «Add Stage»:
Заполняем:
- Type -> Deploy.
- Stage Name -> Deploy.
В поле «Add server group», выбераем «mytestapp-prod-v000»:
Выбираем из списка и нажимаем на «Use this template». Он скопирует темплейт в новый. Немного поправим его:
Далее, в поле «Load Balancers»:
Заменили и идем в «Container»:
Во вкладке «Probes», включаем Readiness Probe и Liveness Probe (как в примерах выше). После всех настроек, клацаем на «Add» -> «Save Changes».
Вернусь в главное меню апликейшина и нажму на только созданный пайплайн:
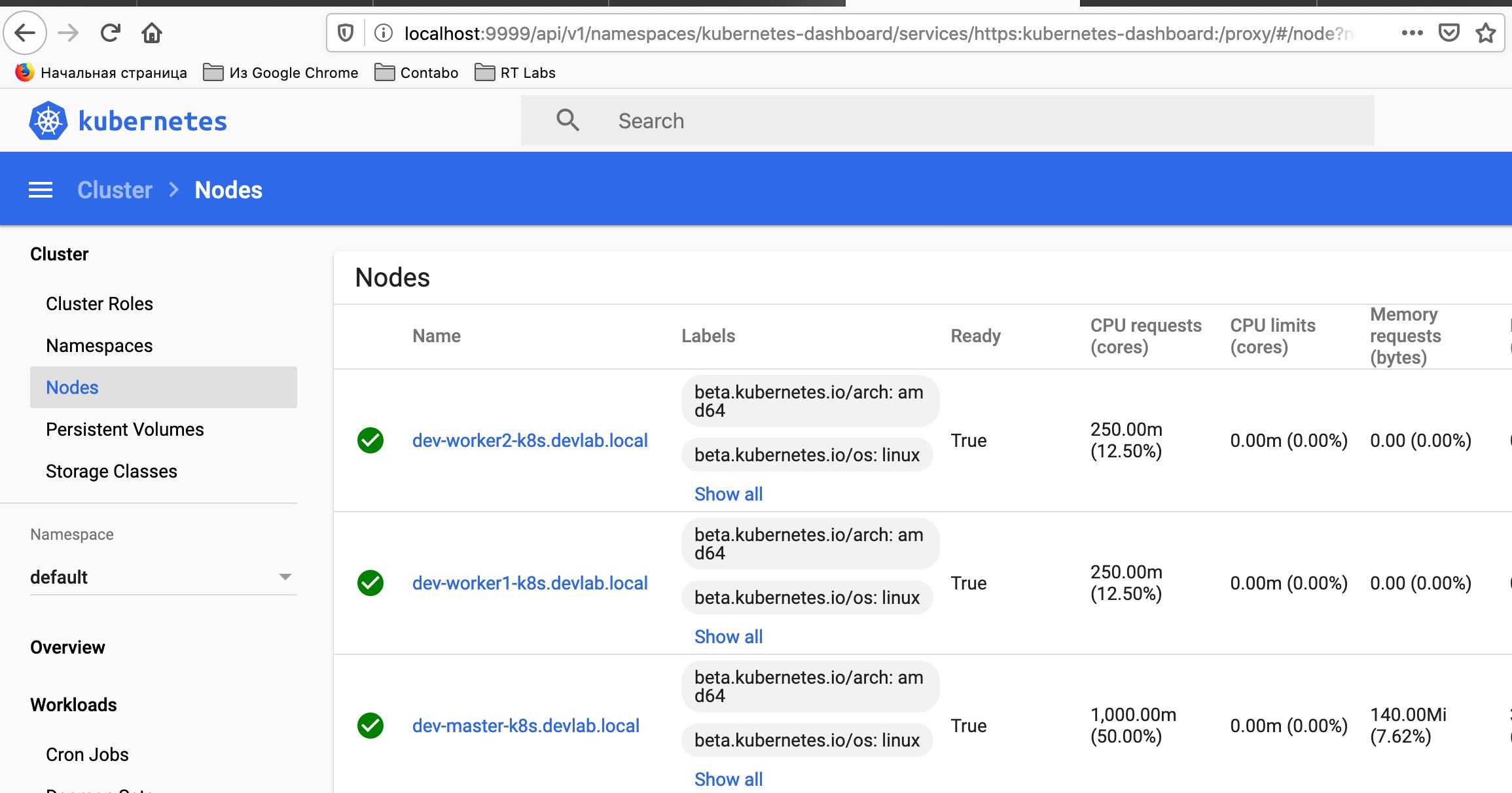
Скачаем дашборды для куба:
Смотрим токены:
Открываем — http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
С помощью данных бордов можно смотреть инфу.
В завершении, содаем новый пайплайн с названием PromoteToProd:
Жмакаем на «Create». И заполняем поля:
Нажимаем на «Save Changes». После чего, открываем «Add Stage»:
Заполняем и клацаем на «Save Changes». Клацаем на «Add stage» для создания деплоя на ПРОД:
Клацаем на «Add server group» и выбераем «Copy configuration from», а имеено с «None» и кликаем на «Continue without any templates». Заполняем:
Кликаем на «Add» -> «Save Changes».
Нажимаем на билды. Перекидываем с dev -> prod:
Проверяем через ИП деплой! Все должно работать.
Вот и все, статья «Установка Spinnaker в Unix/Linux» завершена.
Соглашение об уровне обслуживания
Вопрос. Что гарантирует соглашение об уровне обслуживания (SLA) Amazon ECS?
Соглашение об уровне обслуживания (SLA) гарантирует бесперебойную ежемесячную работу Amazon ECS на уровне не менее 99,99 %.
Вопрос. Как узнать, могу ли я претендовать на компенсацию по соглашению об уровне обслуживания?
Компенсация по SLA Amazon ECS по условиям нашего SLA в отношении вычислительных процессов предоставляется, если бесперебойная ежемесячная работа сервиса в рамках одного региона в нескольких зонах доступности, в которых запущено задание, составила менее 99,99 % в течение любого оплачиваемого месяца.
С условиями и положениями соглашения об уровне обслуживания, а также подробностями оформления заявки на компенсацию можно ознакомиться на странице сведений о SLA в отношении вычислительных процессов.
Схема действий
Действия по созданию группы доступности на серверах Linux для обеспечения высокой доступности отличаются от действий, выполняемых в отказоустойчивом кластере Windows Server. Ниже описывается общий порядок действий.




Настройте диспетчер ресурсов кластера, например Pacemaker
Эти инструкции приведены в этом документе.
Способ настройки диспетчера ресурсов кластера зависит от конкретного дистрибутива Linux.
Важно!
Для обеспечения высокого уровня доступности в рабочих средах требуется агент ограждения, например STONITH. В примерах в этой документации агенты ограждения не используются
Примеры приводятся только для тестирования и проверки.
Кластер Linux использует ограждение для возврата кластера в известное состояние. Способ настройки ограждения зависит от дистрибутива и среды. В настоящее время ограждение недоступно в некоторых облачных средах. Дополнительные сведения см. в статье о политиках поддержки для кластеров RHEL с высоким уровнем доступности на платформах виртуализации.
Ограждение обычно реализуется в операционной системе и зависит от среды. Инструкции по установке ограждений см. в документации распространителя операционной системы.
История создания
Проект Kubernetes (сокращенно K8s) вырос из системы управления кластерами Borg. Внутренний продукт поискового гиганта Google получил название в честь кибер-рассы боргов из легендарного сериала «Звездный путь».
Команде разработчиков Google Borg была поставлена масштабная задача — создать открытое программное обеспечение для оркестрирования* контейнеров, которое станет вкладом Google в развитие мировых IT-технологий. Приложение было написано на основе языка Go.
На этапе разработки K8s назвался Project Seven («Проект «Седьмая»). Это было прямой отсылкой к персонажу «Звездного пути» Seven of Nine («Седьмая-из-девяти») — андроиду-боргу, сумевшему вернуть себе человечность. Позже проект получил имя «Кубернетес», от греческого слова κυβερνήτης, которое означает «управляющий», «рулевой» или «кормчий».
В 2014 году общественности представили исходные коды, а годом позже появилась первая версия программы Kubernetes 1.0. В дальнейшем все права на продукт были переданы некоммерческому фонду Cloud Native Computing Foundation (CNCF), куда входят Google, The Linux Foundation и ряд крупнейших технологических корпораций.
Планирование
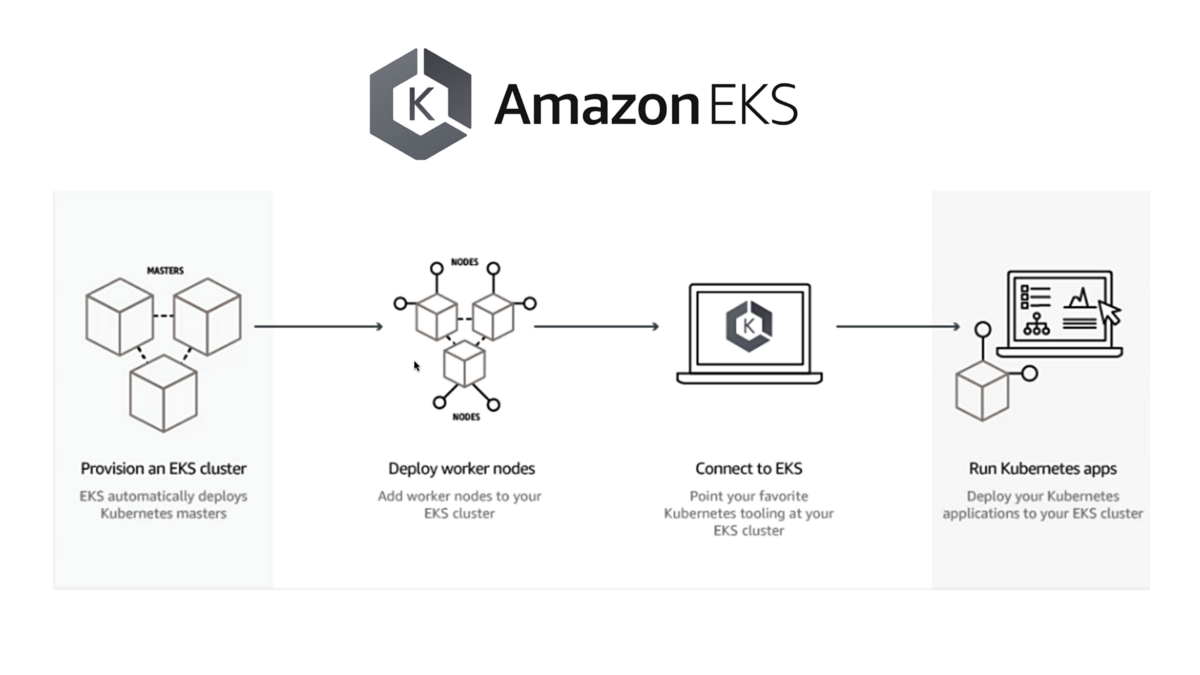
Помимо планирования самого процесса миграции и учёта дополнительных зависимостей, есть несколько технических аспектов, которые клиенты должны предусмотреть, чтобы избежать неожиданностей во время миграции. Как мы уже упоминали, EKS использует основную версию Kubernetes, поэтому приложения, работающие на Kubernetes, должны работать на EKS без каких-либо изменений. Вот несколько ключевых технических аспектов, которые необходимо учесть во время миграции.
Версии Kubernetes чтобы избежать любых несоответствий в API, планируйте миграцию рабочих нагрузок на ту же версию Kubernetes в EKS, которая используется в настоящий момент. Если вы используете версию, которая не поддерживается EKS, то обновления ваших существующих кластеров до актуальных версий Kubernetes может отнять много времени и, возможно, не требуется
В таком случае важно проверить список изменений, выявить устаревшие API и перестать использовать их после миграции. Безопасность:
Аутентификация: EKS поддерживает интеграцию с IAM, в которой (1) пользователь или роль, которая создала кластер изначально, получает к нему полный администраторский доступ и (2) доступ другим пользователям и ролям предоставляется через ConfigMap aws-auth
Вы также можете предоставлять доступ к кластеру EKS с помощью аутентификации через провайдера идентификации OpenID Connect (OIDC), затем использовать Role и ClusterRole в Kubernetes, чтобы назначить права доступа на роль, и в конце привязать эти роли к учётным записям с помощью RoleBinding и ClusterRoleBinding.
Роли IAM для сервисных аккаунтов: приложениям в Kubernetes часто требуется доступ к AWS API, чтобы создавать новые ресурсы или работать с уже созданными. Для этого им необходимо предоставить соответствующие права доступа. Один из важнейших принципов безопасности – это принцип наименьших привилегий (least privilege principle). С помощью ролей IAM вы можете ограничить предоставление прав доступа для определённого сервисного аккаунта и пода, который этот аккаунт использует.
Сеть:
VPC CNI: Amazon EKS использует Amazon VPC CNI для работы с сетевыми возможностями VPC. VPC CNI назначает подам такой же IP-адрес внутри Kubernetes, какой они получают в самом VPC, что повышает прозрачность и возможности по мониторингу и отладке.
AWS Load Balancer Controller: для использования различной новой функциональности и возможностей тонкой настройки AWS предоставляет AWS Load Balancer Controller. Он поддерживает работу не только с сервисами Kubernetes, но и с ресурсами ingress и позволяет вам создавать балансировщики нагрузки Application Load Balancer (ALB) для веб-приложений.
Хранение данных
CSI-драйверы EBS/EFS/FSx: Kubernetes поддерживает рабочие нагрузки с сохранением состояния (stateful) с помощью ресурсов PersistentVolume (PV) и PersistentVolumeClaim (PVC). Изначально интеграция с сервисами для хранения данных Elastic Block Store (EBS) и Elastic File System (EFS) в Kubernetes была реализована с помощью Volume Plugin. Однако при таком подходе любые исправления и улучшения требовали внесения изменений в основную версию Kubernetes, что приводило к увеличению времени, требуемого для обновления. Для устранения этого недостатка был создан Container Storage Interface (CSI), который позволяет обновлять драйверы для систем хранения данных независимо от обновлений Kubernetes. AWS поддерживает CSI-драйверы для EBS, EFS и FSx for Lustre. В зависимости от ваших требований вы можете выбрать один из указанных сервисов для сохранения состояния ваших рабочих нагрузок.