Install Logstash
Logstash is an open source tool, it collects the logs, parse and store them on Elasticsearch for searching. Over 160+ plugins are available for Logstash, which provides the capability of processing a different type of events with no extra work.
Install Logstash using the apt-get command.
apt-get install -y logstash
Create SSL certificate
Forwarder (filebeat) which will be installed on client servers uses SSL certificate to validate the identity of Logstash server for secure communication.
Create SSL certificate either with the hostname or IP SAN.
Option 1: (Hostname FQDN)
If you use the hostname in the beats (forwarder) configuration, make sure you have A record for logstash server; ensure that client machine can resolve the hostname of the logstash server.
If you do not have a nameserver in your environment; make sure you add the host entry for logstash server in client machines as well as in the logstash server.
sudo nano /etc/hosts 192.168.12.10 server.itzgeek.local
Go to the OpenSSL directory.
cd /etc/ssl/
Now, create the SSL certificate. Replace “green” one in with the hostname of your real logstash server.
openssl req -x509 -nodes -newkey rsa:2048 -days 365 -keyout logstash-forwarder.key -out logstash-forwarder.crt -subj /CN=server.itzgeek.local
Option 2: (IP Address)
If you are planning to use IP address instead of hostname, please follow the steps to create a SSL certificate for IP SAN.
As a pre-requisite, we would need to add an IP address of logstash server to SubjectAltName in the OpenSSL config file.
nano /etc/ssl/openssl.cnf
Look for “” section and replace “green” one with the IP of your logstash server.
subjectAltName = IP:192.168.12.10
Goto OpenSSL directory.
cd /etc/ssl/
Now, create a SSL certificate by running following command.
openssl req -x509 -days 365 -batch -nodes -newkey rsa:2048 -keyout logstash-forwarder.key -out logstash-forwarder.crt
This logstash-forwarder.crt should be copied to all client servers those who send logs to logstash server.
Configure Logstash
Logstash configuration can be found in /etc/logstash/conf.d/. If the files don’t exist, create a new one. logstash configuration file consists of three sections input, filter, and the output; all three sections can be found either in a single file or each section will have separate files end with .conf.
I recommend you to use a single file to placing input, filter and output sections.
nano /etc/logstash/conf.d/logstash.conf
In the first section, we will put an entry for input configuration. The following configuration sets Logstash to listen on port 5044 for incoming logs from the beats (forwarder) that sit on client machines. Also, add the SSL certificate details in the input section for secure communication.
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/ssl/logstash-forwarder.crt"
ssl_key => "/etc/ssl/logstash-forwarder.key"
congestion_threshold => "40"
}
}
In the filter section. We will use Grok to parse the logs ahead of sending it to Elasticsearch. The following grok filter will look for the “syslog” labeled logs and tries to parse them to make a structured index.
filter {
if == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
date {
match =>
}
}
}
In the output section, we will define the location where the logs to get stored; obviously, it should be Elasticsearch.
output {
elasticsearch {
hosts => localhost
index => "%{}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
Now start and enable the logstash.
systemctl start logstash systemctl enable logstash
You can troubleshoot any issues by looking at below log.
cat /var/log/logstash/logstash-plain.log
Next, we will configure beats to ship the logs to logstash server.
Установка Nginx
Теперь Kibana прослушивает localhost. Чтобы получить внешний доступ к сервису, настройте Nginx как обратный прокси-сервер.
Примечание: Если у вас уже есть установленный сервер Nginx, используйте этот экземпляр. Вам нужно только настроить доступ к Kibana для Nginx (измените значение host в файле /opt/kibana/config/kibana.yml, указав IP-адрес сервера Kibana). Также рекомендуется включить SSL/TLS.
Установите Nginx:
С помощью openssl создайте аккаунт администратора, у которого будет доступ к веб-интерфейсу Kibana (в руководстве он называется kibanaadmin, но вы можете использовать другое имя).
Введите пароль пользователя. В дальнейшем с помощью этого пароля вы сможете получить доступ к интерфейсу.
Откройте виртуальный хост Nginx по умолчанию в текстовом редакторе.
Удалите его содержимое и вставьте следующий код. В строке server_name укажите имя своего сервера.
Сохраните и закройте файл. Теперь Nginx будет передавать HTTP-трафик приложению Kibana, которое прослушивает localhost:5601. Nginx будет использовать ранее созданный файл htpasswd.users и запрашивать базовую аутентификацию.
Перезапустите Nginx, чтобы обновить настройки.
Если вы следовали руководству по начальной настройке сервера, вы включили брандмауэр UFW; теперь он блокирует соединения Nginx. Разблокируйте их:
Теперь веб-интерфейс Kibana доступен по FQDN или внешнему IP-адресу сервера ELK.
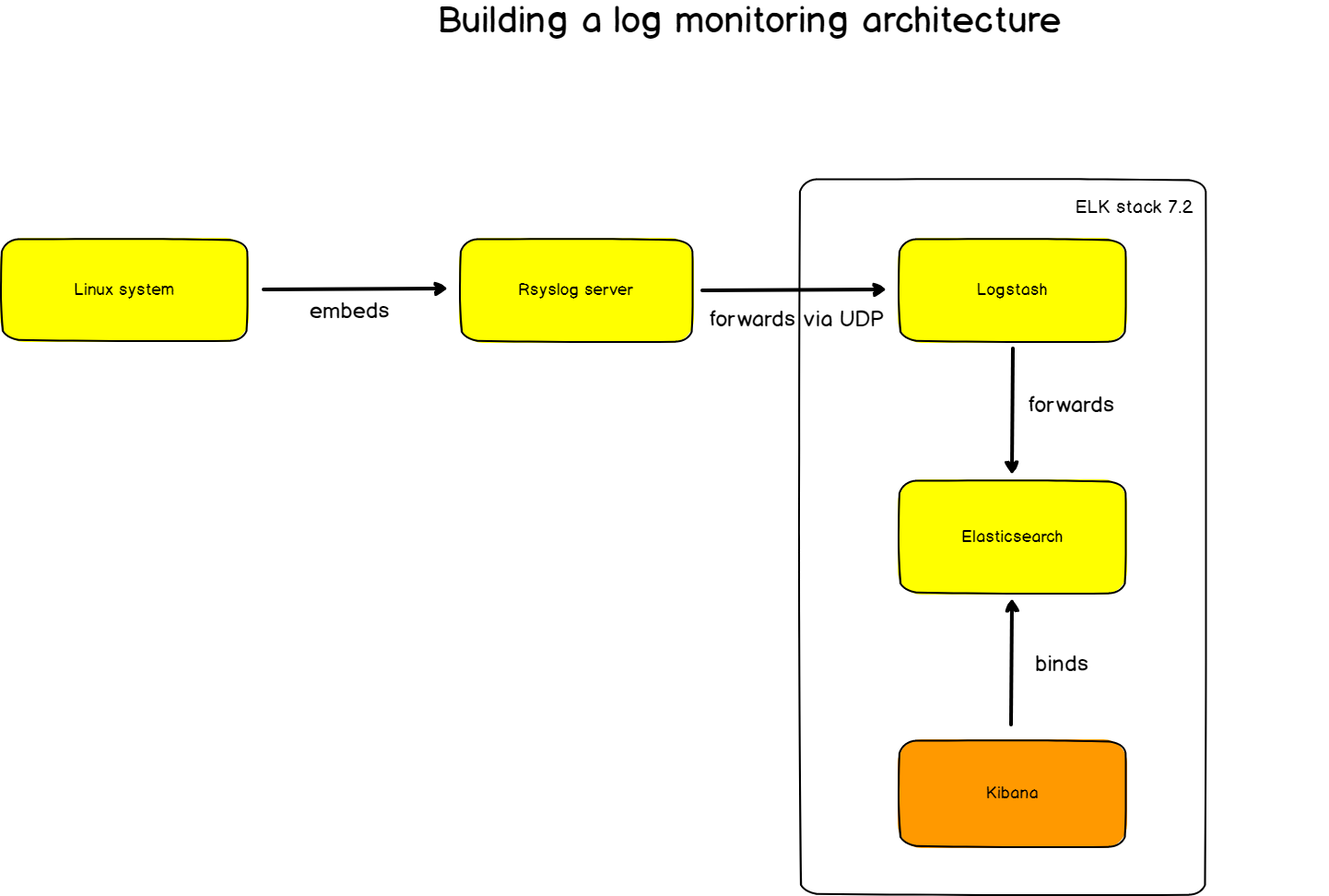
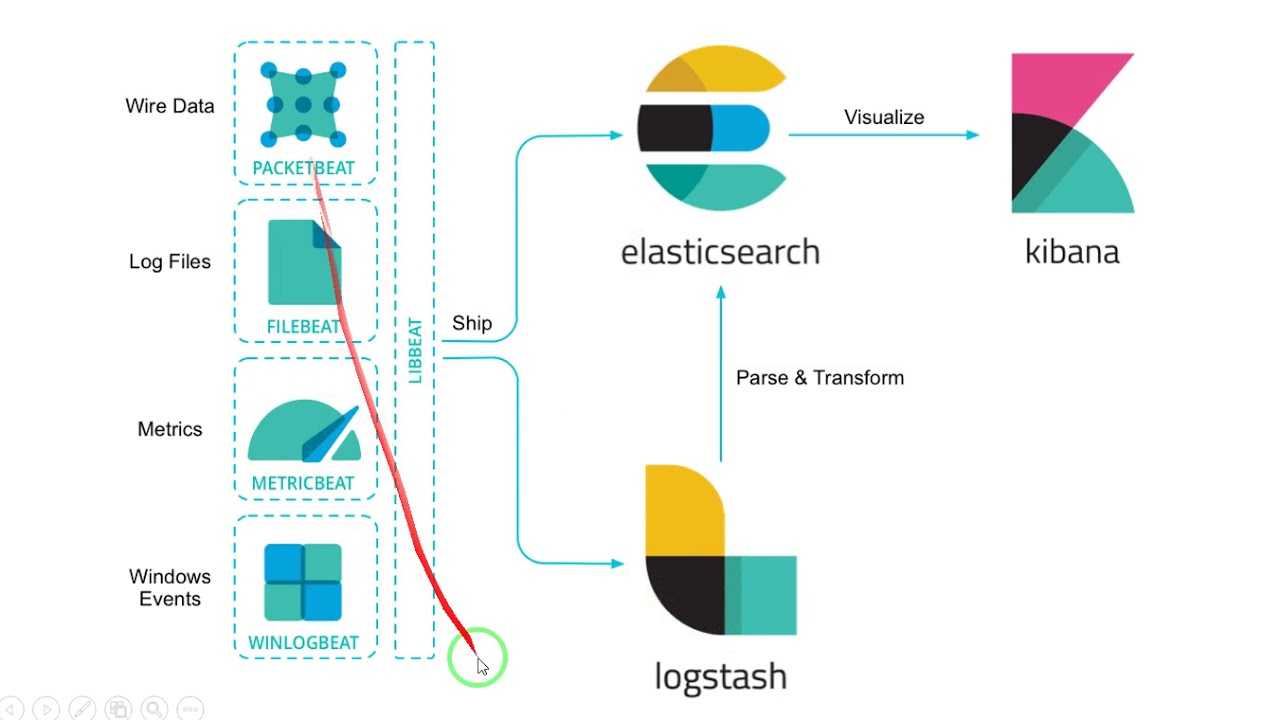
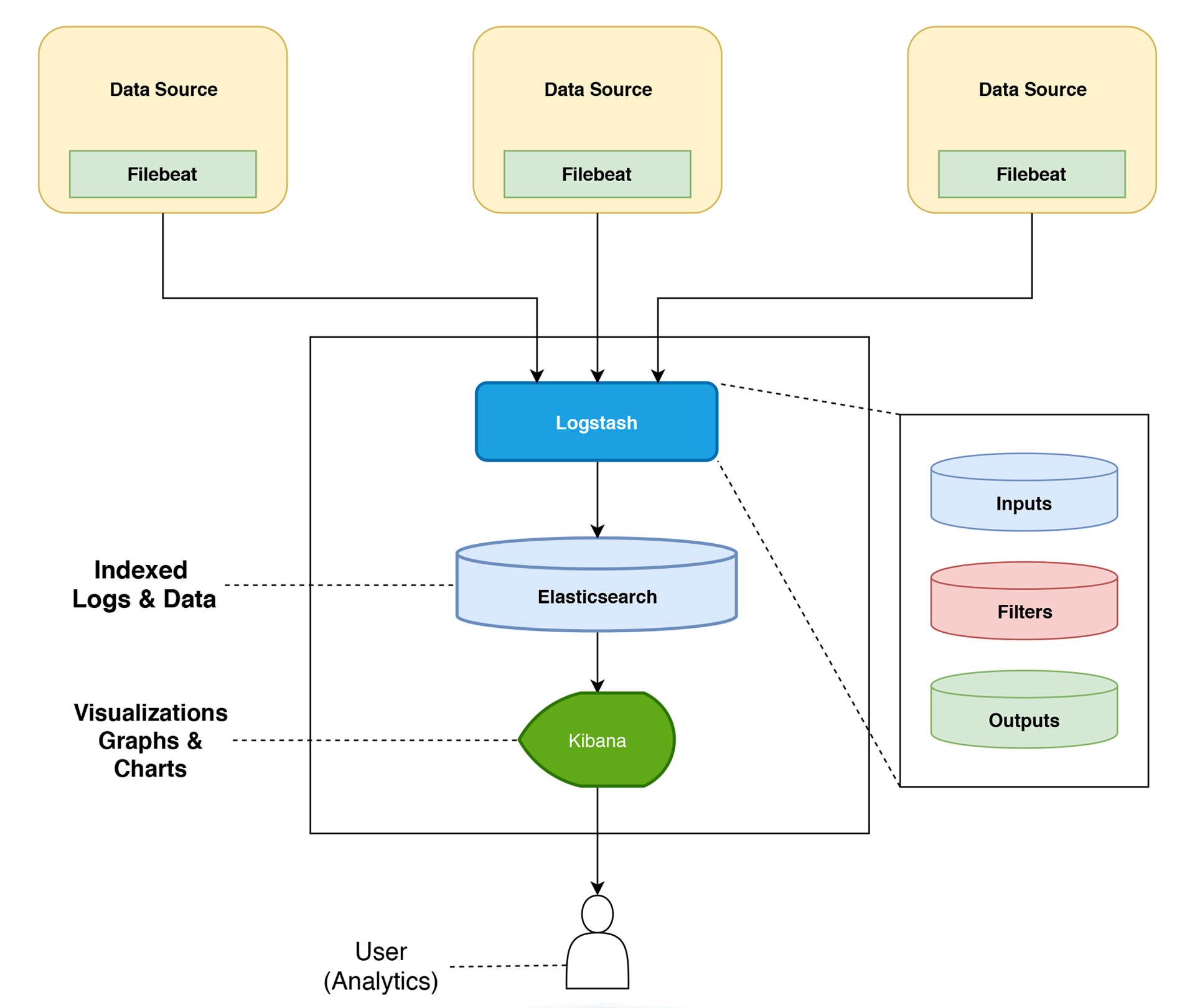
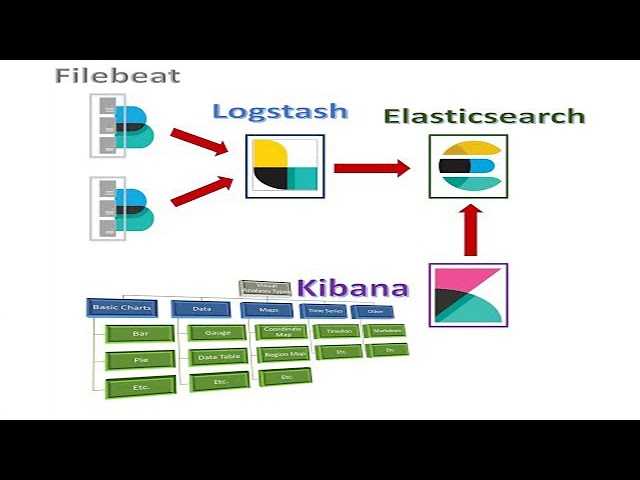
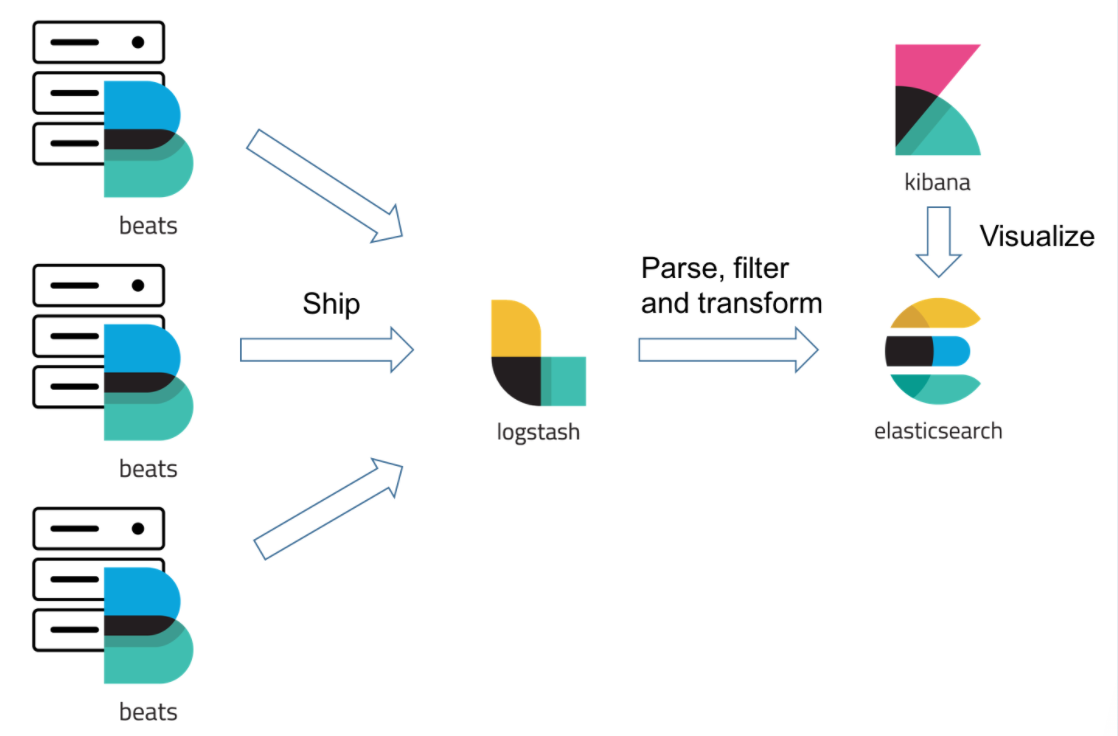
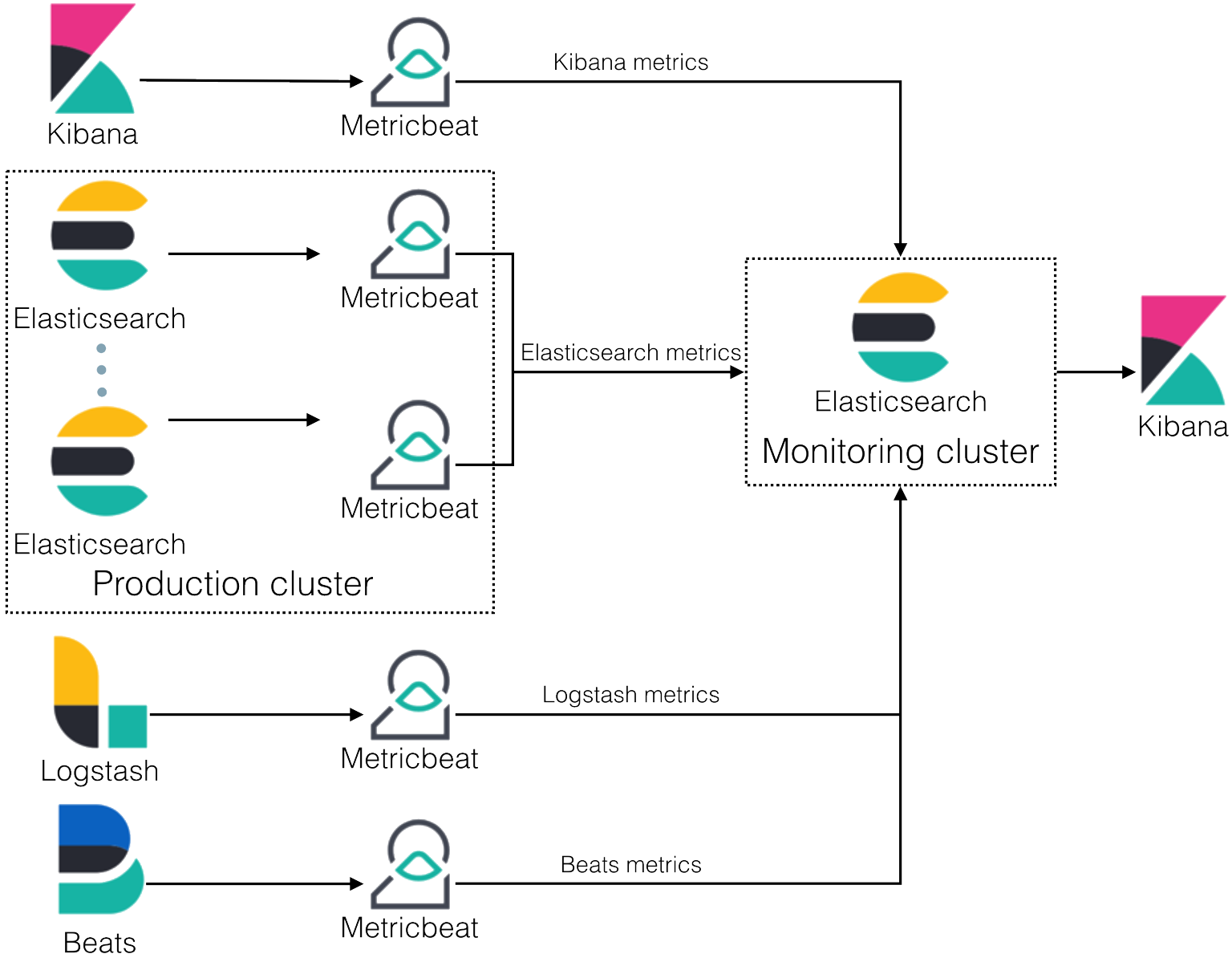
So…When Do I Use Filebeat and/or Logstash?
The simple answer is — when logging files at least, you will almost always need to use a combination of Filebeat and Logstash. Why? Because unless you’re only interested in the timestamp and message fields, you still need Logstash for the “T” in ETL (Transformation) and to act as an aggregator for multiple logging pipelines.
Filebeat is one of the best log file shippers out there today — it’s lightweight, supports SSL and TLS encryption, supports back pressure with a good built-in recovery mechanism, and is extremely reliable. It cannot, however, in most cases, turn your logs into easy-to-analyze structured log messages using filters for log enhancements. That’s the role played by Logstash.
Logstash acts as an aggregator — pulling data from various sources before pushing it down the pipeline, usually into Elasticsearch but also into a buffering component in larger production environments. It’s worth mentioning that the latest version of Logstash also includes support for persistent queues when storing message queues on disk.
Filebeat, and the other members of the Beats family, acts as a lightweight agent deployed on the edge host, pumping data into Logstash for aggregation, filtering and enrichment.
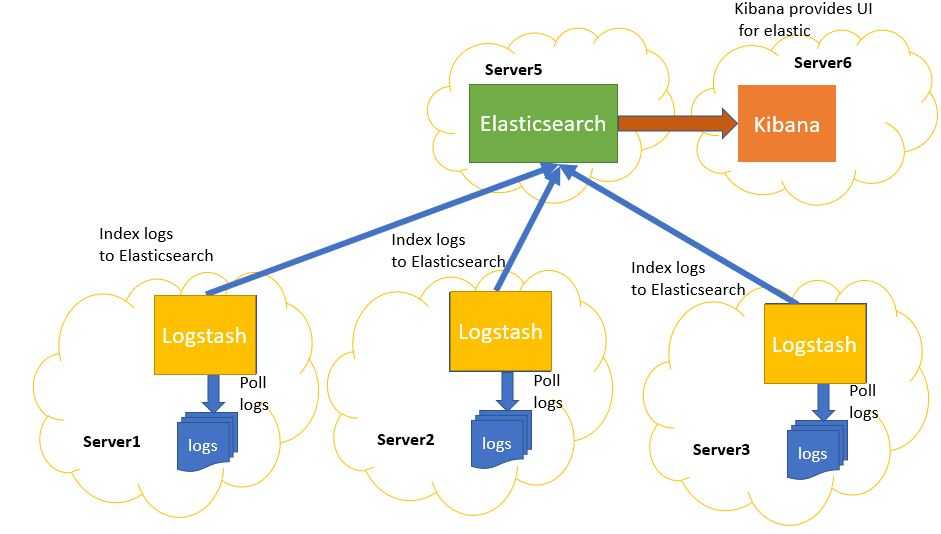
The relationship between the two log shippers can be better understood in the following diagram:
![]()
Example: Apache Access Logs
Apache access logs can be used for monitoring traffic to your application or service.
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
If you’re using ELK as your logging solution, one way to ship these logs is using Filebeat to send the data directly into Elasticsearch. Since Filebeat ships data in JSON format, Elasticsearch should be able to parse the timestamp and message fields without too much hassle. Not only that, Filebeat also supports an Apache module that can handle some of the processing and parsing.
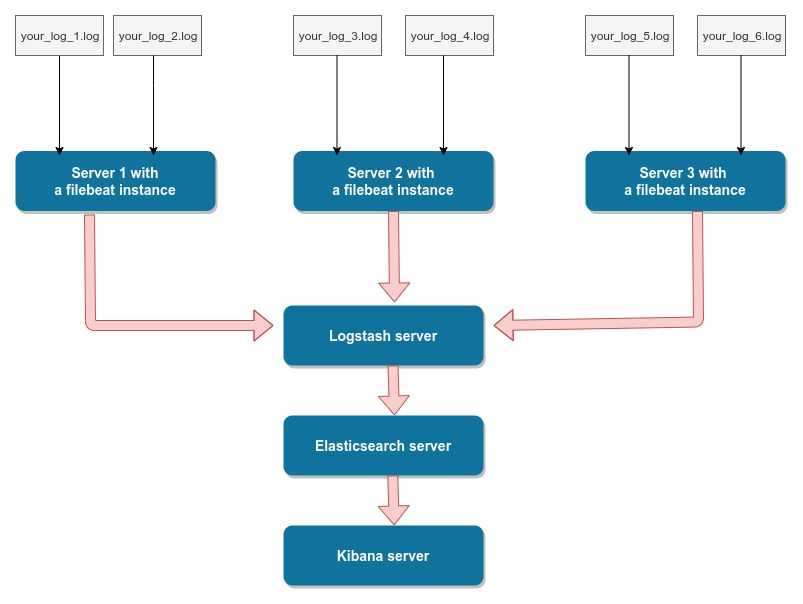

However, as of yet, advanced log enhancement — adding context to the log messages by parsing them up into separate fields, filtering out unwanted bits of data and enriching others — cannot be handled without Logstash.
Moreover, for a number of reasons, and especially in medium- and large-sized environments, you will not want to have each Filebeat agent installed on a host sending off data directly into Elasticsearch.
If Elasticsearch is temporarily unavailable, back pressure to disk is not always a good solution as files can get rotated and deleted. Ideally, you would like to control the amount of indexing connections and having too many may result in a high bulk queue, bad responsiveness, and timeouts. Additionally, Elasticsearch maintenance work that necessitates the pausing of indexing — during upgrades, for example — becomes much more complicated.
So, in most cases, you will be using both Filebeat and Logstash.
Что внутри ELK-системы: архитектура и принципы работы
Инфраструктура ELK включает следующие компоненты :
- Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. Как правило, ES используется в качестве NoSQL-базы данных для приложений со сложными функциями поиска. Elasticsearch основана на библиотеке Apache Lucene, предназначенной для индексирования и поиска информации в любом типе документов. В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер .
- Logstash — средство сбора, преобразования и сохранения в общем хранилище событий из файлов, баз данных, логов и других источников в реальном времени. Logsatsh позволяет модифицировать полученные данные с помощью фильтров: разбить строку на поля, обогатить или их, агрегировать несколько строк, преобразовать их в JSON-документы и пр. Обработанные данные Logsatsh отправляет в системы-потребители.
- Kibana – визуальный инструмент для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в индексах ES. Веб-интерфейс Kibana позволяет быстро создавать и обмениваться динамическими панелями мониторинга, включая таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени. Примечательно, что изначально Kibana была ориентирована на работу с Logstash, а не на Elasticsearch. Однако, с интеграцией 3-х систем в единую ELK-платформу, Kibana стала работать непосредственно с ES .
- FileBeat – агент на серверах для отправки различных типов оперативных данных в Elasticsearch.
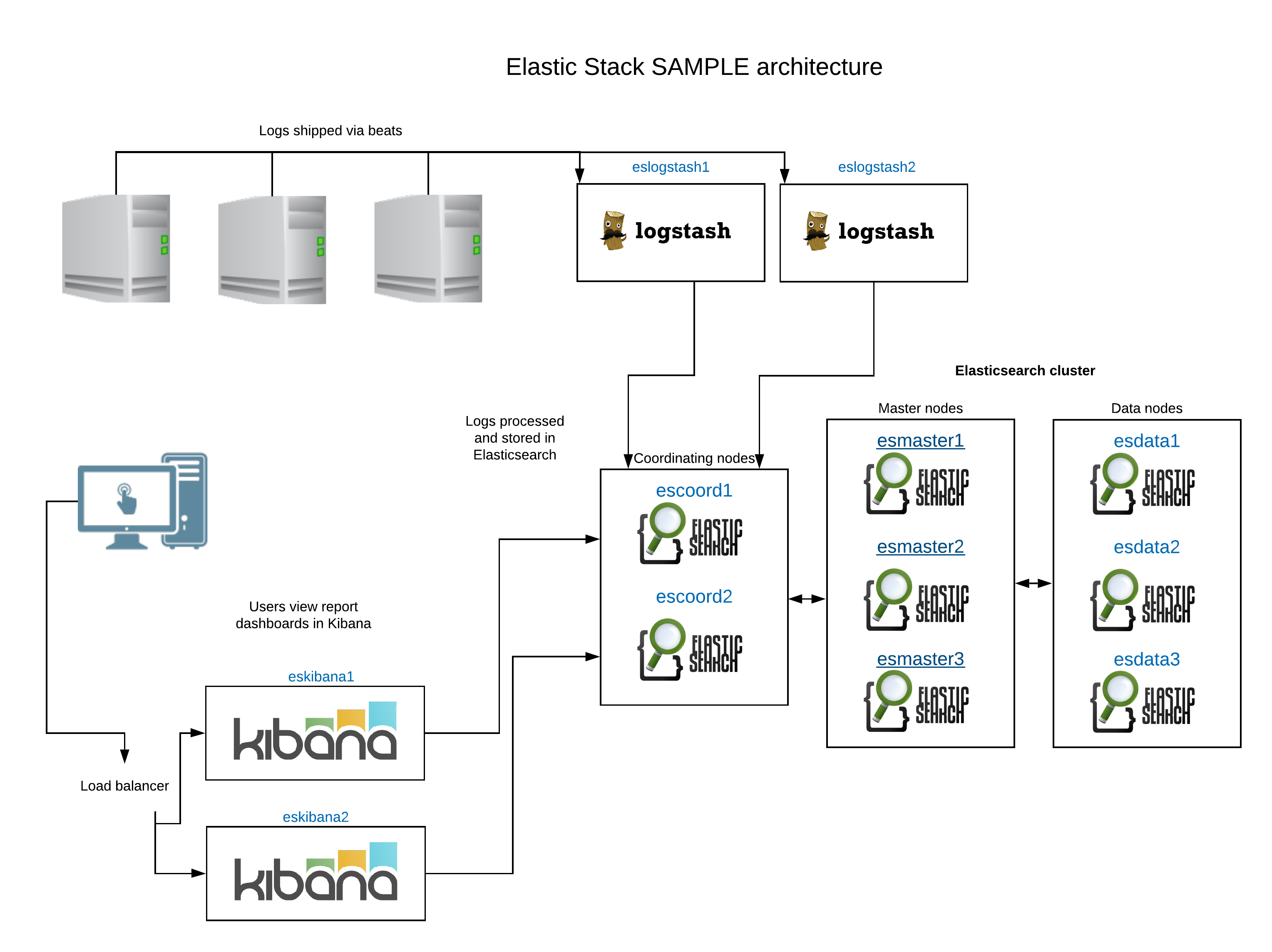
В рамках единой ELK-платформы все вышеперечисленные компоненты взаимодействуют следующим образом :
- Logstash представляет собой конвейер обработки данных (data pipeline) на стороне сервера, который одновременно получает данные из нескольких источников, включая FileBeat. Здесь выполняется первичное преобразование, фильтрация, агрегация или парсинг логов, а затем обработанные данные отправляется в Elasticsearch.
- Elasticsearch играет роль ядра всей системы, сочетая функции базы данных, поискового и аналитического движков. Быстрый и гибкий поиск обеспечивается за счет анализаторов текста, нечеткого поиска, поддержки восточных языков (корейский, китайский, японский). Наличие REST API позволяет добавлять, просматривать, модифицировать и удалять данные .
- Kibana позволяет визуализировать данные ES, а также администрировать базу данных.
![]()
Принцип работы ELK-инфраструктуры: как взаимодействуют Elasticsearch, Logstash и Kibana
Завтра мы рассмотрим главные достоинства и недостатки ELK-инфраструктуры. А как эффективно использовать их для сбора и анализа больших данных в реальных проектах, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://www.softlab.ru/blog/technologies/5816/
- https://ru.bmstu.wiki/Elastic_Logstash
- https://system-admins.ru/elk-o-chem-i-zachem/
- http://samag.ru/archive/article/3575
Подготовка сервера
Прежде чем начать, подготовим к установке и настройке наш сервер.
1. Установка wget
В процессе установки пакетов нам понадобиться скачивать установочные файлы. Для этого в системе должен быть установлен wget:
yum install wget
2. Настройка брандмауэра
Открываем порты для работы ELK:
firewall-cmd —permanent —add-port={5044,5601}/tcp
firewall-cmd —reload
где:
- 5044 — порт, на котором слушаем Logstash.
- 5601 — Kibana.
3. SELinux
Отключаем SELinux двумя командами:
setenforce 0
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
* первая команда выключит систему безопасности до перезагрузки сервера, вторая — навсегда.
Установка и настройка Elasticsearch
Elasticsearch — утилита полнотекстового поиска и аналитики данных, позволяющая в режиме реального времени быстро записывать, искать, анализировать большие объемы данных.
Во-первых, обновим репозитории:
sudo apt update
| 1 | sudo apt update |
И установим Elasticsearch:
sudo apt install elasticsearch
| 1 | sudo apt install elasticsearch |
Для управления Elasticsearch отконфигурируем файл:
sudo nano /etc/elasticsearch/elasticsearch.yml
| 1 | sudo nanoetcelasticsearchelasticsearch.yml |
Необходимо найти и расскоментировать следующие строки:
network.host: localhost
| 1 | network.hostlocalhost |
http.port: 9200
| 1 | http.port9200 |
Если необходимо, чтобы Elasticsearch был доступен и для других узлов сети, то для network.host укажите необходимый адрес. Или установите значение 0.0.0.0 — для доступа со всех адресов сетевых интерфейсов.
![]() Т.к. настраиваем одноузловой кластер, то чуть ниже добавим строку:
Т.к. настраиваем одноузловой кластер, то чуть ниже добавим строку:
discovery.type: single-node
| 1 | discovery.typesingle-node |
Зададим начальный и максимальный размер памяти в куче (JVM heap size), используя -Xms и -Xmx соответственно. Рекомендуется устанавливать их не более чем на половину размера вашей общей памяти:
![]() Запустим Elasticsearch:
Запустим Elasticsearch:
sudo systemctl start elasticsearch.service
| 1 | sudo systemctl start elasticsearch.service |
Для автозапуска Elasticsearch после перезагрузки системы введем команду:
sudo systemctl enable elasticsearch.service
| 1 | sudo systemctl enable elasticsearch.service |
Чтобы протестировать работоспосбность Elasticsearch воспользуемся curl-командой:
curl localhost:9200
| 1 | curl localhost9200 |
Установка Java
Все программные продукты стека ELK разработаны на Java, поэтому не будут работать без соответствующей платформы на сервере. Для ее установки необходимо загрузить дистрибутив с сайта Oracle и выполнить его установку.
Переходим на страницу загрузки Java — на открывшейся странице принимаем лицензионное соглашение:
![]()
После появятся ссылки на платформу — кликаем по ссылке для скачивания RPM пакета:
![]()
Нас перебросит на страницу ввода логина и пароля — необходимо авторизоваться или зарегистрироваться. После начнется процесс загрузки пакета, и когда он завершится, перекидываем файл на сервер CentOS, например, при помощи WinSCP.
Если у нас нет аккаунта на портале Oracle и нет возможности его зарегистрировать, то можно скачать более раннюю версию java командой:curl -L -C — -b «oraclelicense=accept-securebackup-cookie» -O ‘http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.rpm’
Устанавливаем скачанный пакет командой:
rpm -ivh jdk-*
После окончания установки можно ввести команду:
java -version
Она должна вернуть, примерно, следующее:
openjdk version «1.8.0_212»
OpenJDK Runtime Environment (build 1.8.0_212-b04)
OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
Logspout + ELK собирать логи
2.1 Установка Docker ELK
- файл конфигурации logstash
Объяснение конфигурации: конфигурация logstash разделена на три части:
- input: input, то есть поток ввода файла, который может быть передан через tcp, udp или может быть получен только из каталога. Конфигурация файла заключается в чтении содержимого указанного каталога (здесь не настраивается); конфигурация tcp зависит от разных машин logspout нужно проталкивать логи через tcp;
- filter: фильтрация; gork конвертирует нестандартные журналы в стандартизованные
- output: output, вы можете указать индекс вывода
- Настроить файл docker compose лося
- Установить образ ELK использоватьКоманда построить зеркало; Процесс сборки может завершиться неудачно, и его придется повторить несколько раз; Запустить и использовать
2.2 Установите logspout
- Установите logspout на другие машины
Среди них используйте syslog + tcp для отправки собранных файлов журнала в logstash;
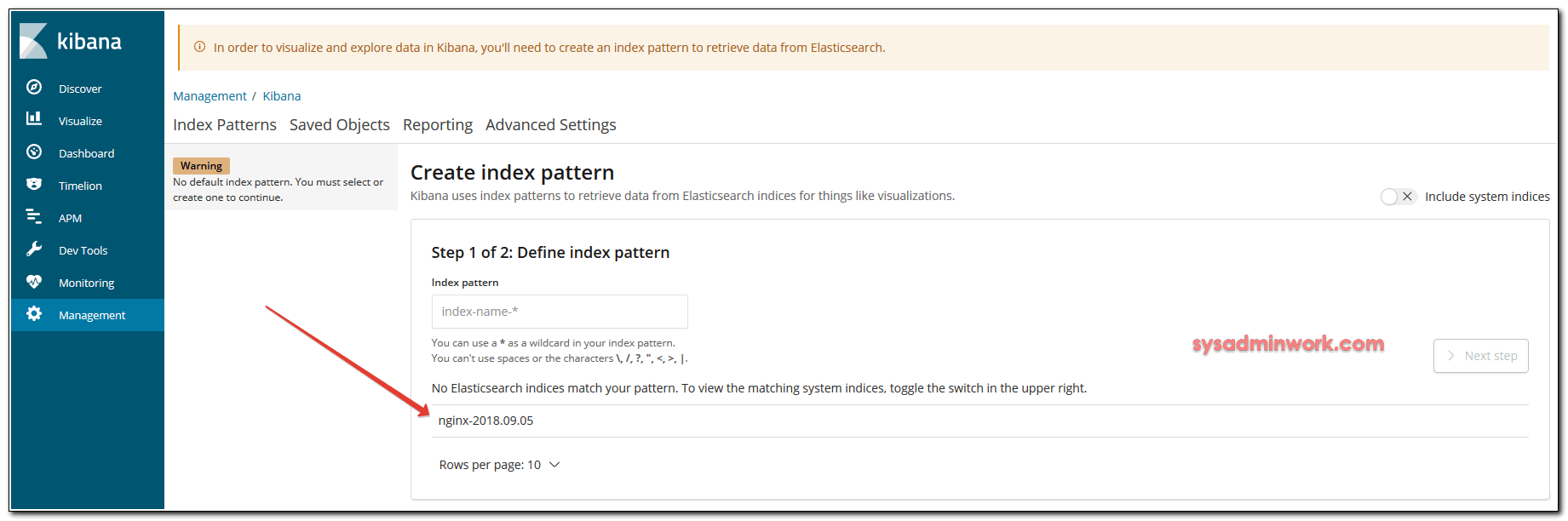
- Вид интерфейса Посещение:http: // ip хоста kibana: 5601 / Вы можете увидеть интерфейс кибаны; Для первого посещения вам необходимо создать индекс: Если в elasticsearch есть индекс, он будет таким, как показано на рисунке ниже, введите logstash- * в поле ввода имени индекса и нажмитеКнопку, выберите, А затем щелкните Создать указатель, а затем щелкните в строке менюВы увидите информацию журнала: (ps: разные версии, интерфейс, который вы видите, может отличаться)
- Укажите контейнер для сбора logspout по умолчанию собирает журналы всех контейнеров на хосте. Однако иногда нам нужно собирать журналы только некоторых контейнеров. Есть два способа решить эту проблему:
Когда каждый контейнер запускается, добавьте переменные средыLOGSPOUT=ignore, Такие как настройки в ELK выше, официальный пример:
Чтобы указать, какие контейнеры включать при запуске logspout, вы можете обратиться к методу, представленному в официальном документе:https://github.com/gliderlabs/logspout
Я использовал второй метод, изменил файл docker-compose logspout выше и добавил его при отправке сообщения в конце
Контейнер, который должен собирать логи, суффикс нужно задать при запускеПсевдоним, вы можете отслеживать журнал контейнера;
Другие параметры фильтра:
Обратите внимание на формулировку запятой; Если существует несколько пунктов назначения маршрутизации, их можно разделить запятыми
Шаг 3 — Установка и настройка Logstash
Хотя Beats может отправлять данные напрямую в базу данных Elasticsearch, мы рекомендуем использовать для обработки данных Logstash. Это даст вам гибкую возможность собирать данные из разных источников, преобразовывать их в общий формат и экспортировать в другую базу данных.
Установите Logstash с помощью следующей команды:
После установки Logstash вы можете перейти к настройке. Файлы конфигурации Logstash находятся в каталоге . Дополнительную информацию о синтаксисе конфигурации можно найти в справочнике по конфигурации, предоставляемом Elastic. Во время настройки конфигурации в файле полезно рассматривать Logstash как конвейер, принимающий данные на одном конце, обрабатывающий и отправляющий их в пункт назначения (в нашем случае пунктом назначения является Elasticsearch). Конвейер Logstash имеет два обязательных элемента, и , а также необязательный элемент . Плагины ввода потребляют данные источника, плагины фильтра обрабатывают данные, а плагины вывода записывают данные в пункт назначения.
![]()
Создайте файл конфигурации с именем , где вы настроите ввод данных Filebeat:
Вставьте следующую конфигурацию . В ней задается ввод , который прослушивает порт TCP .
/etc/logstash/conf.d/02-beats-input.conf
Сохраните и закройте файл.
Создайте файл конфигурации с именем :
Вставьте следующую конфигурацию . Этот вывод настраивает Logstash для хранения данных Beats в Elasticsearch, запущенном на порту , в индексе с названием используемого компонента Beat. В этом обучающем модуле используется компонент Beat под названием Filebeat:
/etc/logstash/conf.d/30-elasticsearch-output.conf
Сохраните и закройте файл.
Протестируйте свою конфигурацию Logstash с помощью следующей команды:
Если ошибок синтаксиса не будет, в выводе появится сообщение через несколько секунд после запуска. Если вы не увидите этого сообщения, проверьте ошибки вывода и обновите конфигурацию для их исправления
Обратите внимание, что вы получите предупреждения от OpenJDK, но они не должны вызывать проблем, и их можно игнорировать
Если тестирование конфигурации выполнено успешно, запустите и активируйте Logstash, чтобы изменения конфигурации вступили в силу:
Теперь Logstash работает нормально и полностью настроен, и мы можем перейти к установке Filebeat.
Step 5 — Exploring Kibana Dashboards
Let’s return to the Kibana web interface that we installed earlier.
In a web browser, go to the FQDN or public IP address of your Elastic Stack server. If your session has been interrupted, you will need to re-enter entering the credentials you defined in Step 2. Once you have logged in, you should receive the Kibana homepage:
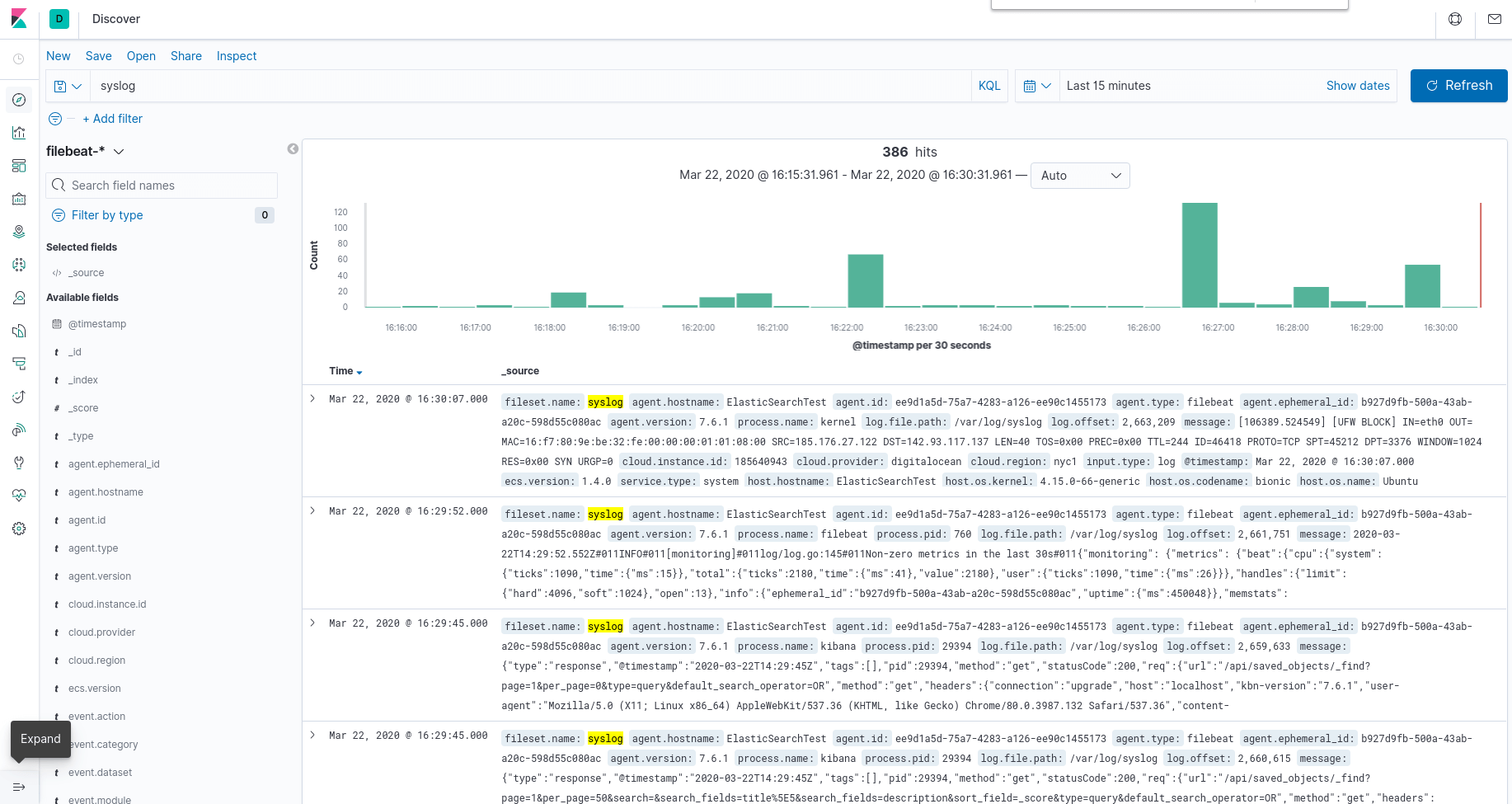
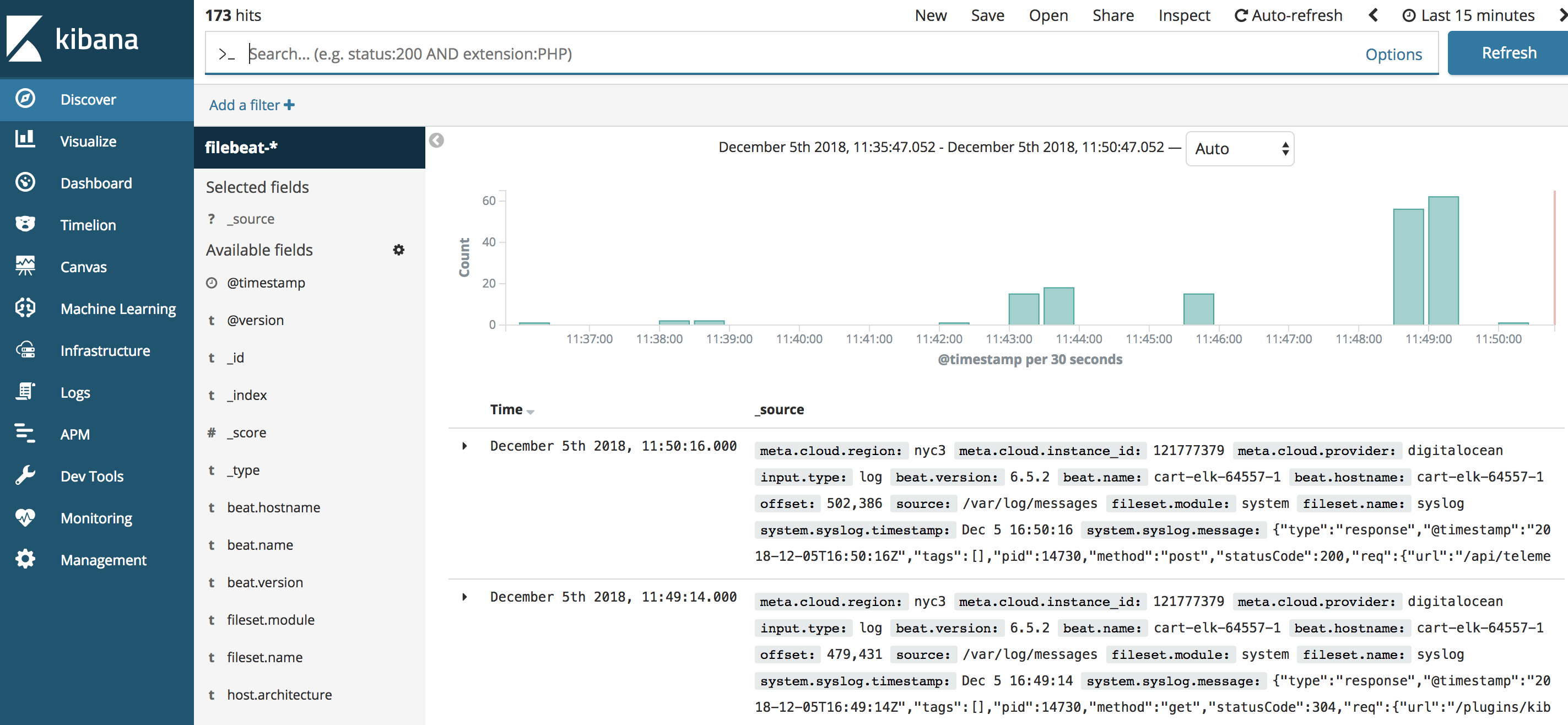
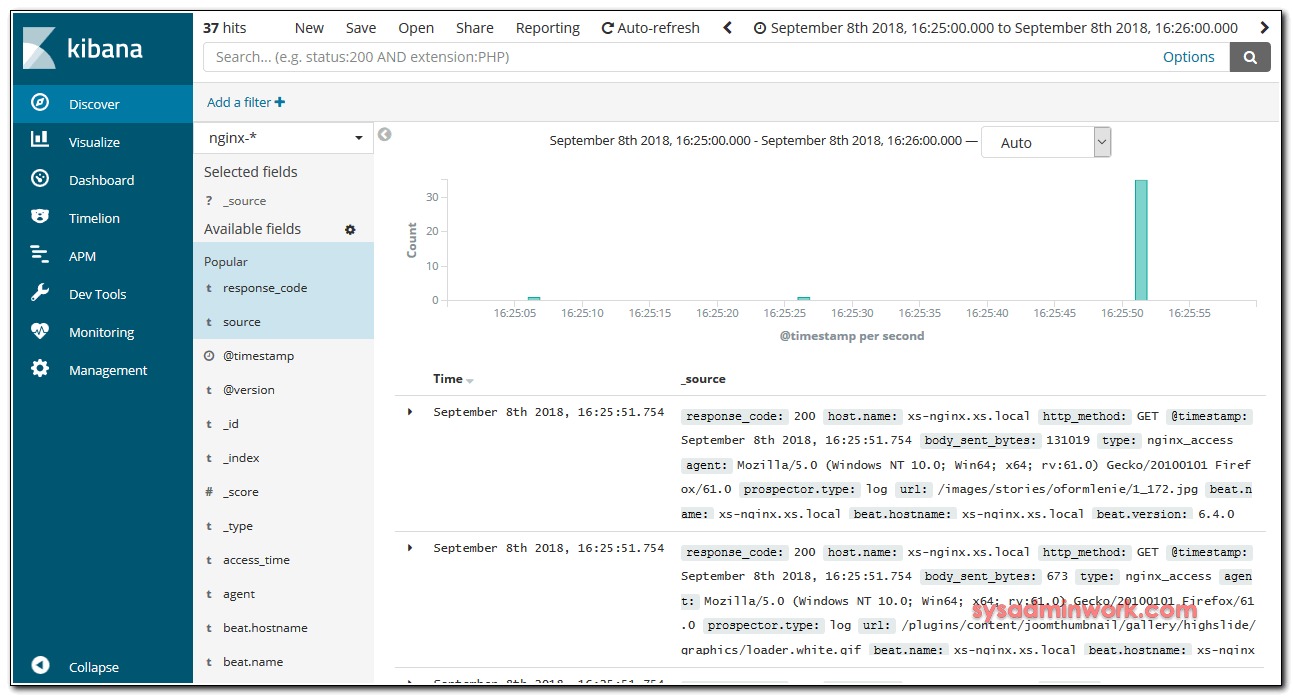
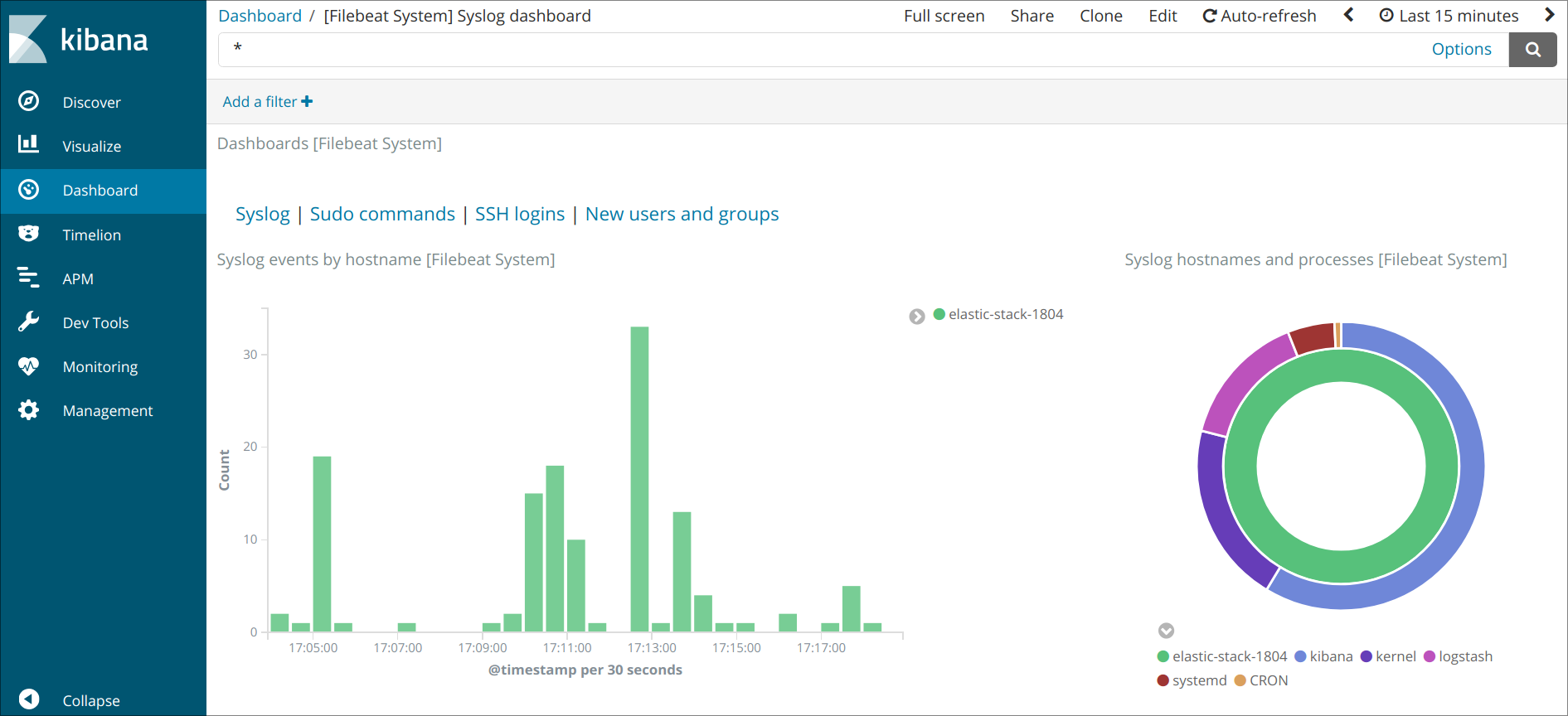
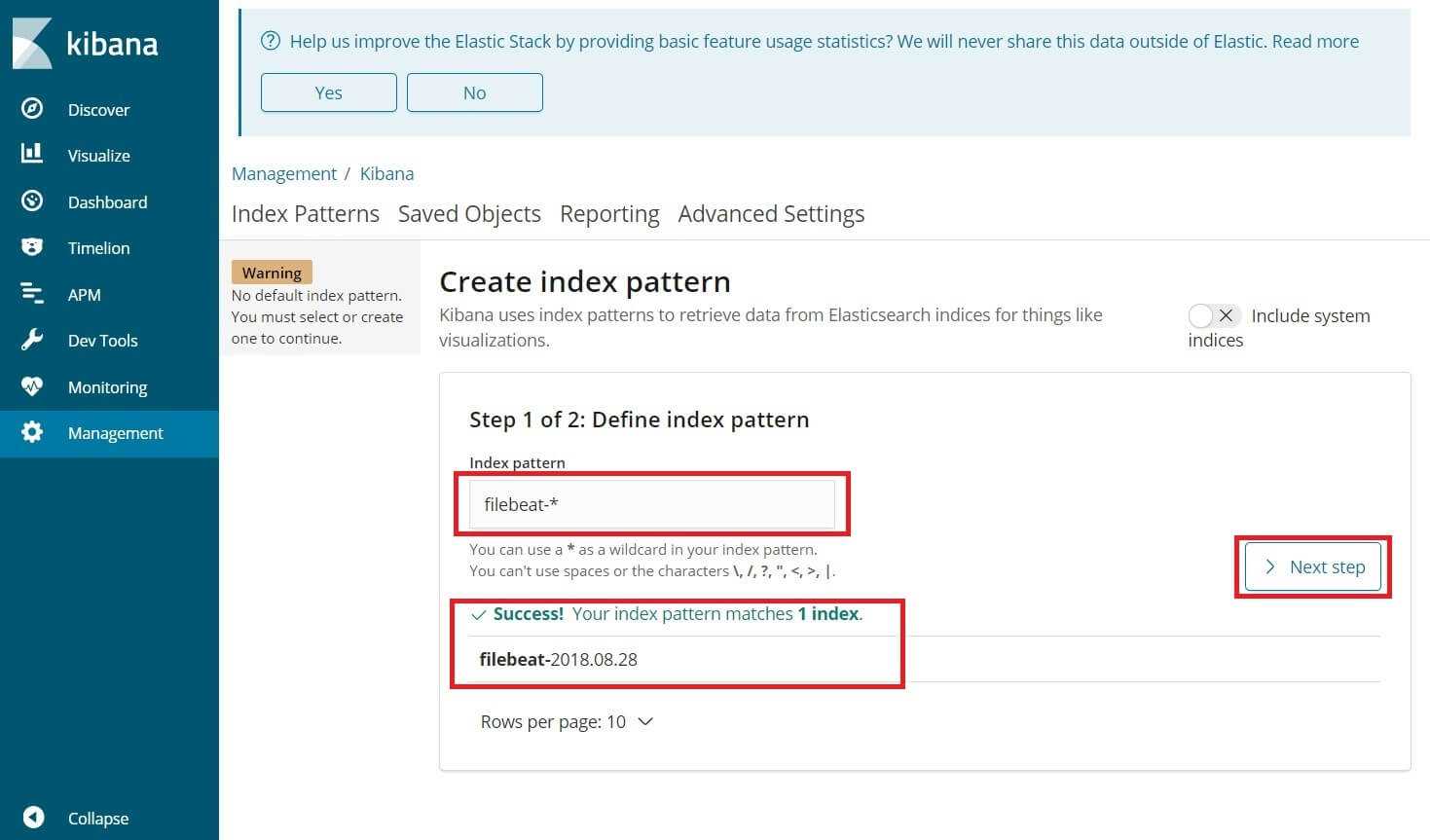
Click the Discover link in the left-hand navigation bar (you may have to click the the Expand icon at the very bottom left to see the navigation menu items). On the Discover page, select the predefined filebeat-* index pattern to see Filebeat data. By default, this will show you all of the log data over the last 15 minutes. You will see a histogram with log events, and some log messages below:
Here, you can search and browse through your logs and also customize your dashboard. At this point, though, there won’t be much in there because you are only gathering syslogs from your Elastic Stack server.
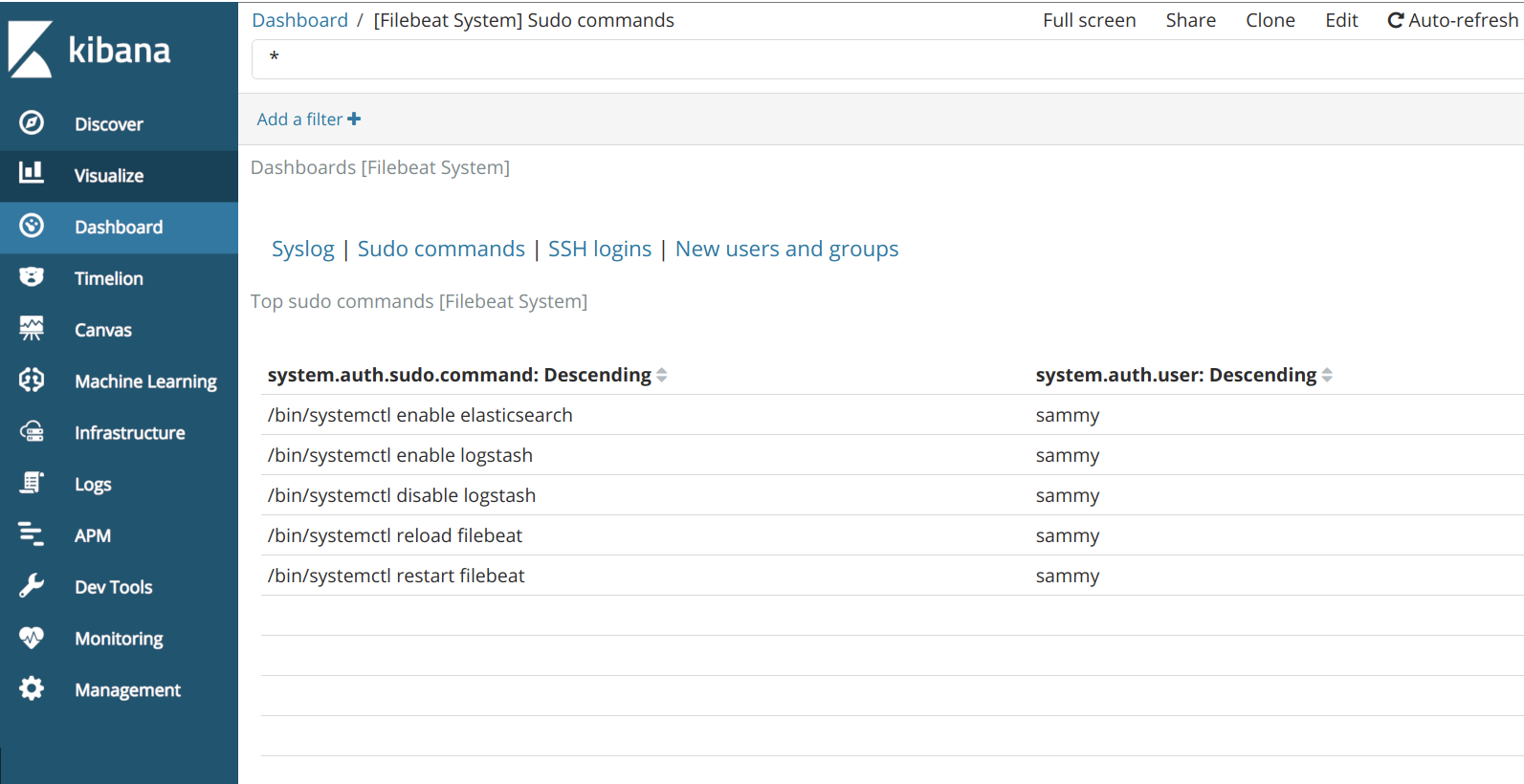
Use the left-hand panel to navigate to the Dashboard page and search for the Filebeat System dashboards. Once there, you can select the sample dashboards that come with Filebeat’s module.
For example, you can view detailed stats based on your syslog messages:
You can also view which users have used the command and when:
Kibana has many other features, such as graphing and filtering, so feel free to explore.
Соберите логи через filebeat в logstash и затем отправьте в ES.
Сначала необходимо установить logstash. После установки создайте новый vi filebeat-pipeline.conf в каталоге установки logstash. Конкретная конфигурация filebeat-pipeline.conf выглядит следующим образом:
Конфигурация ввода означает получение данных ударов через порт 5044. Конфигурация вывода означает вывод в elasticsearch и в то же время вывод на стандартный вывод, которым является консоль. Затем через команду
Запустите logstash с помощью filebeat-pipeline.conf. После запуска вы можете увидеть, что служба порта 5044 журнала запуска logstash была запущена, и вы можете принять данные, передаваемые через filebeat через порт 5044. Затем настройте filebeat Найдите файл filebeat.yml в каталоге установки filebeat, чтобы настроить путь для получения файла журнала и конфигурацию для вывода в logstash. Не выводить напрямую в ES. Конкретная конфигурация выглядит следующим образом: Заблокируйте конфигурацию output.elasticsearch Настройте output.logstash, настройте правильный хост службы и порт logstash. Запустить filebeat для сбора данных журнала
Мы посещаем веб-сервис, предоставляемый сервисом nginx http://172.28.65.32/ В консоли logstash вы можете увидеть соответствующий журнал access.log В то же время вы также можете увидеть соответствующие данные журнала в ES
Заключение
Вот таким относительно простым и эффективным способом можно облегчить управление файловыми серверами, особенно когда их много. Я раньше и представить не мог, что можно так удобно собрать всю информацию с логов и вывести в наглядном виде. А потом еще и фильтровать все это по нужным параметрам практически на лету.
В следующей статье расскажу, как сделать то же самое, только для файловых серверов на windows. Там примерно такой же dashboard будет, но сбор и анализ логов другие.
Онлайн курс по Kubernetes
Онлайн-курс по Kubernetes – для разработчиков, администраторов, технических лидеров, которые хотят изучить современную платформу для микросервисов Kubernetes. Самый полный русскоязычный курс по очень востребованным и хорошо оплачиваемым навыкам. Курс не для новичков – нужно пройти вступительный тест.
Если вы ответите «да» хотя бы на один вопрос, то это ваш курс:
- устали тратить время на автоматизацию?
- хотите единообразные окружения?;
- хотите развиваться и использовать современные инструменты?
- небезразлична надежность инфраструктуры?
- приходится масштабировать инфраструктуру под растущие потребности бизнеса?
- хотите освободить продуктовые команды от части задач администрирования и автоматизации и сфокусировать их на развитии продукта?
Сдавайте вступительный тест по и присоединяйтесь к новому набору!.