Как вырезать по полю
Команда Cut в основном используется для отображения выбранных полей из каждой строки файлов или стандартного ввода. Если не указан, по умолчанию используется разделитель «TAB».
В приведенных ниже примерах мы будем использовать следующий файл. Все поля разделены вкладками.
test.txt
245:789 4567 M:4540 Admin 01:10:1980 535:763 4987 M:3476 Sales 11:04:1978
Для отображения 1-го и 4-го полей вы должны использовать:
cut test.txt -f 1,3
245:789 M:4540 535:763 M:3476
Или, если вы хотите отобразить с 1-го по 4-е поле:
cut test.txt -f -4
245:789 4567 M:4540 Admin 535:763 4987 M:3476 Sales
Как резать на основе разделителя
Чтобы Cut на основе разделителя, используйте параметр -d, за которым следует разделитель, который вы хотите использовать.
Например, чтобы отобразить 1-е и 3-е поля, используя «:» в качестве разделителя, введите:
cut test.txt -d ':' -f 1,3
245:4540 Admin 01 535:3476 Sales 11
Вы можете использовать любой отдельный символ в качестве разделителя. В следующем примере мы используем символ пробела в качестве разделителя и печатаем 2-е поле:
echo "Lorem ipsum dolor sit amet" | cut -d ' ' -f 2
ipsum
Как дополнить выбор
Для дополнения списка полей выбора используйте опцию –complement. Это напечатает только те поля, которые не выбраны с опцией -f.
Следующая команда напечатает все поля кроме 1-го и 3-го:
cut test.txt -f 1,3 --complement
Опции и их описания с примерами
1. -b (byte, байт): используется для извлечения заданных байтов, номера которых указываются после опции через запятую. Можно указать диапазоны через дефис. Если не указать ничего, команда выдаст ошибку. Символы табуляции и пробелы рассматриваются как символы размером в один байт.
$ cut -b 1,2,3 state.txt Рос Гер Нид Сое Исп
$ cut -b 1-3,5-7 state.txt Росия Герани Нидрла Соеине Испния
echo Россия | cut -b 1,2,3 Рос
Для выбора байтов от заданной позиции до конца строки используется следующая форма:
$ cut -b 1- state.txt Россия Германия Нидерланды Соединенное Королевство Испания
Аналогичным образом можно указать байты от начала строки до заданной позиции:
$ cut -b -3 state.txt Рос Гер Нид Сое Исп
2. -c (column, столбец): используется для вырезания по символам. Это также может быть список символов, указанных через запятую, или диапазон, заданный через дефис. Символы табуляции и пробела интерпретируются как один символ. Номера символов указывать обязательно, иначе команда выдаст ошибку.
$cut -c [(k)-(n)/(k),(n)/(n)] filename
где k – начальный символ, а n – конечный, если они разделены дефисом, либо просто позиции символов, указанные через запятую.
Следующая команда вырезает второй, пятый и седьмой символы строк:
$ cut -c 2,5,7 state.txt ои еаи ира оие сня
А эта команда – выводит первые семь символов каждой строки файла:
$ cut -c 1-7 state.txt Россия Германи Нидерла Соедине Испания
Интервалы от заданной позиции до конца строки и от начала строки до заданной позиции задаются аналогично предыдущей опции:
$ cut -c 1- state.txt Россия Германия Нидерланды Соединенное Королевство Испания
$ cut -c -5 state.txt Росси Герма Нидер Соеди Испан
3. -f (field, поле): опция -с полезна для строк фиксированной длины, однако в большинстве файлов они не встречаются. Вам потребуется вырезать данные по полям, а не по столбцам, чтобы получить нужную информацию. Для этого используется опция -f. Номера полей должны разделяться запятыми. Данная опция не позволяет указывать диапазоны
По умолчанию в качестве разделителя полей используется символ табуляции, но при помощи опции -d можно задать другой разделитель.
Важно: по умолчанию пробел не является разделителем
$cut -d "разделитель" -f (номер поля) файл
В файле state.txt поля разделены пробелами, и если не использовать опцию -d, строки будут выводиться целиком:
$ cut -f 1 state.txt Россия Германия Нидерланды Соединенное Королевство Испания
При помощи опции -d можно задать в качестве разделителя пробел:
$ cut -d " " -f 1 state.txt Россия Германия Нидерланды Соединенное Испания
Было выведено каждое слово до пробела.
4. –complement: используется с другими опциями, например, -f или -c, и инвертирует опции вывода:
$ cut --complement -d " " -f 1 state.txt Россия Германия Нидерланды Королевство Испания
$ cut --complement -c 5 state.txt Росся Гермния Ниделанды Соедненное Королевство Испаия
5. –output-delimiter: По умолчанию разделитель выводимых данных такой же, как указанный в опции -d. Чтобы его изменить, воспользуйтесь опцией –output-delimiter. Следующая команда задает в качестве разделителя вывода символ «%» и выводит 1 и 2 поля с опцией -f:
$ cut -d " " -f 1,2 state.txt --output-delimiter='%' Россия Германия Нидерланды Соединенное%Королевство Испания
6. –version: Выводит информацию о версии команды:
$ cut --version cut (GNU coreutils) 8.26 Packaged by Cygwin (8.26-2) Copyright (C) 2016 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later . This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by David M. Ihnat, David MacKenzie, and Jim Meyering.
7. –help: Выводит справочную информацию.
Примеры использования данного синтаксиса:
- Означает zxcvbn
- Означает количество символов с более нуля (включительно) и одну букву d. Например, ccccccd; cd; или d.
- Означает x или zx
- Означает одну или больше букв c и одну или больше букв d. Например: cd; ccccd; cddddd; или ccccccddddddd.
- Выражение, которое определяет весь текст в строке, на всех строках, включая пустые.
- Маска, задающая все символы на строках с количеством не менее одного символа. Это выражение игнорирует пустые строки.
- Маска для поиска строк, которые начинаются со слова after, а также включают открывающую и закрывающие скобки, причем перед и после открывающей скобки может располагаться произвольное количество символов (в том числе, равное нулю).
- Поиск строк, которые начинаются с символа шарп (удобно для поиска и редактирования комментариев в коде)
- Строки, в конце которых стоит обратный слэш (\).
- Любые буквы или цифры
- (В скобке, установлен также пробел и табуляция) — команда описывает один и более символов, кроме пробела и табуляции. Как правило, такое регулярное выражение соответствует словам.
Знак означает любой текстовый фрагмент, обнаруженный в документе:
$ echo 20381 | sed 's/*/(&)/' (20381)
Без знака « текстовый редактор применил бы регулярное выражение только к первому знаку:
$ echo 20381 | sed 's//(&)/' (2)0381
Рассмотрим практический пример, где необходимо отредактировать алгебраическое выражение, поставив скобки:
x+5467-176=y $ sed 's/*-*/(&)/' mathexpression.txt x+(5467-176)=y
Пример удвоения исходного фрагмента текста с помощью амперсанда
$ echo 701 | sed "s/*/& &/" 701 701
Обратите внимание на то, что выражение ищет совпадения только в первом символе строки. Поэтому, если переставить фрагменты местами, то повторение наблюдаться не будет
$ echo "xyz 701" | sed "s/*/& &/" xyz 701
Чтобы они удваивались, необходимо отредактировать маску замены:
$ echo "xyz qwer 701" | sed "s/*/& &/" xyz qwer 701 701
Перестановка слов местами
Ниже показан пример синтаксиса для редактора Sed, при котором слова в текстовом фрагменте меняются местами.
В этом выражении мы запоминаем две подстроки, а затем выполняем их ротацию.
Удаление повторов
В данном случае соответствует второму слову, а — первому. Маску можно использовать не только в шаблоне для замены, но и в образце для удаления повторяющихся слов.
Например:
Примеры заданий для Crontab
Давайте проверим некоторые примеры crontab для планирования заданий cron.
1. Запускать задания cron каждые 12 часов
Это помогает при регулярных проверках системы или резервном копировании. Чтобы запланировать выполнение задачи каждые 12 часов, введите:
2. Запускать задание cron каждые 5 минут
Иногда вам нужно следить за своей системой каждые n минут. Используйте следующее выражение для выполнения задачи каждые 5 минут.
3. Запускать работу cron каждый день в 2 часа ночи
Ежедневное резервное копирование может быть запланировано на определенное время. Следующее выражение запускает задание cron каждый день в 2 часа ночи.
Чтобы запланировать работу cron каждый день в 2 часа дня, cron использует 24-часовые часы.
7. Пример задания cron для запуска каждую субботу в 1 час ночи
Это поможет вам запустить резервное копирование в субботу в определенное время. Следующее выражение помогает выполнять работу cron каждую субботу в 1 час ночи.

13. Запуск задания cron ежемесячно
Вместо использования 0 0 1 * *, вы можете использовать ярлык с помощью @monthly. Он работает в 00:00 1-го числа месяца. В качестве альтернативы вы можете разместить свой скрипт в /etc/cron.monthly/.
14. Запуск задания cron еженедельно
Вместо использования 0 0 * * mon, вы можете использовать ярлык с помощью @weekly. Он начинается в 00:00 в понедельник. В качестве альтернативы вы можете разместить свой скрипт в файле /etc/cron.weekly/.
15. Запуск задания cron ежедневно
Вместо использования 0 0 * * *, вы можете использовать ярлык с помощью @daily. Это работает каждый день в 00:00. В качестве альтернативы вы можете разместить свой сценарий в файле /etc/cron.daily/.
16. Выполнение задания cron каждый час
Вместо использования 0 */1 * * *, вы можете использовать ярлык с помощью @hourly. Он работает в 0 минут каждый час. В качестве альтернативы вы можете разместить свой скрипт в файле /etc/cron.hourly/.
17. Запуск задания cron при перезагрузке
Для запуска задачи при каждой перезагрузке системы используйте строку @reboot. Скрипт будет выполнен после перезагрузки.
18. Запуск задания для cron каждые 30 секунд
Cron позволяет работать только с минутами. Не существует простого способа запланировать выполнение задания каждые 30 секунд.
Но мы можем использовать обходной путь, увеличив задержку на 30 секунд.
19. Запустите задание cron и перенаправить вывод
Если наш скрипт имеет какой-то вывод, нам, возможно, захочется его увидеть. Для этого можно сохранить его в отдельный файл. Этот пример позволит запускать php-скрипт каждые 3 минуты и перенаправлять вывод в файл.
Обратите внимание что тут используются абсолютные пути, так как мы не определили нашу переменную $PATH
Резервное копирование заданий cron
Для бекапа задач cron, можно использовать следующую команду:
Для бекапа задач cron определенного пользователя:
Чтобы восстановить cron из файла резервной копии, просто используйте:
Фильтр grep
Фильтр снискал известность среди пользователей систем Unix. Наиболее простым сценарием использования фильтра является фильтрация строк текста, содержащих (или не содержащих) определенную подстроку.
$ cat tennis.txt Amelie Mauresmo, Fra Kim Clijsters, BEL Justine Henin, Bel Serena Williams, usa Venus Williams, USA $ cat tennis.txt | grep Williams Serena Williams, usa Venus Williams, USA
Вы можете выполнить эту же задачу без задействования фильтра cat.
$ grep Williams tennis.txt Serena Williams, usa Venus Williams, USA
Одним из наиболее полезных параметров фильтра grep является параметр , который позволяет производить фильтрацию строк без учета регистра.
$ grep Bel tennis.txt Justine Henin, Bel $ grep -i Bel tennis.txt Kim Clijsters, BEL Justine Henin, Bel $
Другим полезным параметром является параметр , который позволяет осуществлять вывод строк, не содержащих заданную строку.
$ grep -v Fra tennis.txt Kim Clijsters, BEL Justine Henin, Bel Serena Williams, usa Venus Williams, USA $
И, конечно же, оба описанных выше параметра могут комбинироваться для фильтрации всех строк без учета регистра и вывода тех из них, которые не содержат заданной строки.
$ grep -vi usa tennis.txt Amelie Mauresmo, Fra Kim Clijsters, BEL Justine Henin, Bel $
При использовании параметра в вывод также будет добавлена одна строка, располагающаяся обнаруженной строки.
paul@debian5:~/pipes$ grep -A1 Henin tennis.txt Justine Henin, Bel Serena Williams, usa
В случае использования параметра в вывод будет добавлена одна строка, располагающаяся обнаруженной строки.
paul@debian5:~/pipes$ grep -B1 Henin tennis.txt Kim Clijsters, BEL Justine Henin, Bel
С помощью параметра (контекст) в вывод может быть добавлена одна строка, находящейся обнаруженной строки, и одна строка, находящаяся нее. Все три параметра (A, B и C) могут быть использованы для вывода произвольного количества дополнительных строк (например, могут быть использованы параметры A2, B4 или C20).
paul@debian5:~/pipes$ grep -C1 Henin tennis.txt Kim Clijsters, BEL Justine Henin, Bel Serena Williams, usa
Фильтр comm
Сравнение потоков данных (или файлов) может быть осуществлено с помощью фильтра . По умолчанию фильтр будет выводить данные в трех столбцах. В данном примере строки Abba, Cure и Queen присутствуют в списках из обоих файлов, строки Bowie и Sweet только в списке из первого файла, а строка Turnet — только в списке из второго файла.
paul@debian5:~/pipes$ cat > list1.txt
Abba
Bowie
Cure
Queen
Sweet
paul@debian5:~/pipes$ cat > list2.txt
Abba
Cure
Queen
Turner
paul@debian5:~/pipes$ comm list1.txt list2.txt
Abba
Bowie
Cure
Queen
Sweet
Turner
Вывод фильтра лучше читается в случае формирования одного столбца. При этом с помощью цифровых параметров должны быть указаны столбцы, содержимое которых не должно выводиться.
paul@debian5:~/pipes$ comm -12 list1.txt list2.txt Abba Cure Queen paul@debian5:~/pipes$ comm -13 list1.txt list2.txt Turner paul@debian5:~/pipes$ comm -23 list1.txt list2.txt Bowie Sweet
Фильтр tr
Вы можете преобразовывать символы с помощью фильтра . В примере ниже показана процедура преобразования всех обнаруженных в потоке данных символов e в символы E.
$ cat tennis.txt | tr 'e' 'E' AmEliE MaurEsmo, Fra Kim ClijstErs, BEL JustinE HEnin, BEl SErEna Williams, usa VEnus Williams, USA
В данном случае мы переводим все буквенные символы в верхний регистр, указывая два диапазона значений.
$ cat tennis.txt | tr 'a-z' 'A-Z' AMELIE MAURESMO, FRA KIM CLIJSTERS, BEL JUSTINE HENIN, BEL SERENA WILLIAMS, USA VENUS WILLIAMS, USA $
А здесь мы преобразовываем все символы новых строк в символы пробелов.
$ cat count.txt один два три четыре пять $ cat count.txt | tr '\n' ' ' один два три четыре пять $
Параметр также может использоваться для преобразования последовательностей из множества заданных символов в один символ.
$ cat spaces.txt
один два три
четыре пять шесть
$ cat spaces.txt | tr -s ' '
один два три
четыре пять шесть
$
Вы можете использовать фильтр даже для ‘шифрования’ текстов с использованием алгоритма .
$ cat count.txt | tr 'a-z' 'nopqrstuvwxyzabcdefghijklm' bar gjb guerr sbhe svir $ cat count.txt | tr 'a-z' 'n-za-m' bar gjb guerr sbhe svir $
В последнем примере мы используем параметр для удаления заданного символа.
paul@debian5:~/pipes$ cat tennis.txt | tr -d e Amli Maursmo, Fra Kim Clijstrs, BEL Justin Hnin, Bl Srna Williams, usa Vnus Williams, USA
Список всех сетевых подключений
Следующая команда с опцией ‘-i‘ показывает список всех сетевых соединений ‘LISTENING & ESTABLISHED’.
# lsof -i COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME rpcbind 1203 rpc 6u IPv4 11326 0t0 UDP *:sunrpc rpcbind 1203 rpc 7u IPv4 11330 0t0 UDP *:954 rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN) avahi-dae 1241 avahi 13u IPv4 11579 0t0 UDP *:mdns avahi-dae 1241 avahi 14u IPv4 11580 0t0 UDP *:58600 rpc.statd 1277 rpcuser 11u IPv6 11862 0t0 TCP *:56428 (LISTEN) cupsd 1346 root 6u IPv6 12112 0t0 TCP localhost:ipp (LISTEN) cupsd 1346 root 7u IPv4 12113 0t0 TCP localhost:ipp (LISTEN) sshd 1471 root 3u IPv4 12683 0t0 TCP *:ssh (LISTEN) master 1551 root 12u IPv4 12896 0t0 TCP localhost:smtp (LISTEN) master 1551 root 13u IPv6 12898 0t0 TCP localhost:smtp (LISTEN) sshd 1834 root 3r IPv4 15101 0t0 TCP 192.168.0.2:ssh->192.168.0.1:conclave-cpp (ESTABLISHED) httpd 1918 root 5u IPv6 15991 0t0 TCP *:http (LISTEN) httpd 1918 root 7u IPv6 15995 0t0 TCP *:https (LISTEN) clock-app 2362 narad 21u IPv4 22591 0t0 TCP 192.168.0.2:45284->www.gov.com:http (CLOSE_WAIT) chrome 2377 narad 61u IPv4 25862 0t0 TCP 192.168.0.2:33358->maa03s04-in-f3.1e100.net:http (ESTABLISHED) chrome 2377 narad 80u IPv4 25866 0t0 TCP 192.168.0.2:36405->bom03s01-in-f15.1e100.net:http (ESTABLISHED)
Указание количества символов для сравнения
По аналогии с пропуском символов, вы можете сообщить утилите uniq о необходимости сравнения лишь заданного количества символов строк. Для этой цели вам придется использовать параметр командной строки .
$ uniq -w
Например, предположим, что файл содержит следующие строки:
Теперь при необходимости ограничения диапазона символов строк для сравнения тремя первыми символами, может использоваться следующая команда:
$ uniq -w 3 file1
Это приведенная выше команда в действии:
![]()
Так как первые три символа третьей и четвертой строк совпадают, эти строки считаются утилитой идентичными. По этой причине в выводе находится лишь третья строка.
Синтаксис Crontab
Каждая строка в файле crontab представляет задание. Это задание содержит пять полей, за которыми следует команда или скрипт для выполнения.
Синтаксис:
| * | Минуты | Это значение может быть в пределах 0 — 59 |
| * | Часы | Это значение может быть в пределах 0 — 23 |
| * | День месяца | Это значение может быть в пределах 1 — 31 |
| * | Месяц в году | Это значение поля находится в диапазоне от 1 до 12. Так же можно использовать три первые буквы названия месяца, например: jan, feb, mar |
| * | День недели | Это значение поля находится в диапазоне от 0 до 7. Где 0 и 7-воскресенье. 1-понедельник, 2-вторник и так далее |
Указать несколько значений или диапазон
Для определения нескольких значений или диапазона используйте запятую (,) и дефис (-). Звездочка (*) соответствует чему угодно. Например, для отображения нескольких значений используйте 1,2,3, а для диапазона можно использовать 1-3.
пример:
0 10 1-3 * * /scripts/test.sh
Фильтр od
Несмотря на то, что жители Европы предпочитают работать с символами ascii, компьютеры используют байты для хранения данных файлов. В примере ниже создается простой файл, после чего для показа его содержимого в форме шестнадцатеричных значений байт используется фильтр od.
paul@laika:~/test$ cat > text.txt abcdefg 1234567 paul@laika:~/test$ od -t x1 text.txt 0000000 61 62 63 64 65 66 67 0a 31 32 33 34 35 36 37 0a 0000020
Содержимое этого же файла может быть выведено и в форме восьмеричных значений байт.
paul@laika:~/test$ od -b text.txt 0000000 141 142 143 144 145 146 147 012 061 062 063 064 065 066 067 012 0000020
А это содержимое рассматриваемого файла в форме символов ascii (или экранированных символов).
paul@laika:~/test$ od -c text.txt 0000000 a b c d e f g \n 1 2 3 4 5 6 7 \n 0000020
Исключение пользователя с помощью символа ‘^’
Здесь мы исключили пользователя root. Вы можете исключить любого пользователя, используя команду ‘^‘ как показано выше.
# lsof -i -u^root COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME rpcbind 1203 rpc 6u IPv4 11326 0t0 UDP *:sunrpc rpcbind 1203 rpc 7u IPv4 11330 0t0 UDP *:954 rpcbind 1203 rpc 8u IPv4 11331 0t0 TCP *:sunrpc (LISTEN) rpcbind 1203 rpc 9u IPv6 11333 0t0 UDP *:sunrpc rpcbind 1203 rpc 10u IPv6 11335 0t0 UDP *:954 rpcbind 1203 rpc 11u IPv6 11336 0t0 TCP *:sunrpc (LISTEN) avahi-dae 1241 avahi 13u IPv4 11579 0t0 UDP *:mdns avahi-dae 1241 avahi 14u IPv4 11580 0t0 UDP *:58600 rpc.statd 1277 rpcuser 5r IPv4 11836 0t0 UDP *:soap-beep rpc.statd 1277 rpcuser 8u IPv4 11850 0t0 UDP *:55146 rpc.statd 1277 rpcuser 9u IPv4 11854 0t0 TCP *:32981 (LISTEN) rpc.statd 1277 rpcuser 10u IPv6 11858 0t0 UDP *:55800 rpc.statd 1277 rpcuser 11u IPv6 11862 0t0 TCP *:56428 (LISTEN)
Часто используемые опции
Давайте без долгих предисловий перейдем сразу к делу и изучим наиболее часто используемые опции командной строки.
-b, —bytes=LIST
выбрать из файла только заданные байты согласно списку-c, —characters=LIST
выбрать из файла заданные символы согласно списку-f, —fields=LIST
выбирает только поля, перечисленные в списке. Разделителем по умолчанию служит TAB. Значение по умолчанию может быть переопределено с помощью опции -d.-d, —delimiter=DELIMITER
Позволяет задать разделитель полей. Как уже говорилось выше, значением по умолчанию является TAB, но эта опция позволяет переопределить его.
Options
| -b, —bytes=LIST | Select only the bytes from each line as specified in LIST. LIST specifies a byte, a set of bytes, or a range of bytes; see below. |
| -c, —characters=LIST | Select only the characters from each line as specified in LIST. LIST specifies a character, a set of characters, or a range of characters; see below. |
| -d, —delimiter=DELIM | Use character DELIM instead of a tab for the field delimiter. |
| -f, —fields=LIST | Select only these fields on each line; also print any line containing no delimiter character, unless the -s option is specified. LIST specifies a field, a set of fields, or a range of fields; see below. |
| -n | This option is ignored, but is included for compatibility reasons. |
| —complement | Complement the set of selected bytes, characters or fields. |
| -s, —only-delimited | Do not print lines not containing delimiters. |
| —output-delimiter=STRING | Use STRING as the output delimiter string. The default is to use the input delimiter. |
| —help | Display a help message and exit. |
| —version | Output version information and exit. |
Как обрезать по байтам и символам
Прежде чем идти дальше, давайте проведем различие между байтами и символами.
Один байт составляет 8 бит и может представлять 256 различных значений. Когда был установлен стандарт ASCII, он учитывал все буквы, цифры и символы, необходимые для работы с английским языком. Таблица символов ASCII состоит из 128 символов, и каждый символ представлен одним байтом. Когда компьютеры стали доступны во всем мире, технологические компании начали вводить новые кодировки символов для разных языков. Для языков, содержащих более 256 символов, простое сопоставление 1 к 1 было невозможно. Это приводит к различным проблемам, таким как совместное использование документов или просмотр веб-сайтов, и требовался новый стандарт Unicode, который может обрабатывать большинство мировых систем письма. UTF-8 был создан для решения этих проблем. В UTF-8 не все символы представлены 1 байтом. Символы могут быть представлены от 1 до 4 байтов.
Параметр ( ) указывает команде вырезать разделы из каждой строки, указанной в заданных позициях байтов.
В следующих примерах мы используем символ который занимает 2 байта.
Выберите 5-й байт:
Выберите 5-й, 9-й и 13-й байты:
Выберите диапазон от 1-го до 5-го байта:
На момент написания этой статьи версия входящая в состав GNU coreutils, не имела возможности вырезать по символам. При использовании параметра команда ведет себя так же, как и при использовании параметра .
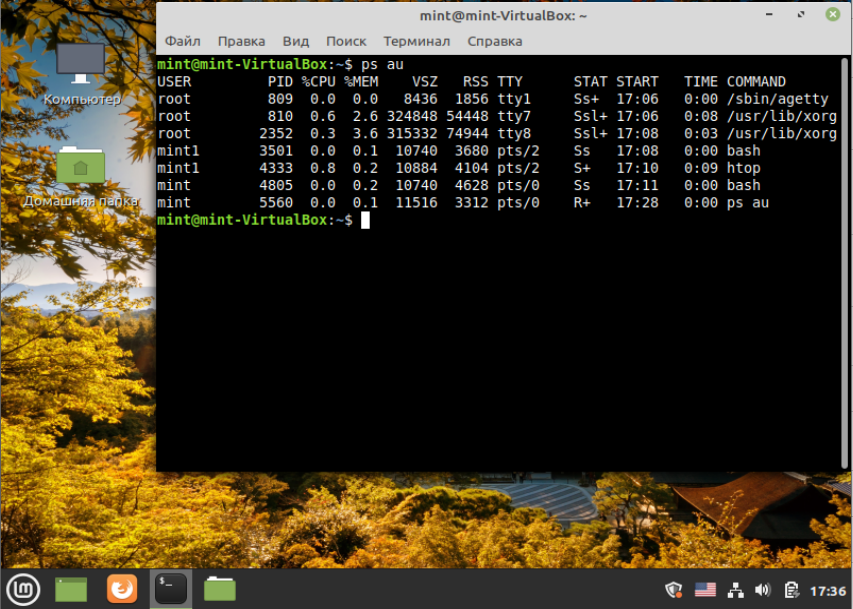
Команда ps в Linux
Сначала рассмотрим общий синтаксис команды, здесь все очень просто:
$ ps опции
$ ps опции | grep параметр
Во втором варианте мы используем утилиту grep для того, чтобы отобрать нужные нам процессы по определенному критерию. Теперь рассмотрим опции утилиты. Они делятся на два типа — те, которые идут с дефисом Unix и те, которые используются без дефиса — BSD. Лучше пользоваться только опциями Unix, но мы рассмотрим и одни и другие. Заметьте, что при использовании опций BSD, вывод утилиты будет организован в BSD стиле.
- -A, -e, (a) — выбрать все процессы;
- -a — выбрать все процессы, кроме фоновых;
- -d, (g) — выбрать все процессы, даже фоновые, кроме процессов сессий;
- -N — выбрать все процессы кроме указанных;
- -С — выбирать процессы по имени команды;
- -G — выбрать процессы по ID группы;
- -p, (p) — выбрать процессы PID;
- —ppid — выбрать процессы по PID родительского процесса;
- -s — выбрать процессы по ID сессии;
- -t, (t) — выбрать процессы по tty;
- -u, (U) — выбрать процессы пользователя.
Опции форматирования:
- -с — отображать информацию планировщика;
- -f — вывести максимум доступных данных, например, количество потоков;
- -F — аналогично -f, только выводит ещё больше данных;
- -l — длинный формат вывода;
- -j, (j) — вывести процессы в стиле Jobs, минимум информации;
- -M, (Z) — добавить информацию о безопасности;
- -o, (o) — позволяет определить свой формат вывода;
- —sort, (k) — выполнять сортировку по указанной колонке;
- -L, (H)- отображать потоки процессов в колонках LWP и NLWP;
- -m, (m) — вывести потоки после процесса;
- -V, (V) — вывести информацию о версии;
- -H — отображать дерево процессов;
Теперь, когда вы знаете синтаксис и опции, можно перейти ближе к практике. Чтобы просто посмотреть процессы в текущей оболочке используется такая команда терминала ps:
Все процессы, кроме лидеров групп, в том же режиме отображения:
Все процессы, включая фоновые и лидеры групп:
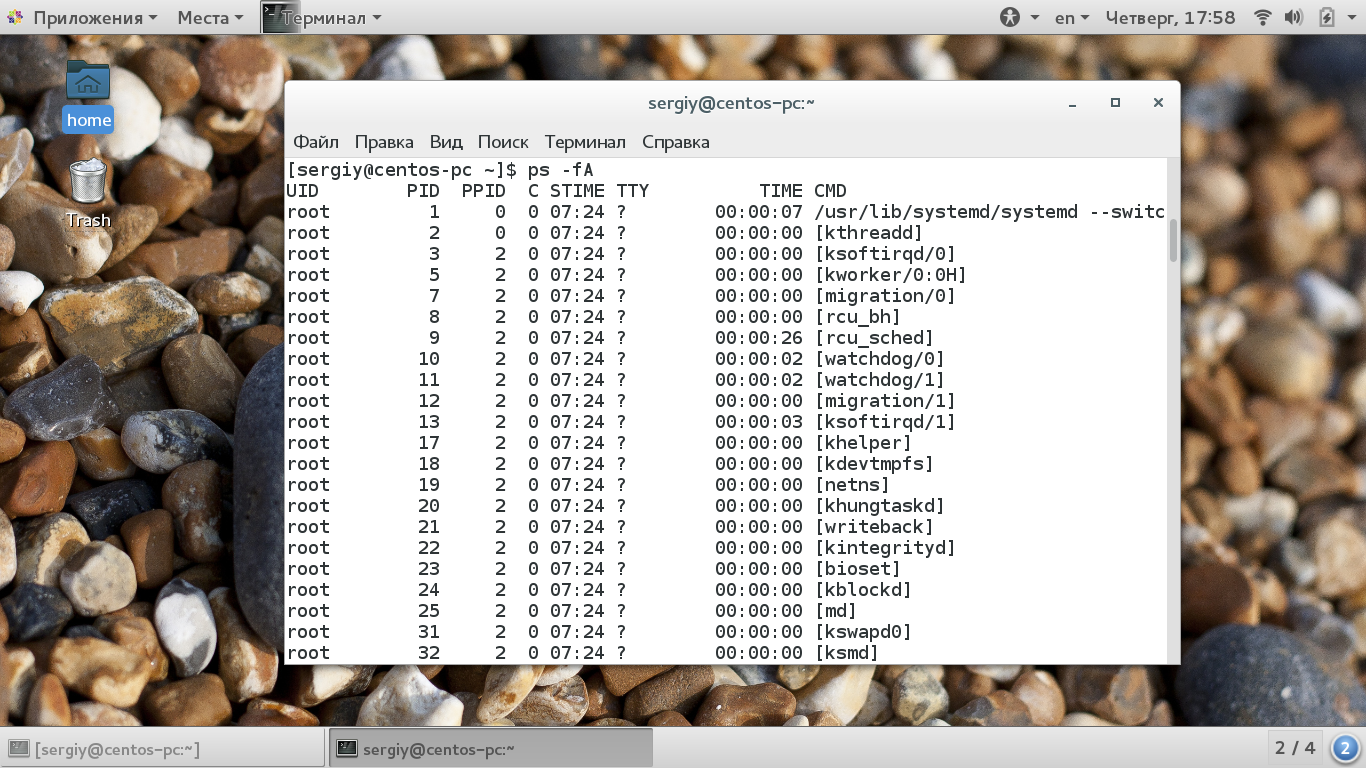
Чтобы вывести больше информации о процессах используйте опцию -f:
При использовании опции -f команда выдает такие колонки:
- UID — пользователь, от имени которого запущен процесс;
- PID — идентификатор процесса;
- PPID — идентификатор родительского процесса;
- C — процент времени CPU, используемого процессом;
- STIME — время запуска процесса;
- TTY — терминал, из которого запущен процесс;
- TIME — общее время процессора, затраченное на выполнение процессора;
- CMD — команда запуска процессора;
- LWP — показывает потоки процессора;
- PRI — приоритет процесса.
Например, также можно вывести подробную информацию обо всех процессах:
Больше информации можно получить, использовав опцию -F:
Эта опция добавляет такие колонки:
- SZ — это размер процесса в памяти;
- RSS — реальный размер процесса в памяти;
- PSR — ядро процессора, на котором выполняется процесс.
Если вы хотите получить еще больше информации, используйте вместо -f опцию -l:
Эта опция добавляет отображение таких колонок:
- F — флаги, ассоциированные с этим процессом;
- S — состояние процесса;
- PRI — приоритет процесса в планировщике ядра Linux;
- NI — рекомендованный приоритет процесса, можно менять;
- ADDR — адрес процесса в памяти;
- WCHAN — название функции ядра, из-за которой процесс находится в режиме ожидания.
Дальше мы можем отобрать все процессы, запущенные от имени определенного пользователя:
С помощью опции -H можно отобразить дерево процессов:
Если вас интересует информация только об определенном процессе, то вы можете использовать опцию -p и указать PID процесса:
Через запятую можно указать несколько PID:
Опция -С позволяет фильтровать процессы по имени, например, выберем только процессы chrome:
Дальше можно использовать опцию -L чтобы отобразить информацию о процессах:
Очень интересно то, с помощью опции -o можно настроить форматирование вывода, например, вы можете вывести только pid процесса и команду:
Вы можете выбрать такие колонки для отображения: pcpu, pmem, args, comm, cputime, pid, gid, lwp, rss, start, user, vsize, priority. Для удобства просмотра можно отсортировать вывод программы по нужной колонке, например, просмотр процессов, которые используют больше всего памяти:
Или по проценту загрузки cpu:
Ещё одна опция — -M, которая позволяет вывести информацию про права безопасности и флаги SELinux для процессов:
Общее количество запущенных процессов Linux можно узнать командой:
Мы рассмотрели все основные возможности утилиты ps. Дальше вы можете поэкспериментировать с её параметрами и опциями чтобы найти нужные комбинации, также можно попытаться применить опции BSD.

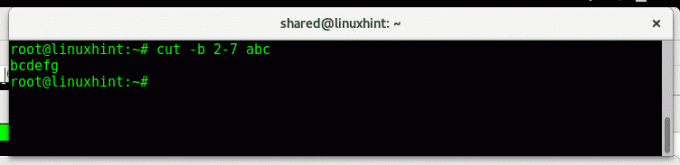
Использование списков
Список (list) в данном случае может состоять из одного или набора байтов, символов или полей. Например, для вывода только второго байта список будет включать единственное число 2.
Поэтому:
2 — будет выведен только второй байт, символ или поле, считая с первого.
2-5 — будут выведены все байты, символы и поля со второго по пятый.
-3 — будут выведены все байты, символы и поля до четвертого.
5- — будут выведены все байты, символы или поля, начиная с пятого.
1,3,6 — будут выведены только первый, третий и шестой байты, символы или поля.
1,3- — будут выведены первый и все байты, символы или поля, начиная с третьего.
Вывод лишь повторяющихся строк
Для того, чтобы утилита uniq выводила лишь повторяющиеся строки, следует использовать параметр командной строки
Например, предположим, что файл с именем файл file1 теперь содержит дополнительную строку в конце (обратите внимание на то, что эта строка не повторяется).
![]()
Теперь при исполнении команды
$ uniq -D file1
будет генерироваться следующий вывод:
![]()
Как вы видите, параметр сообщает утилите uniq о необходимости вывода всех повторяющихся строк, включая их повторы. Для лучшей читаемости вы можете активировать режим вывода пустой строки после каждой из групп повторяющихся строк с помощью параметра .
$ uniq --all-repeated file1
Данный параметр требует от пользователя обязательного указания метода добавления разделителя. Строки могут добавляться к разделителю (то есть, пустой строке) с помощью метода или разделяться с помощью него с помощью метода . Например, в данном случае используется метод .
![]()
Более того, если вам нужно, чтобы утилита выводила лишь по одному экземпляру каждой из повторяющихся строк, вы можете воспользоваться параметром . Это пример его использования:
![]()
Очевидно, что в выводе приводится лишь по одному экземпляру строки из каждой группы.