Настройка iptables для proftpd,vsftpd
-
DROP vs. REJECT
-
nf_conntrack: table full, dropping packet в dmesg
(необходимо изменить ip 192.168.0.1 на ip вашего сервера)
service iptables stop
iptables -A INPUT -p tcp -s 0/0 --sport 1024:65535 -d 192.168.0.1 --dport 21 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -s 192.168.0.1 --sport 21 -d 0/0 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPT iptables -A INPUT -p tcp -s 0/0 --sport 1024:65535 -d 192.168.0.1 --dport 1024:65535 -m state --state ESTABLISHED,RELATED -j ACCEPT iptables -A OUTPUT -p tcp -s 192.168.0.1 --sport 1024:65535 -d 0/0 --dport 1024:65535 -m state --state ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp -s 192.168.0.1 --sport 20 -d 0/0 --dport 1024:65535 -m state --state ESTABLISHED,RELATED -j ACCEPT iptables -A INPUT -p tcp -s 0/0 --sport 1024:65535 -d 192.168.0.1 --dport 20 -m state --state ESTABLISHED -j ACCEPT
(необходимо добавить модуль iptables)
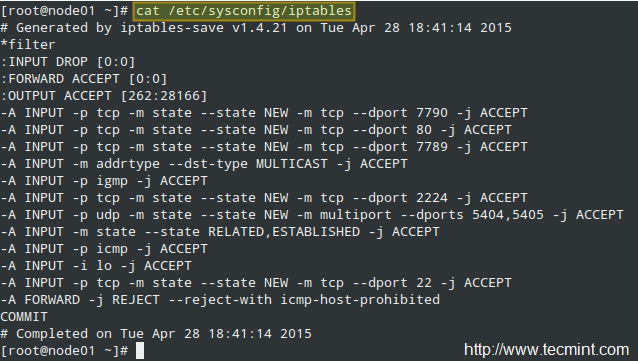
vi /etc/sysconfig/iptables-config
# Load additional iptables modules (nat helpers) # Default: -none- # Space separated list of nat helpers (e.g. 'ip_nat_ftp ip_nat_irc'), which # are loaded after the firewall rules are applied. Options for the helpers are # stored in /etc/modprobe.conf. IPTABLES_MODULES="ip_conntrack_netbios_ns" IPTABLES_MODULES="ip_conntrack_ftp"
service iptables start
данное решение поможет устранить вам ошибку
notice: user : aborting transfer: Data connection closed
iptables -A OUTPUT -p tcp --sport 21 -m state --state ESTABLISHED -j ACCEPT iptables -A OUTPUT -p tcp --sport 20 -m state --state ESTABLISHED,RELATED -j ACCEPT iptables -A OUTPUT -p tcp --sport 1024: --dport 1024: -m state --state ESTABLISHED -j ACCEPT iptables -A INPUT -p tcp --dport 21 -m state --state NEW,ESTABLISHED -j ACCEPT iptables -A INPUT -p tcp --dport 20 -m state --state ESTABLISHED -j ACCEPT iptables -A INPUT -p tcp --sport 1024: --dport 1024: -m state --state ESTABLISHED,RELATED,NEW -j ACCEPT
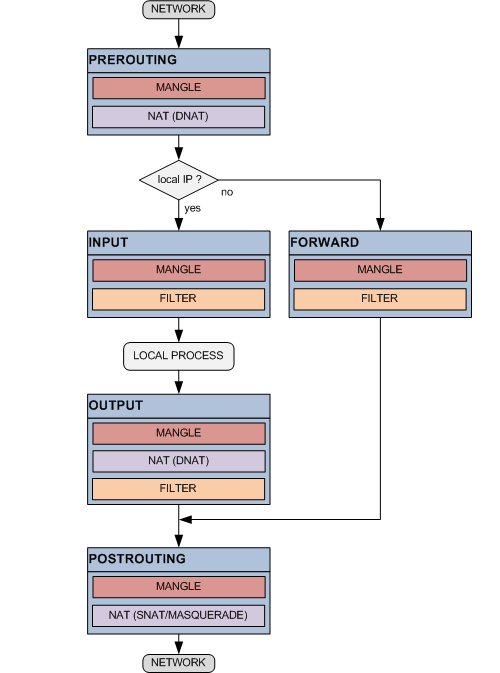
Команды утилиты iptables
Ниже приводится список команд и правила их использования. Посредством команд сообщается iptables, что предполагается сделать. Обычно предполагается одно из двух действий — это добавление нового правила в цепочку или удаление существующего правила из той или иной таблицы. Далее приведены команды, которые используются в iptables.
| Команда | Формат вызова | Результат |
| -A, -append |
iptables -A INPUT |
Добавляет новое правило в конец заданной цепочки. |
|
-D, -delete |
iptables -D INPUT -dport 80 -j DROP, iptables -D INPUT 1 |
Удаление правила из цепочки. Команда имеет два формата записи, первый — когда задается критерий сравнения с опцией -D (см. первый пример), второй — порядковый номер правила. Если задается критерий сравнения, то удаляется правило, которое имеет в себе этот критерий, если задается номер правила, то будет удалено правило с заданным номером. Счет правил в цепочках начинается с 1. |
|
-R, -replace |
iptables -R INPUT 1 -s 192.168.0.1 -j DROP |
Данная команда заменяет одно правило другим. В основном она используется во время отладки новых правил. |
|
-I, -insert |
iptables -I INPUT 1 -dport 80 -j ACCEPT |
Вставляет новое правило в цепочку. Число, следующее за именем цепочки, указывает номер правила, перед которым нужно вставить новое правило, другими словами, число задает номер для вставляемого правила. В примере указывается, что данное правило должно быть 1-м в цепочке INPUT. |
|
-L, -list |
iptables -L INPUT |
Вывод списка правил в заданной цепочке, в данном примере предполагается вывод правил из цепочки INPUT. Если имя цепочки не указывается, то выводится список правил для всех цепочек. Формат вывода зависит от наличия дополнительных ключей в команде, например -n, -v, и пр. |
|
-F, -flush |
iptables -F INPUT |
Удаление всех правил из заданной цепочки (таблицы). Если имя цепочки и таблицы не указывается, то удаляются все правила, во всех цепочках. |
|
-Z, -zero |
iptables -Z INPUT |
Обнуление всех счетчиков в заданной цепочке. Если имя цепочки не указывается, то подразумеваются все цепочки. При использовании ключа -v совместно с командой -L, на вывод будут поданы и состояния счетчиков пакетов, попавших под действие каждого правила. Допускается совместное использование команд -L и -Z. В этом случае будет выдан сначала список правил со счетчиками, а затем произойдет обнуление счетчиков. |
| -N, -new-chain |
iptables -N allowed |
Создается новая цепочка с заданным именем в заданной таблице. В выше приведенном примере создается новая цепочка с именем allowed. Имя цепочки должно быть уникальным и не должно совпадать с зарезервированными именами цепочек и действий (DROP, REJECT и т.п.) |
| -X, -delete-chain |
iptables -X allowed |
Удаление заданной цепочки из заданной таблицы. Удаляемая цепочка не должна иметь правил и не должно быть ссылок из других цепочек на удаляемую цепочку. Если имя цепочки не указано, то будут удалены все цепочки, определенные командой -N в заданной таблице. |
|
-P, -policy |
iptables -P INPUT DROP |
Определяет политику по умолчанию для заданной цепочки. Политика по умолчанию определяет действие, применяемое к пакетам, не попавшим под действие ни одного из правил в цепочке. В качестве политики по умолчанию допускается использовать DROP, ACCEPT и REJECT. |
| -E, -rename-chain |
iptables -E allowed disallowed |
Команда -E выполняет переименование пользовательской цепочки. В примере цепочка allowed будет переименована в цепочку disallowed. Эти переименования не изменяют порядок работы, а носят только косметический характер. |
Команда должна быть указана всегда. Список доступных команд можно просмотреть с помощью команды iptables -h или, что то же самое, iptables -help. Некоторые команды могут использоваться совместно с дополнительными ключами. Ниже приводится список дополнительных ключей и описывается результат их действия.
Настройка iptables для состояний сетевого соединения
При фильтрации сетевых соединений также можно использовать текущий статус сетевых соединений. Давайте немного вспомним, как устанавливается сетевое подключение по протоколу TCP. Сначала инициатор соединения посылает SYN-пакет, сервер принимает его и посылает SYN- и ACK-пакеты, клиент отвечает ACK-пакетом, который принимает сервер, и только после этого соединение считается установленным, и начинается передача данных. Этот обмен пакетами называется хэндшейком или рукопожатием. Мы можем использовать статус сетевого соединения для обеспечения доступа. Например, открывать доступ к определенному порту, если мы с сервера иницировали подключение. В противном случае мы не будем открывать доступ на определенный порт. У сетевых соединений есть несколько статусов состояния, вот некоторые из них:
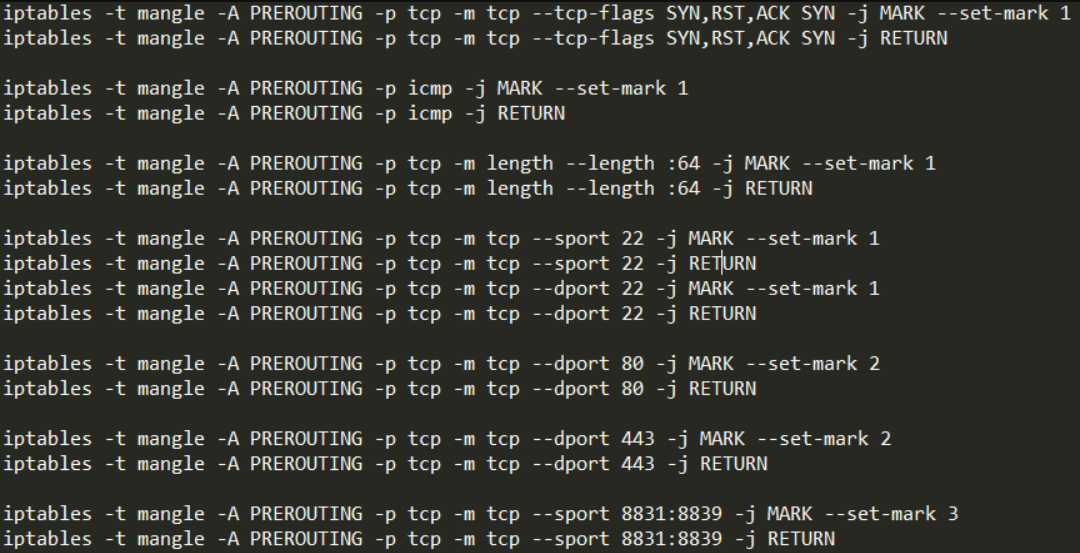
NEW — установка нового соединения, первый пакет, который мы видим.
RELATED — соединение, связанное с другим, имеющим статус ESTABLISHED.
ESTABLISHED — установленное сетевое соединение.
INVALID — пакет не может быть идентифицирован как принадлежащий какому-то соединению.
UNTRACKED — пакеты, для которых ранее была применена цель NOTRACK. Мы пока применяли только цель ACCEPT, позже мы познакомимся и с другими. Для таких пакетов, например, не отслеживаются сопутствующие ICMP-пакеты.
Посылка пакета SYN на определенный порт говорит об установке соединения, если на определенный порт будет послан какой-то другой пакет, это не будет считаться новым соединением, посылка SYN на определенный порт соответствует состоянию NEW. После обмена SYN и ACK пакетами состояние соединения становится ESTABLISHED. Если установленное соединение приводит к открытию другого порта, то это обращение получает статус RELATED.
Очень простой пример — работа с FTP-сервером. Мы подключаемся к порту 21/tcp, в момент подключения соединение получается статус NEW, а затем ESTABLISHED. Управляющие команды идут через порт 21/tcp, но при работе для передачи файлов необходимо открыть еще и 20/tcp. И соединение на порт 20/tcp получает статус RELATED. Таким образом, доступ к порту 20/tcp можно закрывать до тех пор, пока соединение на него не придет со статусом RELATED, либо само соединение не получит статус ESTABLISHED. Получается, что для корректной фильтрации портов 21/tcp и 20/tcp мы можем сделать следующее:
iptables -t filter -A INPUT -p tcp -m tcp --dport 20 -m state --state RELATED,ESTABLISHED -j ACCEPT iptables -t filter -A INPUT -p tcp -m tcp --dport 21 -m state --state NEW,ESTABLISHED -j ACCEPT
В этом случае без установки подключения на порт 21 мы не получим доступ к порту 20. Что необходимо знать для работы со статусами сетевых соединений? Надо представлять себе, как устанавливаются сетевые соединения и представлять, как работает с сетевыми соединениями сервис, для которого вы создаете правила фаервола.
Блокировать/разблокировать запросы ping с помощью iptables
Iptables – это утилита межсетевого экрана в Linux, которая контролирует входящий и исходящий трафик на основе определенных правил. Он предустановлен в системе Ubuntu. Если он отсутствует в системе, вы можете установить его с помощью следующей команды в Терминале:
$ sudo apt install iptables
Блокировать запрос Ping
Чтобы заблокировать запросы ping к вашей системе, введите следующую команду в Терминале:
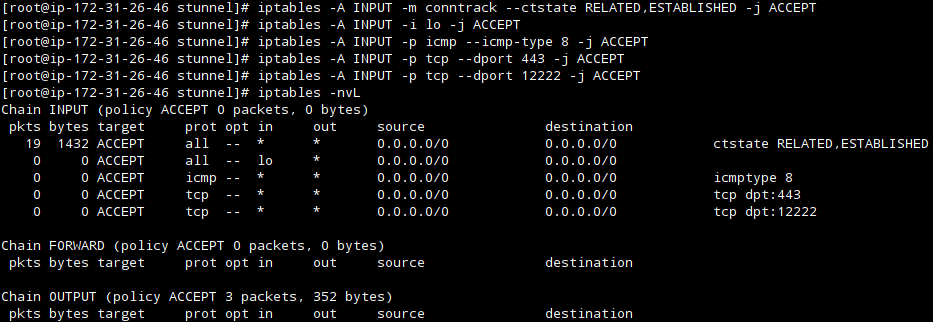
$ sudo iptables -A INPUT -p icmp --icmp-type 8 -j REJECT
Если флаг A используется для добавления правила в iptables, а icmp-type 8 – это номер типа ICMP, используемый для эхо-запроса.
Приведенная выше команда добавит правило в брандмауэр, которое будет блокировать любые входящие запросы ping в вашу систему. Добавив это правило, любой, кто отправит запрос ping в вашу систему, увидит сообщение «Destination Port Unreachable», как показано на снимке экрана ниже.
Если вы не хотите, чтобы это сообщение появлялось, используйте следующую команду, заменив REJECT на DROP:
$ sudo iptables -A INPUT -p icmp --icmp-type 8 -j DROP
Теперь любой, кто отправит запрос ping в вашу систему, увидит следующий аналогичный вывод:
Разблокировать запрос Ping
Чтобы разблокировать ping-запросы к вашему серверу, введите следующую команду в Терминале:
$ sudo iptables -D INPUT -p icmp --icmp-type 8 -j REJECT
Если флаг D используется для удаления правила в iptables, а icmp-type 8 – это номер типа ICMP, используемый для эхо-запроса.
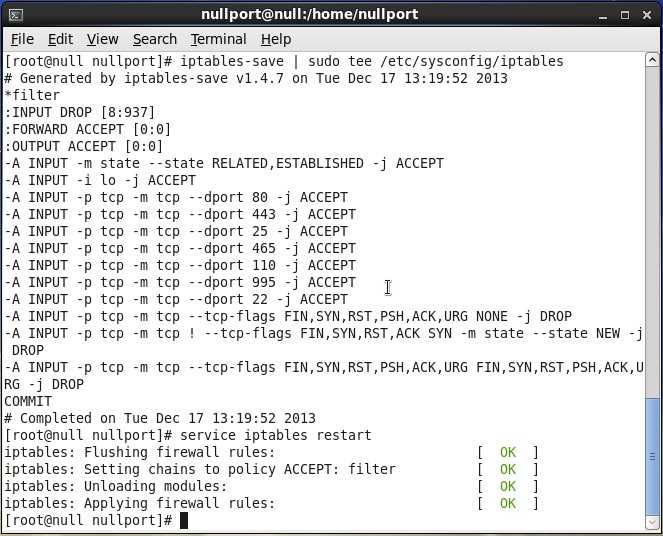
Чтобы эти правила стали постоянными после перезагрузки системы, вам понадобится пакет iptables-persistent. Выполните следующую команду в Терминале, чтобы установить iptables-persistent:
$ sudo apt install iptables-persistent
Вам будет предложено подтвердить, хотите ли вы продолжить установку. Нажмите y, чтобы продолжить, после чего система начнет установку, и после ее завершения она будет готова к использованию.
После добавления или удаления любого правила введите следующие команды в Терминале, чтобы они пережили перезагрузку системы.
$ sudo netfilter-persistent save $ sudo netfilter-persistent reload
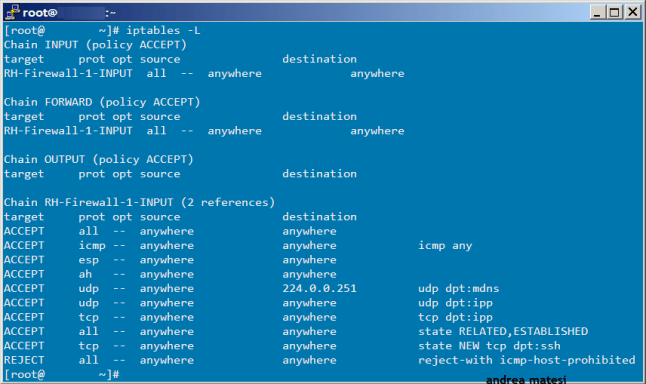
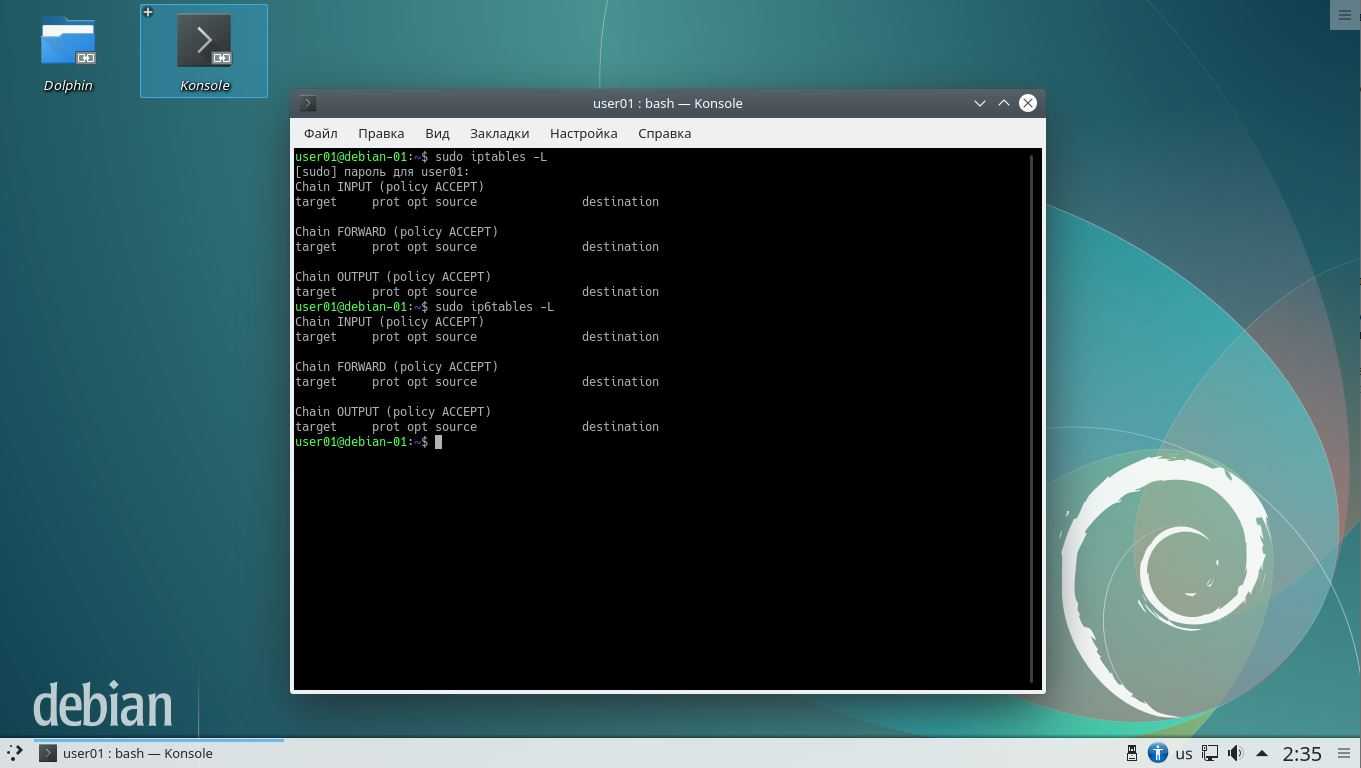
Чтобы просмотреть все правила, добавленные в iptables, введите в Терминале следующую команду:
$ sudo iptables -L
Вот и все! В этой статье мы обсудили, как блокировать/разблокировать ping-запросы к Linux Server либо через параметры ядра, либо через утилиту iptables. Надеюсь это поможет!
Разрешение и блокировка указанных соединений Iptables
Как только политика отношения к трафику настроена, пора приступать к определению правил для конкретных соединений. Мы рассмотрим вариант с отклонением указанного подключения. Способы для разрешения и игнорирования будут устанавливаться похожим методом.
Воспользуемся командой –А. Она позволит добавить новое правило к уже имеющейся цепочке. Межсетевой экран начинает проверку с самого верха, проходя по каждому из правил до тех пор, пока не обнаружит совпадения или не закончит список.
В случае, когда необходимо разместить правила в определенное место (перед каким-то определенным), следует воспользоваться командой:
iptables -I
Видео
https://youtube.com/watch?v=feYZqq7gFrM

Онлайн курс «SRE практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «SRE практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и Linux. Обучение длится 3 месяц, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
На курсе вы узнаете как:
- Внедрить SRE практики в своей организации
- Управлять надежностью, доступностью и эффективностью сервисов
- Управлять изменениями
- Осуществлять мониторинг
- Реагировать на инциденты и производительность
- Работать со следующим технологическим стеком: Linux, AWS, GCP, Kubernetes, Ansible, Terraform, Prometheus, Go, Python.
Проверьте себя на вступительном тесте и смотрите подробнее программу по .
Allowing Incoming Traffic on Specific Ports
You could start by blocking traffic, but you might be working over SSH, where you would need to allow SSH before blocking everything else.
To allow incoming traffic on the default SSH port (22), you could tell iptables to allow all TCP traffic on that port to come in.
sudo iptables -A INPUT -p tcp --dport ssh -j ACCEPT
Referring back to the list above, you can see that this tells iptables:
- append this rule to the input chain (-A INPUT) so we look at incoming traffic
- check to see if it is TCP (-p tcp).
- if so, check to see if the input goes to the SSH port (—dport ssh).
- if so, accept the input (-j ACCEPT).
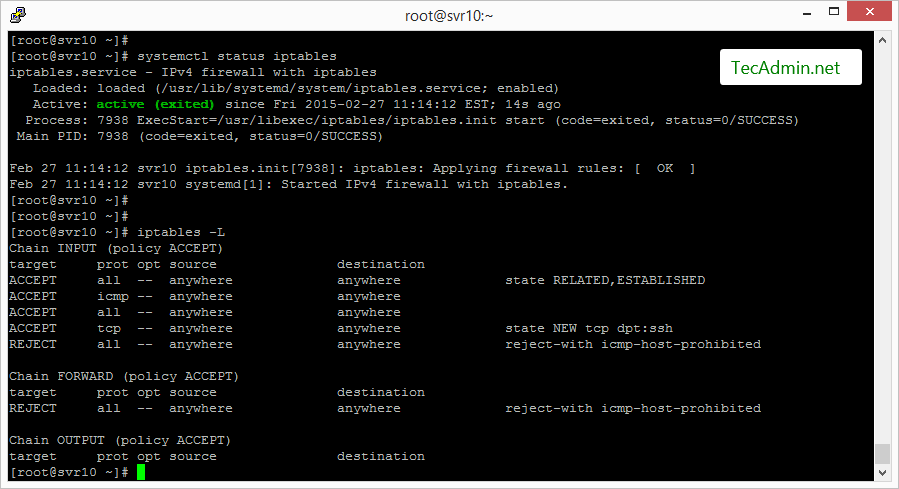
Lets check the rules: (only the first few lines shown, you will see more)
sudo iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED ACCEPT tcp -- anywhere anywhere tcp dpt:ssh
Now, let’s allow all incoming web traffic
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
Checking our rules, we have
sudo iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED ACCEPT tcp -- anywhere anywhere tcp dpt:ssh ACCEPT tcp -- anywhere anywhere tcp dpt:www
We have specifically allowed tcp traffic to the ssh and web ports, but as we have not blocked anything, all traffic can still come in.
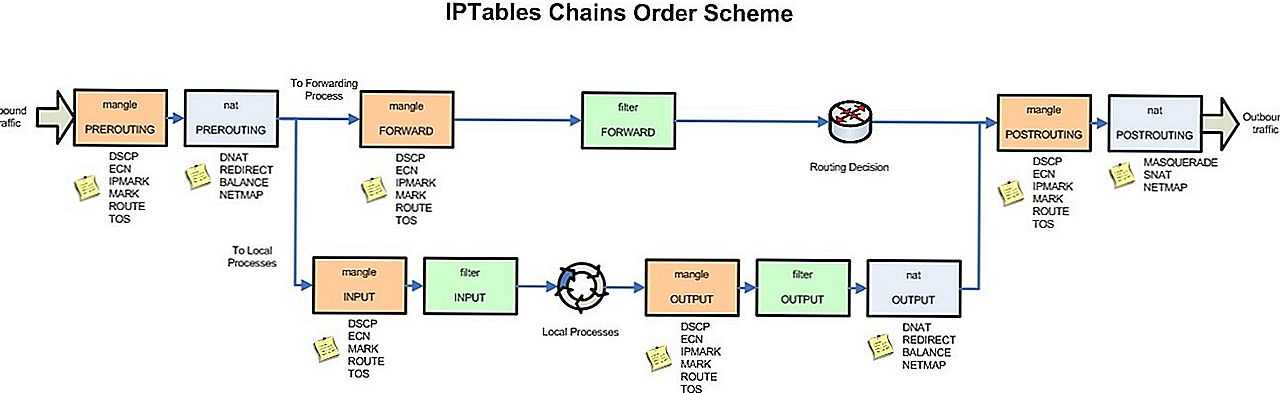
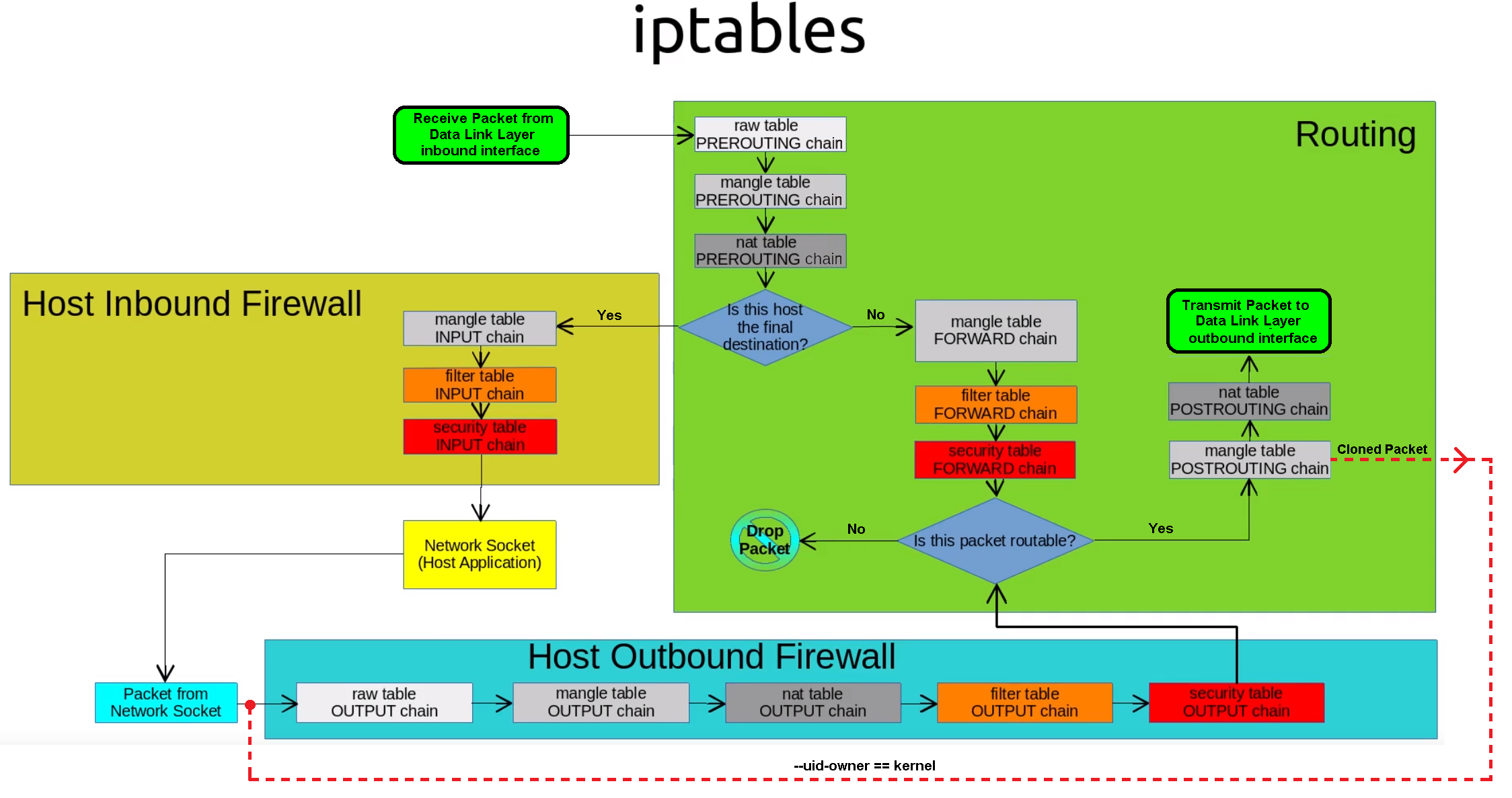
Таблица форвардинга
При настройке iptables мы уже использовали таблицу форвардинга, но единственное, что мы делали — это очищали правила командой
iptables -F FORWARD
В этой таблице не рекомендуется фильтровать трафик, рекомендуется ее использовать только для перенаправления трафика. Фильтрацию необходимо выполнять либо до форвардинга, либо уже после. В таблице FORWARD вы определяете, куда должны форвардиться пакеты, а куда нет. Например:
— разрешить форвардинг между eth0 и eth1
— разрешить форвардинг между eth0 и eth2
— запретить форвардинг между eth1 и eth2
Правила в таком случае могут выглядеть так:
iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT iptables -A FORWARD -i eth1 -o eth0 -j ACCEPT iptables -A FORWARD -i eth0 -o eth2 -j ACCEPT iptables -A FORWARD -i eth2 -o eth0 -j ACCEPT iptables -A FORWARD -i eth1 -o eth2 -j DROP iptables -A FORWARD -i eth2 -o eth1 -j DROP
либо еще короче:
iptables -A FORWARD -i eth1 -o eth2 -j DROP iptables -A FORWARD -i eth2 -o eth1 -j DROP
Настройка NAT (MASQUERADE)
Большинство организаций получает от своих интернет-провайдеров ограниченное количество публично доступных IP-адресов, поэтому администратору требуется разделять доступ к Интернету, не выдавая каждому узлу сети публичный IP-адрес. Для доступа к внутренним и внешним сетевым службам узлы локальной сети используют внутренний (частный) IP-адрес. Граничные маршрутизаторы (межсетевые экраны) могут получать входящие соединения из Интернета и передавать их нужным узлам локальной сети и наоборот, направлять исходящие соединения узлов удаленным интернет-службам. Такое перенаправление сетевого трафика может быть опасным, особенно учитывая доступность современных средств взлома, осуществляющих подмену внутренних IP-адресов и таким образом маскирующих машину злоумышленника под узел вашей локальной сети. Чтобы этого не случилось, в Iptables существуют политики маршрутизации и перенаправления, которые можно применять для исключения злонамеренного использования сетевых ресурсов. Политика FORWARD позволяет администратору контролировать маршрутизацию пакетов в локальной сети. Например, чтобы разрешить перенаправление всей локальной сети, можно установить следующие правила (в примере предполагается, что внутренний IP-адрес брандмауэра/шлюза назначен на интерфейсе eth1):
sudo iptables -A FORWARD -i eth1 -j ACCEPT sudo iptables -A FORWARD -o eth1 -j ACCEPT
Эти правила предоставляют системам за шлюзом доступ к внутренней сети. Шлюз направляет пакеты от узла локальной сети к узлу назначения и наоборот (опции -o и -i), передавая их через устройство eth1.
net.ipv4.ip_forward = 1
Разрешение перенаправления пакетов внутренним интерфейсом брандмауэра позволяет узлам локальной сети связываться друг с другом, но у них не будет доступа в Интернет. Чтобы обеспечить узлам локальной сети с частными IP-адресами возможность связи с внешними публичными сетями, нужно настроить на брандмауэре трансляцию сетевых адресов (NAT). Создадим правило:
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
В этом правиле используется таблица NAT, поэтому она указывается в явном виде (-t nat) и указана встроенная цепочка этой таблицы POSTROUTING для внешнего сетевого интерфейса eth0 (-o eth0). POSTROUTING позволяет изменять пакеты, когда они выходят из внешнего интерфейса шлюза. Целевое действие -j MASQUERADE заменяет (маскирует) частный IP-адрес узла внешним IP-адресом шлюза. Это называется IP-маскарадингом.
Показать статус.
# iptables -L -n -v
Примерный вывод команды для неактивного файрвола:
Chain INPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination
Для активного файрвола:
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 state INVALID
394 43586 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
93 17292 ACCEPT all -- br0 * 0.0.0.0/0 0.0.0.0/0
1 142 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- br0 br0 0.0.0.0/0 0.0.0.0/0
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 state INVALID
0 0 TCPMSS tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp flags:0x06/0x02 TCPMSS clamp to PMTU
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
0 0 wanin all -- vlan2 * 0.0.0.0/0 0.0.0.0/0
0 0 wanout all -- * vlan2 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- br0 * 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 425 packets, 113K bytes)
pkts bytes target prot opt in out source destination
Chain wanin (1 references)
pkts bytes target prot opt in out source destination
Chain wanout (1 references)
pkts bytes target prot opt in out source destination
Где:
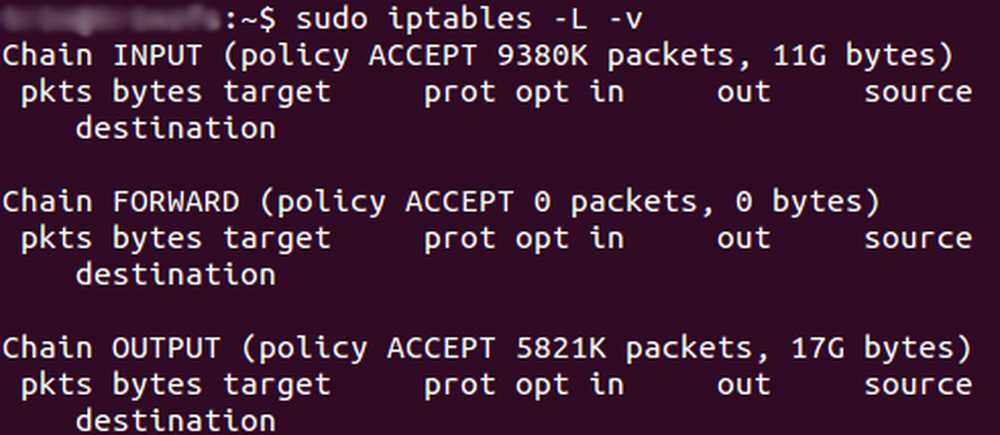
— L : Показать список правил.
— v : Отображать дополнительную информацию. Эта опция показывает имя интерфейса, опции, TOS маски. Также отображает суффиксы ‘K’, ‘M’ or ‘G’.
— n : Отображать IP адрес и порт числами (не используя DNS сервера для определения имен. Это ускорит отображение).
Configuration on startup
WARNING: Iptables and NetworkManager can conflict. Also if you are concerned enough about security to install a firewall you might not want to trust NetworkManager. Also note NetworkManager and iptables have opposite aims. Iptables aims to keep any questionable network traffic out. NetworkManager aims to keep you connected at all times. Therefore if you want security all the time, run iptables at boot time. If you want security some of the time then NetworkManager might be the right choice.
WARNING: If you use NetworkManager (installed by default on Feisty and later) these steps will leave you unable to use NetworkManager for the interfaces you modify. Please follow the steps in the next section instead.
NOTE: It appears on Hardy, NetworkManager has an issue with properly on saving and restoring the iptable rules when using the method in the next section. Using this first method appears to work. If you find otherwise, please update this note.
Save your firewall rules to a file
sudo sh -c "iptables-save > /etc/iptables.rules"
At this point you have several options. You can make changes to /etc/network/interfaces or add scripts to /etc/network/if-pre-up.d/ and /etc/network/if-post-down.d/ to achieve similar ends. The script solution allows for slightly more flexibility.
Solution #1 — /etc/network/interfaces
(NB: be careful — entering incorrect configuration directives into the interface file could disable all interfaces, potentially locking you out of a remote machine.)
Modify the /etc/network/interfaces configuration file to apply the rules automatically. You will need to know the interface that you are using in order to apply the rules — if you do not know, you are probably using the interface eth0, although you should check with the following command first to see if there are any wireless cards:
iwconfig
If you get output similar to the following, then you do not have any wireless cards at all and your best bet is probably eth0.
lo no wireless extensions. eth0 no wireless extensions.
When you have found out the interface you are using, edit (using sudo) your /etc/network/interfaces:
sudo nano /etc/network/interfaces
When in the file, search for the interface you found, and at the end of the network related lines for that interface, add the line:
pre-up iptables-restore < /etc/iptables.rules
You can also prepare a set of down rules, save them into second file /etc/iptables.downrules and apply it automatically using the above steps:
post-down iptables-restore < /etc/iptables.downrules
A fully working example using both from above:
auto eth0 iface eth0 inet dhcp pre-up iptables-restore < /etc/iptables.rules post-down iptables-restore < /etc/iptables.downrules
You may also want to keep information from byte and packet counters.
sudo sh -c "iptables-save -c > /etc/iptables.rules"
The above command will save the whole rule-set to a file called /etc/iptables.rules with byte and packet counters still intact.
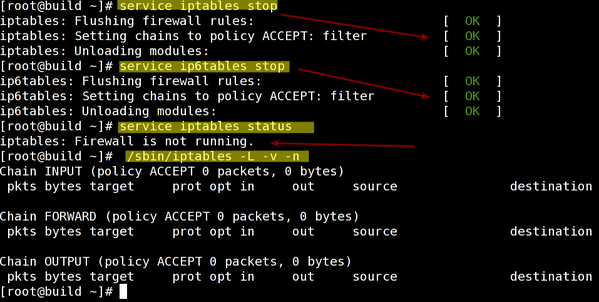
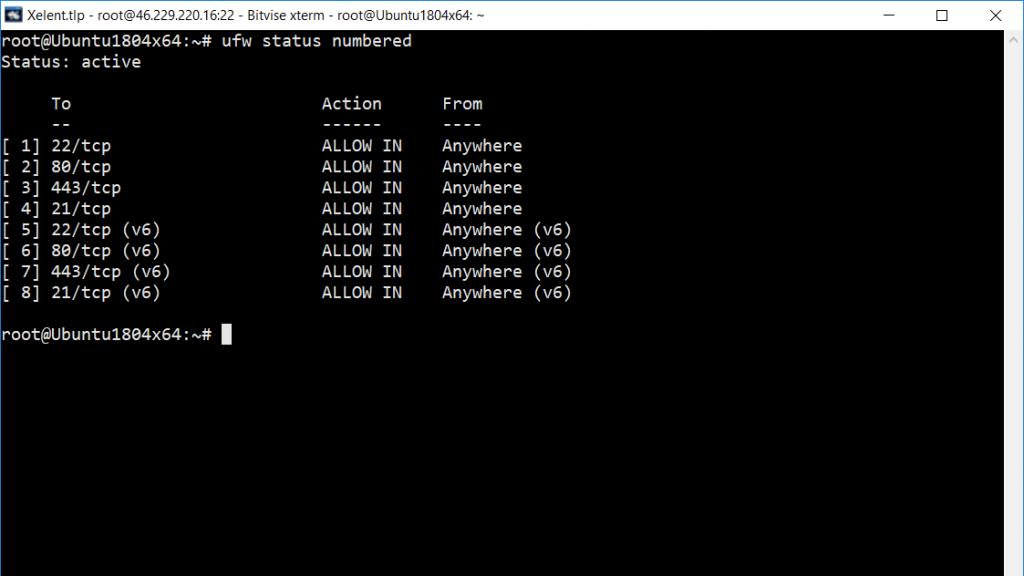
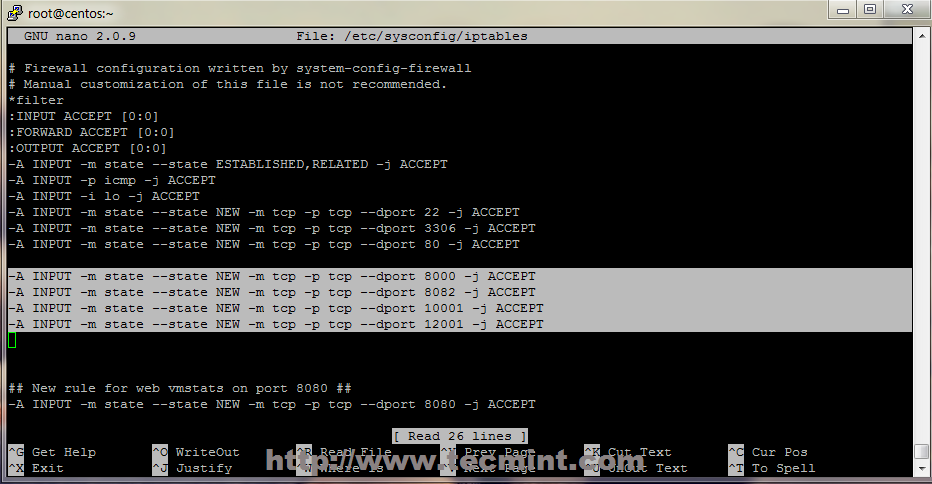
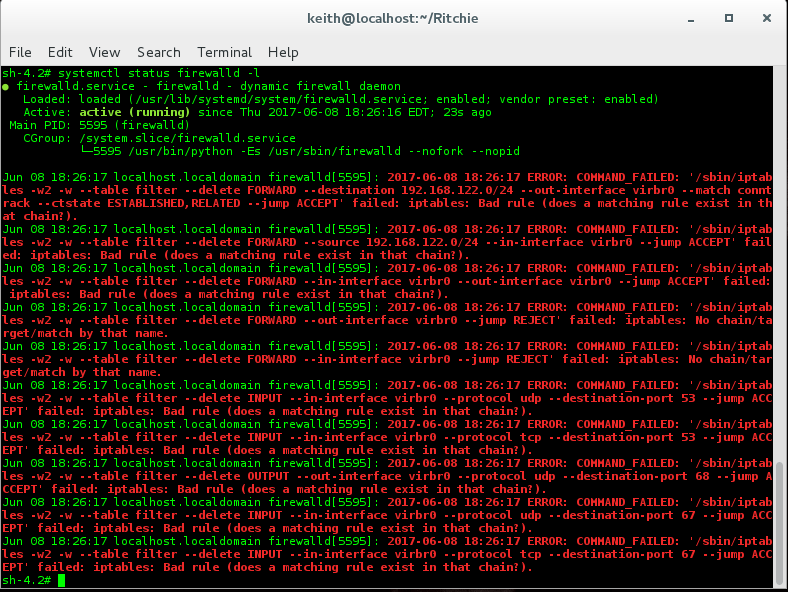
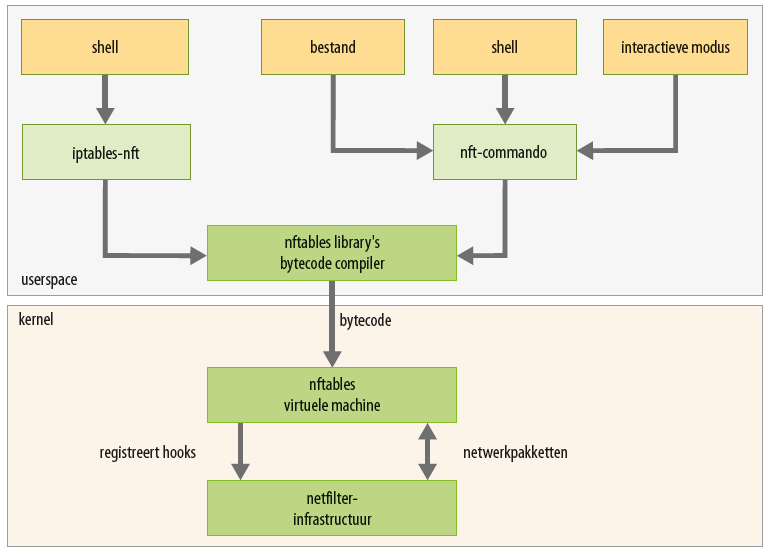
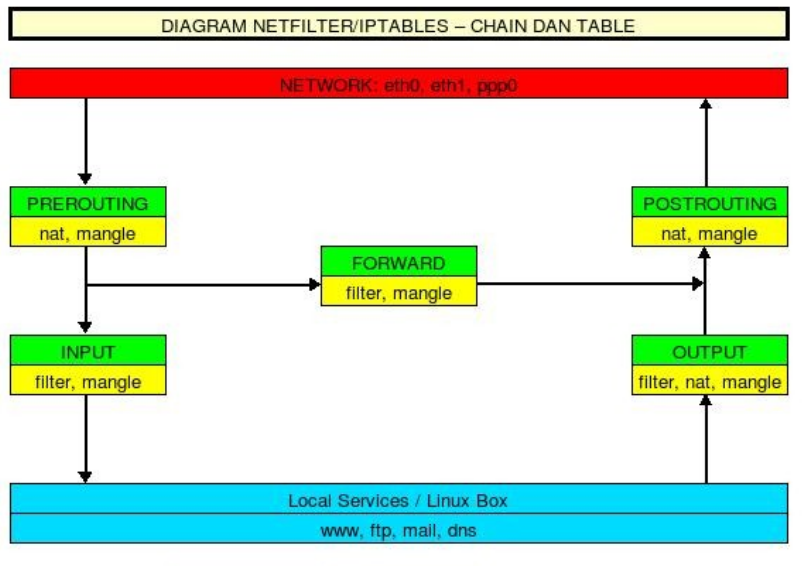
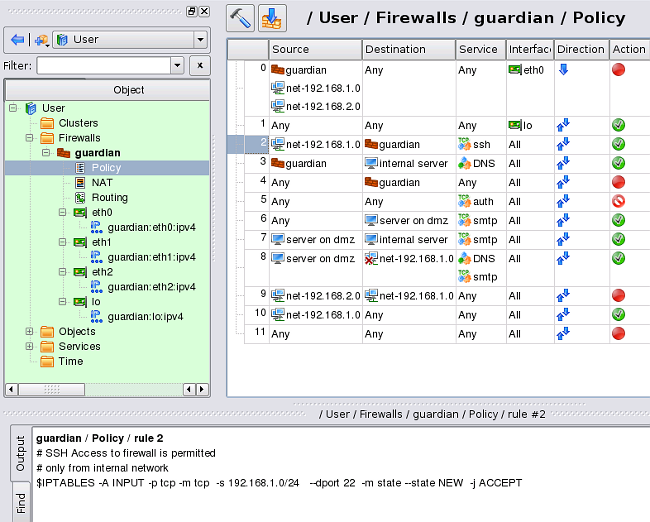
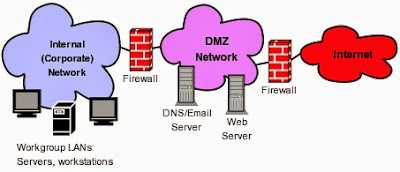
Solution #2 /etc/network/if-pre-up.d and ../if-post-down.d
NOTE: This solution uses iptables-save -c to save the counters. Just remove the -c to only save the rules.
Alternatively you could add the iptables-restore and iptables-save to the if-pre-up.d and if-post-down.d directories in the /etc/network directory instead of modifying /etc/network/interface directly.
NOTE: Scripts in if-pre-up.d and if-post-down.d must not contain dot in their names.
The script /etc/network/if-pre-up.d/iptablesload will contain:
#!/bin/sh iptables-restore < /etc/iptables.rules exit 0
and /etc/network/if-post-down.d/iptablessave will contain:
#!/bin/sh iptables-save -c > /etc/iptables.rules if [ -f /etc/iptables.downrules ]; then iptables-restore < /etc/iptables.downrules fi exit 0
Then be sure to give both scripts execute permissions:
sudo chmod +x /etc/network/if-post-down.d/iptablessave sudo chmod +x /etc/network/if-pre-up.d/iptablesload





