Введение
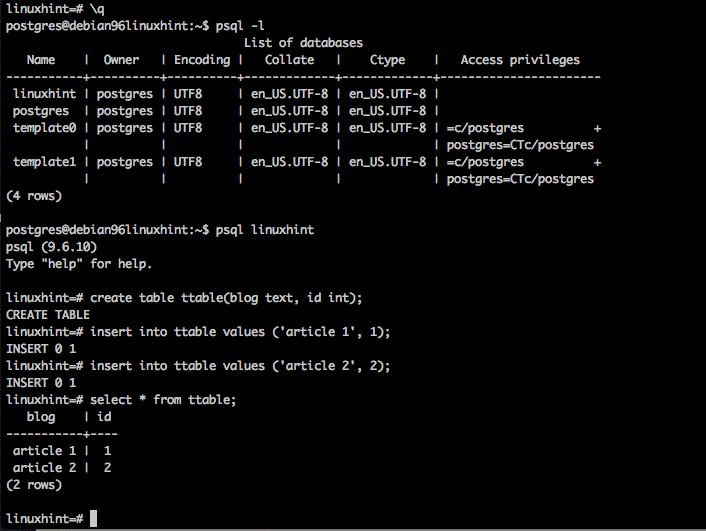
Redis – это расширенное хранилище ключ-значение с открытым исходным кодом. Его часто называют сервером структуры данных, поскольку ключи могут содержать , , , и .
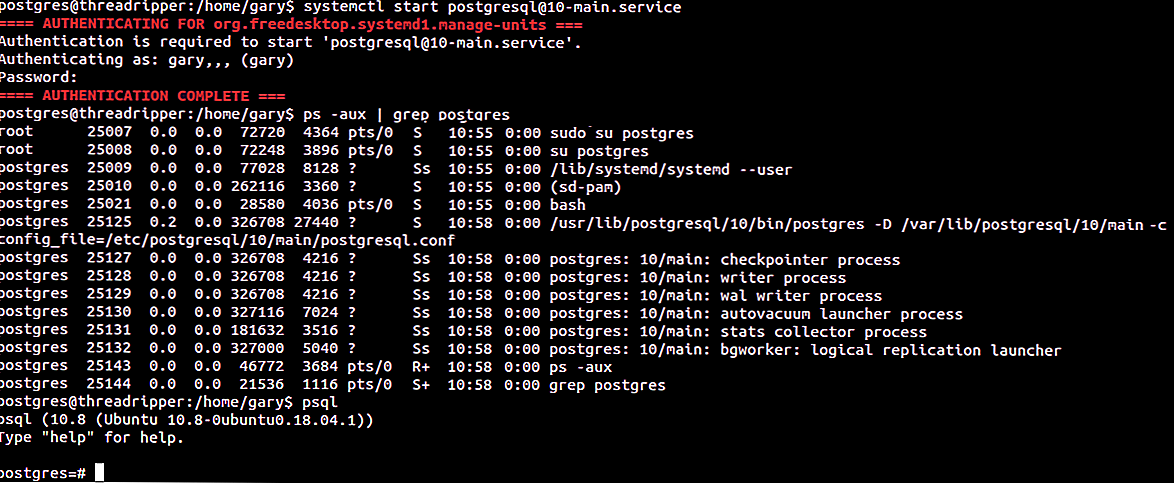
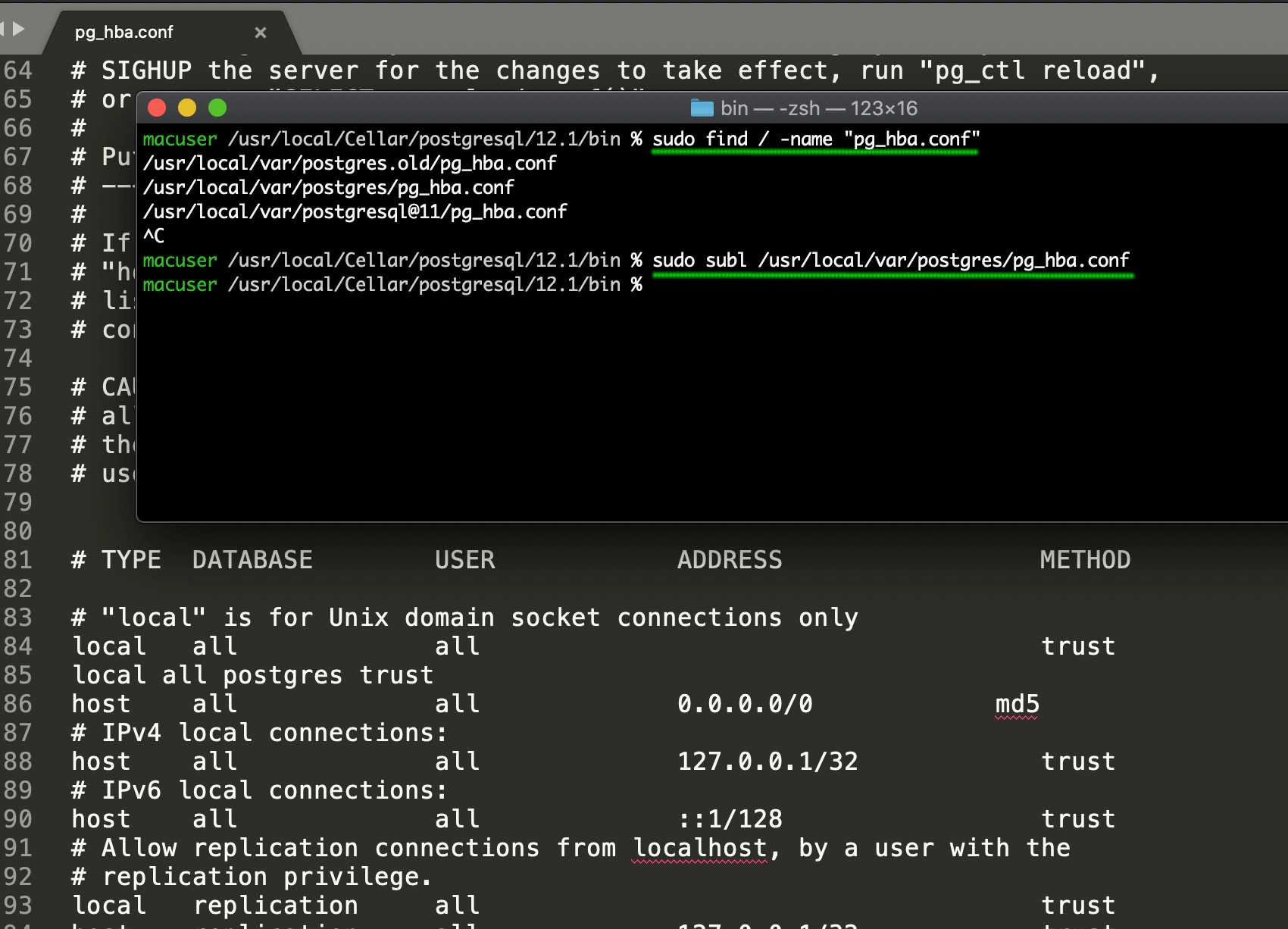
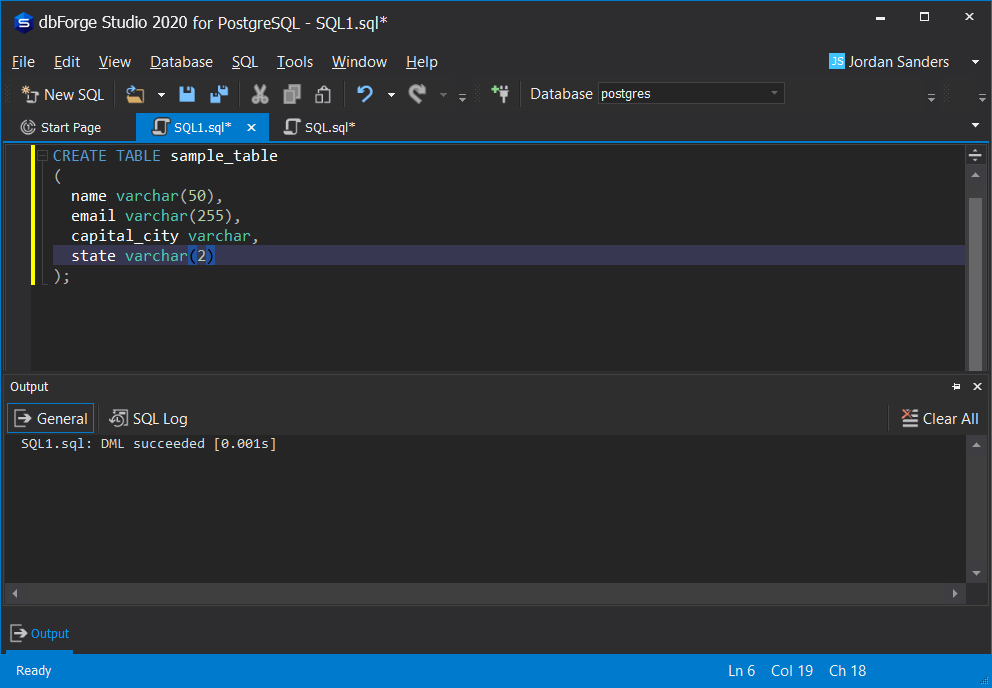
Перед использованием Redis с Laravel мы рекомендуем вам установить и использовать расширение phpredis PHP через PECL. Расширение сложнее установить по сравнению с пакетами PHP пользовательского слоя, но оно может обеспечить лучшую производительность для приложений, интенсивно использующих Redis. Если вы используете Laravel Sail, то это расширение уже установлено в контейнере Docker вашего приложения.
Если вы не можете установить расширение phpredis, то установите пакет через Composer. Predis – это клиент Redis, полностью написанный на PHP и не требующий дополнительных расширений:
LIMITS лимит
Установите количество клиентов, к которым Redis может подключаться одновременно. По умолчанию это 10 000 клиентов. Если вы не можете установить предел дескриптора файла процесса, redis установит текущее предельное значение дескриптора файла минус 32, потому что redis оставит некоторые дескрипторы для своей внутренней логики обработки. Если этот предел достигнут, redis отклонит новые запросы на подключение и отправит этим запросчикам подключения «максимальное количество клиентов».
Maxmemory
Установите объем памяти, который может использовать Redis. Как только предел использования памяти будет достигнут, redis попытается удалить внутренние данные. Правило удаления может быть указано с помощью maxmemory-policy. Если redis не может удалить данные в памяти в соответствии с правилами удаления или если установлено «удаление не разрешено», то redis будет возвращать сообщения об ошибках для тех инструкций, которые необходимо применить к памяти, таких как SET, LPUSH и т. Д.Но для инструкций без приложения памяти он все равно будет нормально реагировать, например GET. Если ваш Redis является главным Redis (что указывает на то, что ваш Redis имеет подчиненный Redis), то при установке верхнего предела использования памяти вам необходимо выделить некоторое пространство памяти в системе для кеша очереди синхронизации, только если вы установите «Do не удалять «Обстоятельства, вы не должны учитывать этот фактор
Maxmemory-policy
-
- Volatile-lru -> remove the key with an expire set using an LRU algorithm
- Allkeys-lru -> remove any key according to the LRU algorithm
- Volatile-random -> remove a random key with an expire set
- Allkeys-random -> remove a random key, any key
- Volatile-ttl -> remove the key with the nearest expire time (minor TTL)
- Noeviction -> don’t expire at all, just return an error on write operations
(1) volatile-lru: используйте алгоритм LRU для удаления ключей, только для ключей с установленным сроком действия.(2) allkeys-lru: используйте алгоритм LRU для удаления ключей.(3) Volatile-random: удалить случайные ключи из набора с истечением срока действия, только ключи с установленным сроком действия.(4) allkeys-random: удалить случайные ключи(5) volatile-ttl: удалите те ключи с наименьшим значением TTL, то есть те ключи, срок действия которых истекает недавно.(6) noeviction: без удаления. Для операций записи просто верните сообщение об ошибке
Maxmemory-samples
Установка количества выборок, алгоритм LRU и алгоритм минимального TTL не являются точными алгоритмами, а являются оценочными, поэтому вы можете установить размер выборки, redis по умолчанию проверит такое количество ключей и выберет тот, у которого есть LRU.
Настройка параметров кэша Azure для Redis
Если вы не закрепили кеш на панели мониторинга, найдите его на портале Azure через меню Все службы.
![]()
Чтобы просмотреть кэши, щелкните Все службы и выполните поиск по фразе Azure Cache for Redis (Кэш Redis для Azure).
Выберите кэш, для которого необходимо просмотреть и настроить параметры.
![]()
Просмотреть и настроить кэш можно в колонке Azure Cache for Redis (Кэш Redis для Azure).
![]()
Параметры кэша Azure для Redis можно просмотреть и настроить в разделе Кэш Azure для Redis слева с помощью меню ресурсов.
![]()
Просмотреть и настроить следующие параметры можно с помощью меню ресурсов.
- Администрирование
- Настройки поддержки и устранения неполадок
Как измерить и протестировать производительность моего кэша?
- , чтобы можно было наблюдать за работоспособностью кэша. Вы можете просмотреть метрики на портале Azure. Кроме того, их можно скачать и просмотреть с помощью привычных вам инструментов.
- Для нагрузочного теста сервера Redis можно использовать benchmark.exe.
- Убедитесь, что клиент нагрузочного тестирования и кэш Azure для Redis находятся в одном регионе.
- Используйте redis-cli.exe и наблюдайте за кэшем с помощью команды INFO.
- Если ваша нагрузка приводит к высокой степени фрагментации памяти, то необходимо масштабирование до большего размера кэша.
- Инструкции по скачиванию инструментов Redis см. в разделе .
Ниже приведены некоторые примеры использования redis-benchmark.exe. Чтобы получить точные результаты, выполните эти команды на виртуальной машине, размещенной в том же регионе, что и кэш.cache-development-faq.yml.
-
Тестирование конвейерных запросов SET с полезными данными размером в 1 КБ.
-
Тестирование конвейерных запросов GET с полезными данными размером в 1 КБ.
Примечание
Сначала выполните приведенный выше тест SET, чтобы заполнить кэш
Установка и настройка Celery
pip install celery
В папке с django проектом, в том месте где лежит файл settings.py, создадим новый файл celery.py со следующим содержимым:
import os
# Из только что установленной библиотеки celery импортируем класс Celery
from celery import Celery
# Указываем где находится модуль django и файл с настройками django (имя_вашего_проекта.settings)
# в свою очередь в файле settings будут лежать все настройки celery.
# Соответственно при указании данной директивы нам не нужно будет при вызове каждого task(функции) прописывать
# эти настройки.
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'my_supper_app.settings')
# Создаем объект(экземпляр класса) celery и даем ему имя
app = Celery('my_supper_app')
# Загружаем config с настройками для объекта celery.
# т.е. импортируем настройки из django файла settings
# namespace='CELERY' - в данном случае говорит о том, что применятся будут только
# те настройки из файла settings.py которые начинаются с ключевого слова CELERY
app.config_from_object('django.conf:settings', namespace='CELERY')
# В нашем приложении мы будем создавать файлы tasks.py в которых будут находится
# task-и т.е. какие-либо задания. При указании этой настройки
# celery будет автоматом искать такие файлы и подцеплять к себе.
app.autodiscover_tasks()
Необходимые настройки в файле settings.py:
# REDIS settings
# Настройки Redis условные и у вас они могут отличатся в зависимости от конфигурации
REDIS_HOST = '127.0.0.1'
REDIS_PORT = '6379'
# CELERY settings
CELERY_BROKER_URL = 'redis://' + REDIS_HOST + ':' + REDIS_PORT + '/0'
CELERY_BROKER_TRANSPORT_OPTION = {'visibility_timeout': 3600}
CELERY_RESULT_BACKEND = 'redis://' + REDIS_HOST + ':' + REDIS_PORT + '/0'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
Далее, для того что бы все заработало необходимо в файле __init__.py нашего проекта прописать:
# импортируем из созданного нами ранее файла celery.py наш объект(экземпляр класса) celery (app)
from .celery import app as celery_app
# Подключаем объект
__all__ = ('celery_app',)
Создание task — задач
Для начала следует пояснить, что такое task — по сути это функция или какая либо задача которую необходимо выполнить в фоновом режиме.
Итак, в нашем приложении создаем файл tasks.py в котором будет создавать функции работающие в фоне (таски)
# tasks.py
# Импортируем созданный нами ранее экземпляр класса celery(app)
from my_supper_app.celery import app
# Декоратор @app.task, говорит celery о том, что эта функция является (task-ом) т.е. должна выполнятся в фоне.
@app.task
def supper_sum(x, y):
return x + y
Выполнение созданных задач
Для того, что бы запустить на выполнения task, в django в нужном нам месте необходимо прописать:
# views.py
# Условный пример при валидации формы, мы запускаем нашу задачу.
# ...
from .tasks import supper_sum
def form_valid(self, form):
# ...
# Запускаем нашу функцию при помощи метода delay - который, запустит task.
# условно говоря celery обработает функцию в фоне.
supper_sum.delay(5, 7)
return super().form_valid(form)
3: Инструмент Memtier
Memtier – это высокопроизводительный инструмент для тестирования Redis и Memcached, созданный Redis Labs. Несмотря на то, что Memtier очень похож на redis-benchmark в некоторых аспектах, он более гибкий. Он предоставляет несколько параметров конфигурации, с помощью которых можно тоньше настроить эмуляцию нагрузки сервера Redis (в дополнение к поддержке кластера).
Чтобы установить Memtier на ваш сервер, необходимо скомпилировать его из исходного кода. Сначала установите зависимости, необходимые для компиляции кода:
Затем перейдите в домашний каталог и клонируйте проект memtier_benchmark из его репозитория Github:
Перейдите в каталог проекта и выполните команду autoreconf, чтобы сгенерировать сценарии конфигурации приложения:
Запустите скрипт configure для генерации артефактов приложения, необходимых для компиляции:
Теперь запустите make, чтобы скомпилировать приложение:
Как только сборка будет завершена, вы можете протестировать исполняемый файл с помощью этой команды:
Вы получите следующий вывод:
Следующий список содержит наиболее распространенные параметры команды memtier_benchmark:
- -s: хост (по умолчанию это localhost).
- -p: порт сервера (по умолчанию 6379).
- -a: аутентификация с помощью указанного пароля.
- -n: количество запросов на одного клиента (по умолчанию 10000).
- -c: количество клиентов (по умолчанию 50).
- -t: количество потоков (по умолчанию 4).
- –pipeline: включает конвейерную обработку
- –ratio: соотношение между командами SET и GET, по умолчанию 1:10.
- –hide-histogram: Скрывает подробную информацию о выводе.
Большинство из этих параметров очень похожи на параметры, представленные в redis-benchmark, но Memtier тестирует производительность по-другому. Чтобы лучше имитировать обычную реальную среду, стандартные тесты memtier_benchmark проверяют только запросы GET и SET в соотношении 1:10 (10 операций GET для каждой операции SET). Эта схема является более показательной для обычного веб-приложения на Redis. Вы можете настроить значение коэффициента с помощью опции –ratio.
Следующая команда запускает memtier_benchmark с параметрами по умолчанию, предоставляя в выводе только информацию высокого уровня.
Примечание: Если ваш сервер Redis требует аутентификации, вы должны добавить в команду параметр -a вместе с паролем Redis:
Вы увидите такой вывод:
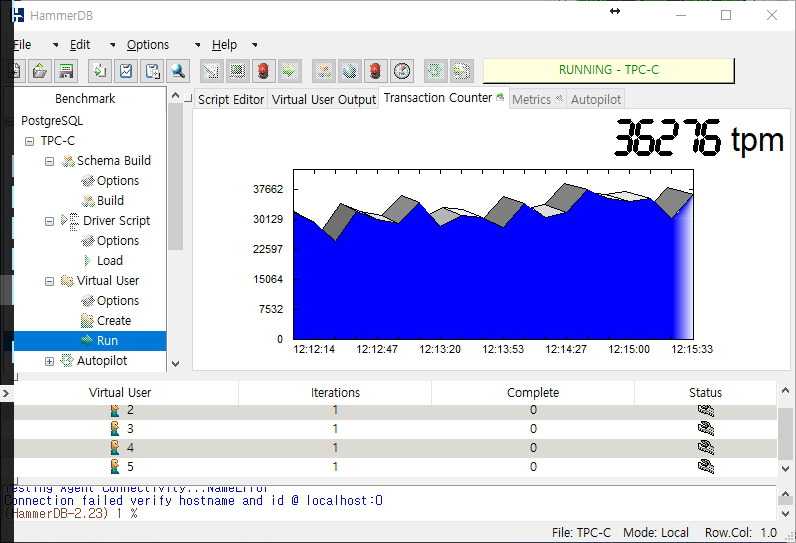
Согласно этому тесту memtier_benchmark, сервер Redis может выполнять около 90 тысяч операций в секунду в соотношении 1:10 SET/GET.
Важно отметить, что у каждого инструмента есть свой алгоритм тестирования производительности и представления данных. По этой причине они выдают разные результаты на одном сервере даже при использовании аналогичных настроек – это нормально
3.1 Сетевая задержка
Клиенты могут подключаться к Redis через TCP / IP или доменный сокет Unix. Обычно в гигабитной сетевой среде задержка в сети TCP / IP составляет 200 мкс (микросекунд), а сокет домена Unix может составлять до 30 мкс. О Unix Domain Socket (Unix Domain Socket) по-прежнему является более широко используемой технологией, пожалуйста, обратитесь к конкретнойСпособ настройки сокета домена Nginx + PHP-FPM。
Что мы можем сделать в сети, так это сократить время прохождения сигнала туда и обратно (RTT) в сети. Чиновник предоставляет следующие предложения:
- Длинное соединение: Не подключайтесь / отключайтесь от сервера часто, сохраняйте соединение как можно дольше (Jedis делает это сейчас).
- Доменное гнездо: Если клиент и сервер Redis находятся на одном компьютере, используйте сокет домена Unix.
- Многопараметрические команды: По сравнению с конвейерами предпочтительны многопараметрические команды, такие как mset / mget / hmset / hmget и т. Д.
- ТрубопроводВо-вторых, используйте трубы, чтобы уменьшить RTT.
- Сценарий LUA: Для команд, которые зависят от данных, но не могут использовать каналы, рассмотрите выполнение сценариев LUA на сервере Redis.
Альтернатива: Использование genkernel
Если ручная установка кажется слишком сложной, то можно воспользоваться утилитой genkernel, которая сконфигурирует и соберёт ядро автоматически.
genkernel конфигурирует ядро примерно так же, как это делается для установочного носителя. Это значит, что ядро, собранное genkernel, постарается определить всё оборудование в процессе загрузки. Поскольку genkernel не требует ручной конфигурации ядра, он идеально подходит для тех пользователей, кто не готов собирать собственное ядро.
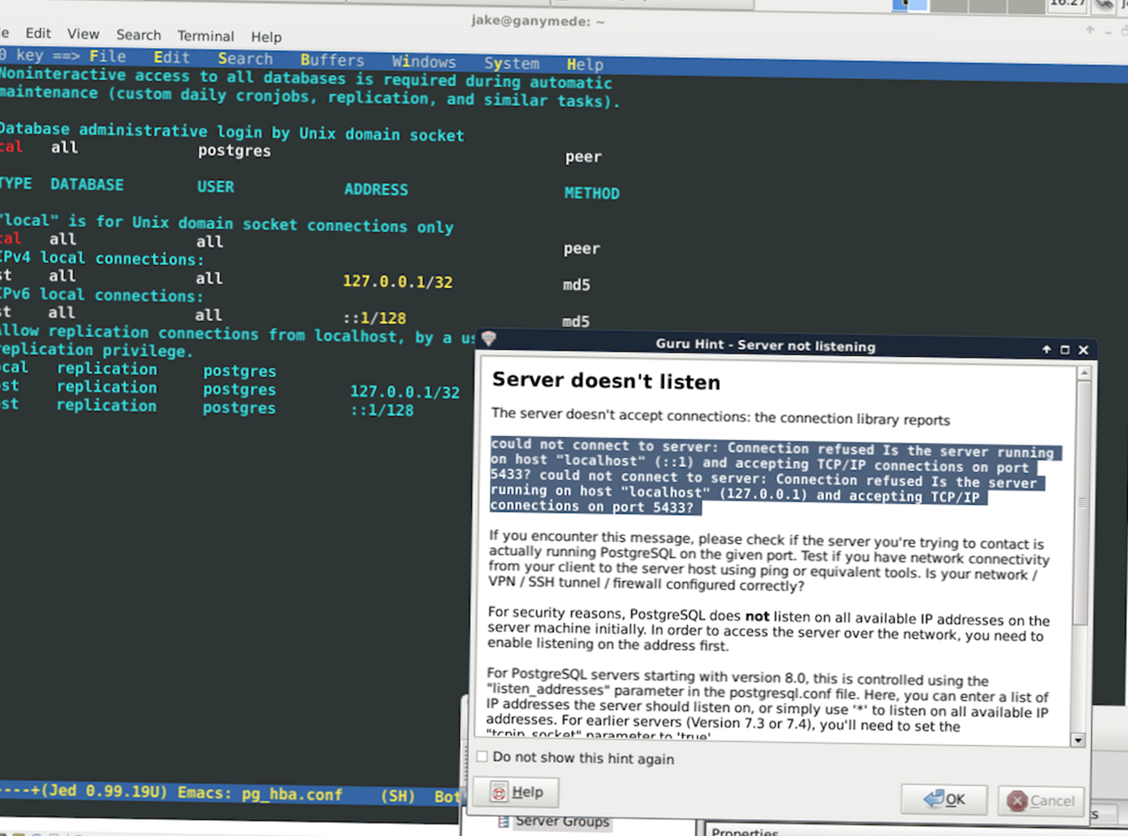
Далее отредактируйте файл /etc/fstab, где следует указать в строке /boot/ правильное устройство во втором поле. Если вы следовали примеру разбиения разделов из данного Руководста, то, скорее всего, это будет устройство /dev/sda1 с файловой системой ext2. Тогда строка должна выглядеть следующим образом:
Файл Настройка точки монтирования /boot
/dev/sda1 /boot ext2 defaults 0 2
ЗаметкаВ процессе настройки Gentoo /etc/fstab ещё будет изменён. На данный момент мы правим лишь /boot, так как genkernel использует эту настройку.
Осталось скомпилировать ядро, выполнив genkernel all. Учтите, что поскольку genkernel включает поддержку как можно большего диапазона оборудования, процесс сборки может занять некоторое время!
ЗаметкаЕсли для корневого раздела не используется ext2, ext3 или ext4, то возможно придётся вручную настроить ядро, выполнив genkernel —menuconfig all и добавив поддержку нужной ФС (не как модуля). Пользователям LVM2 следует также добавить в качестве аргумента.
По завершению работы genkernel будут сформированы ядро, полный набор модулей и файловая система инициализации (initramfs). Ядро и initrd нам понадобятся позднее. Запишите название файлов ядра и initrd, так как они нам понадобятся при настройке загрузчика. Initrd запускается сразу после ядра для определения оборудования (как при загрузке установочного CD), перед запуском самой системы.
Alternative: Using distribution kernels
Distribution Kernels are ebuilds that cover the complete process of unpacking, configuring, compiling, and installing the kernel. The primary advantage of this method is that the kernels are upgraded to new versions as part of @world upgrade without a need for manual action. Distribution kernels default to a configuration supporting the majority of hardware but they can be customized via /etc/portage/savedconfig.
There are other methods available to customize the kernel config such as .
Installing correct installkernel
Before using the distribution kernels, please verify that the correct installkernel package for the system is installed. When using systemd-boot (formerly gummiboot), install:
When using a traditional /boot layout (e.g. GRUB, LILO, etc.), the gentoo variant should be installed by default. If in doubt:
Installing a distribution kernel
To build a kernel with Gentoo patches from source, type:
System administrators who want to avoid compiling the kernel sources locally can instead use precompiled kernel images:
Upgrading and cleaning up
Once the kernel is installed, the package manager will automatically upgrade it to newer versions. The previous versions will be kept until the package manager is requested to clean up stale packages. Please remember to periodically run:
to save space. Alternatively, to specifically clean up old kernel versions:
Manually rebuilding the initramfs
If required, manually trigger such rebuilds by, after a kernel upgrade, executing:
If any of these modules (e.g. ZFS) are needed at early boot, rebuild the initramfs afterward:
EVENT NOTIFICATION
notify-keyspace-events
Когда эта опция настроена, уведомление будет срабатывать при выполнении определенной команды, но это снизит производительность и, как правило, отключено. Пустая строка означает, что уведомление отключено, укажите хотя бы один из K или E, иначе событие не будет доставлено Можно настроить следующие параметры
| параметры | объяснение |
|---|---|
| K | События пространства ключей, опубликованные с префиксом _ _ Keyspace @ <db> _ |
| E | ключевое событие, опубликованное с префиксом _ _ ключевое событие @ <db> |
| g | Общие команды (неспецифические типы), такие как DEL, EXPIRE, RENAME, … |
| $ | Строковая команда |
| l | команда list |
| s | установить команду |
| h | хэш команда |
| z | Команды сортировки |
| x | Ключевое событие с истекшим сроком действия |
| e | Изгнанные события (события, сгенерированные, когда ключи извлечены для максимальной памяти) |
| A | Псевдоним g $ lshzxe, поэтому «AKE» обозначает все события |
Например, чтобы включить списки и обычные события, используйте
Пример: чтобы получить поток ключей с истекшим сроком действия для канала подписки, name-key-event @ 0: expired, используйте
Конфигурация
Конфигурация Redis Cluster задается в файле .
- cluster-enabled <yes/no> — флаг включение Redis Cluster.
- cluster-config-file — файл, в который будет писаться системная информация: другие узлы, их состояние, глобальные переменные и прочее.
- cluster-node-timeout — максимальное время, которое master-узел может быть недоступен, по истечению этого времени он помечается как нерабочий и slaves начинают его аварийное переключение.
- cluster-slave-validity-factor — это число умноженное на таймаут узла — максимальное время, через которое slave начнет аварийное переключение.
- cluster-migration-barrier — минимальное количество slaves master-а.
- cluster-require-full-coverage <yes/no> — параметр, который говорит, нужно ли продолжать работоспособность всего кластера, если хотя бы часть хэш-слотов не покрыта.
Device Drivers
![]()
— Монтировать файловую систему tmpfs.
— выбирать лишь те драйверы, которые не требуют прошивки. В зависимости от вашего оборудования эту опцию, возможно, придётся отключить.
— включить прошивку в ядро.
— требуется для указания пути к блобам.
Например:
Но в таком случае требуется включить в конфигурационный файл ядра строку с указанием директории, в которой находятся эти блобы:
Идём далее:
Первое уже вряд ли нужно. Но если у вас есть устройства ( раньше это были все принтеры ), требующие подключения по параллельному порту — включите опцию.
Plug and Play включаем.
Блочные устройства. включить обязательно.

нужен при сборке ядра с initrd, в противном случае — отключить: «выбирайте Y, если хотите использовать часть оперативной памяти как блочное устройство. В этом устройстве вы сможете создавать файловую систему, и использовать ее как обыкновенное блочное устройство (такое как жесткий диск). Обычно его используют для загрузки и сохранения минимальной копии корневой файловой системы при загрузке с флоппи диска, CD-ROM при установке дистрибутива, или на бездисковых рабочих станциях.»
Просмотреть и принять решение включать или не включать то или иное устройство. У автора данный раздел вообще пуст.
Поддержка устройств SCSI. В современных машинах без включения этих опций могут быть не найдены такие устройства как жёсткий диск и CD-привод.
Поддержка устройств SATA. AHCI (Advanced Host Controller Interface) — механизм, позволяющий устройствам SATA пользоваться расширенными функциями.
Опции, обеспечивающие использование логических томов и программных RAID-массивов.
В следует выбрать поддержку устройства вашей сетевой карты Ethernet. PPP может понадобиться тем, кто подключается к интернету с использованием соответствующего протокола. USB Adapters — при наличии у вас поднобного адаптера для выхода в сеть. Wireless LAN — для использования беспроводных сетей стандарта IEEE 802.11. Здесь нужно выбрать соответствующий вашему оборудованию драйвер.
Нужен для определения различных устройств ввода как то: мыши, тачпады, тачскрины, джойстики, клавиатура и иные устройства. Предлагается немного побродить по списку и выбрать нужные опции.
Поддержка видео в Linux.
Поддержка веб-камер и захвата видео. Нужно включить, если имеется встроенная камера или предполагается подключать камеру внешнюю.
Включение поддержки AGP. В примере для видеокарт Intel и Radeon.
Включается, если на машине более одной видеокарты. Подробнее об этой проблеме
можно узнать в соответствующем посте.
Включить DRM — Direct Rendering Manager. Современная вещь, рекомендуется.
Управление поддержкой фреймбуфера. EFI-based Framebuffer Support нужен для систем с UEFI.
Поддержка кадрового буфера в консоли. Включаем.
Включаем пингвинов при загрузке системы ![]()
Включение поддержки звуковых устройств. Выбор своего железа из списка.
Аналогично, только для USB-устройств.
Имеет смысл посмотреть владельцам ноутбуков. Особенно тем, у кого не
работает контроль яркости экрана или горячие клавиши. Для владельцев MXM видеокарт там же включить:
Публикация / подписка
Laravel предлагает удобный интерфейс для команд и Redis. Эти команды Redis позволяют вам прослушивать сообщения на указанном «канале». Вы можете публиковать сообщения в канал из другого приложения или даже с использованием другого языка программирования, что позволяет легко взаимодействовать между приложениями и процессами.
Во-первых, давайте настроим слушатель каналов с помощью метода . Мы поместим вызов этого метода в команду Artisan, поскольку вызов метода запускает длительный процесс:
Теперь мы можем публиковать сообщения в канале с помощью метода :
Групповые подписки
Допускается использование метасимвола подстановки при использовании метода , что позволит вам перехватывать все сообщения на нескольких каналах. Имя канала будет передано вторым аргументом в указанное замыкание:
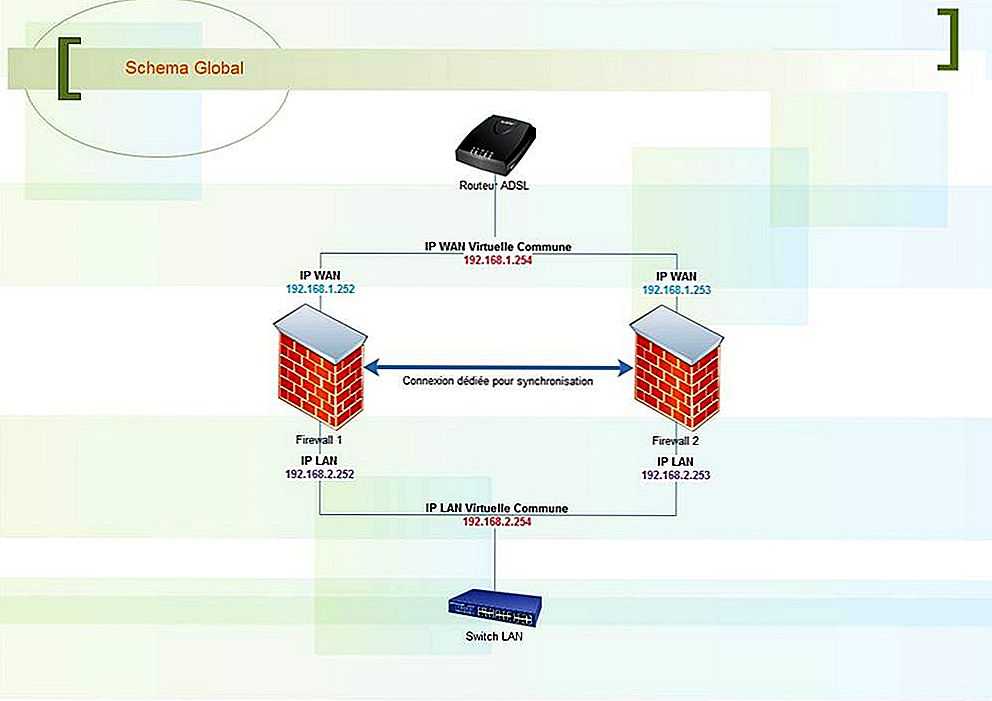
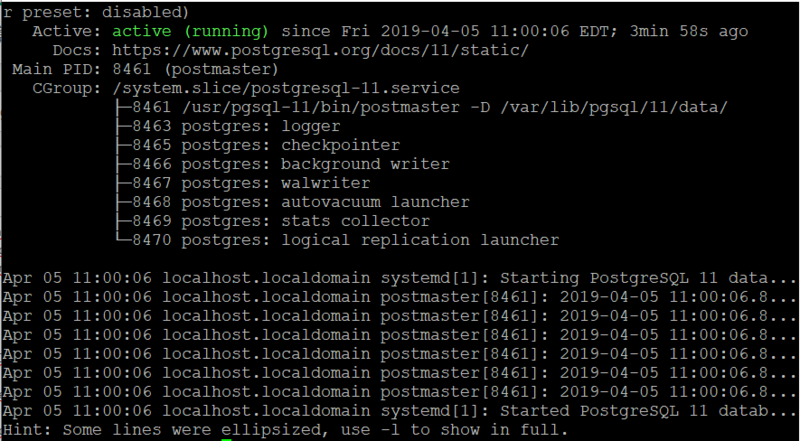
2.2 Процесс запуска репликации Redis
| шаг | Работа основного сервера | Работать с сервера |
|---|---|---|
| 1 | (Ожидание ввода команды) | Подключитесь (переподключитесь) к основному серверу и отправьте команду SYNC |
| 2 | Запустите выполнение BGSAVE и используйте буфер для записи всех команд записи после BGSAVE | В это время клиентский запрос к подчиненному серверу будет сообщен об ошибке, или он все еще может вернуть старые данные. |
| 3 | После выполнения BGSAVE отправьте снимок на подчиненный сервер и одновременно выполните ранее буферизованную команду записи. | Отменить все старые данные и загрузить полученный файл снимка |
| 4 | После отправки моментального снимка команда записи, хранящаяся в буфере, отправляется на подчиненный сервер. | Завершите синхронизацию снимка и начните принимать команды записи от главного сервера. |
| 5 | Каждый раз, когда выполняется команда записи, отправляется одна и та же команда. | Принимать команды записи с главного сервера |
На втором этапе мы видим, что Redis требуется буфер при выполнении BGSAVE, поэтому мы рекомендуем, чтобы основной сервер использовал только 50% ~ 60% памяти, а оставшаяся память была зарезервирована для операций BGSAVE и команд записи.
Устранение проблем
Изменения конфигурации не вступают в силу
Среди пользователей весьма распространенной ошибкой является то, что они делают изменения в конфигурации, но затем совершают небольшую ошибку в процессе загрузки в только что настроенное ядро. Они перезагружаются в образ ядра, не являющийся тем, который они только что сконфигурировали, замечают, что проблема, которую они пытались решить, все еще присутствует и приходят к выводу что изменения конфигурации не решили проблему.
Процесс компиляции и установки ядер находится за рамками этого документа; обратитесь к руководству по обновлению ядра за общими инструкциями. Вкратце, процесс получения изменённого ядра заключается в следующем:
- конфигурация
- компиляция
- монтирование раздела /boot (если он ещё не примонтирован)
- копирование нового образа ядра в /boot
- убедитесь, что загрузчик ссылается на новое ядро
- перезагрузка.
Если какой-нибудь из финальных шагов пропущен, изменения не вступят в силу.
Можно проверить соответствует ли загруженное ядро с недавно скомпилированным ядром. Это можно сделать, изучив дату и время компиляции ядер. Предполагая, что используется архитектура x86 и исходный текст ядра установлены в /usr/src/linux, можно использовать следующую команду:
#4 SMP PREEMPT Sat Jul 15 08:49:26 BST 2006
Приведенная выше команда отобразит дату и время компиляции ядра, загруженного в настоящий момент.
-rw-r--r-- 1 dsd users 1504118 Jul 15 08:49 /usr/src/linux/arch/i386/boot/bzImage
Приведенная выше команда отображает дату и время когда образ ядра был скомпилирован в последний раз.
Если временные отметки из предыдущих команд отличаются более чем на 2 минуты, это означает что в процессе переустановки ядра была сделана ошибка и система загружена не с новым образом ядра.
Модули не загружаются автоматически
Как указано в этом документе ранее, система конфигурации ядра скрывает под собой большие изменения в поведении при выборе компонента ядра в качестве модуля , вместо встроенного
Важно повторить это снова, так как много пользователей попадают в эту ловушку.. При встраивании компонента в ядро, код встраивается в образ ядра (bzImage)
Когда ядру требуется использовать этот компонент, оно может инициализировать и загрузить его автоматически, без вмешательства пользователя
При встраивании компонента в ядро, код встраивается в образ ядра (bzImage). Когда ядру требуется использовать этот компонент, оно может инициализировать и загрузить его автоматически, без вмешательства пользователя.
При выборе компонента в качестве модуля, код встраивается в файл модуля ядра и устанавливается на файловую систему. В основном, когда ядру требуется использовать этот компонент, оно не может найти его. За некоторыми исключениями, ядро не совершает попыток загрузки этих модулей — эта задача оставлено пользователю.
Если поддержка сетевой платы включена в качестве модуля, и затем обнаруживается что сеть не доступна, это, возможно, потому что модуль не загружен — можно, либо сделать это вручную, либо система должно быть настроена для автоматической загрузки модулей во время запуска системы.
Если нет особых причин сделать по-другому, то можно сохранить время компилируя эти компоненты прямо в образ ядра, так чтобы ядро могло автоматически произвести эти небольшие настройки самостоятельно.
Другая документация по конфигурации ядра
До сих пор обсуждались только основные концепции и специфические проблемы, относящиеся к конфигурации ядра, без углубления в подробности; подробности оставлены для изучения пользователю. Однако, другие части документации Gentoo предусматривают специализированные подробности для рассматриваемых тем.
Эти документы могут быть полезны при конфигурации специфичных областей ядра. Хотя это предупреждение было упомянуто ранее в этом руководстве, запомните: пользователям, которые только начали осваивать конфигурацию ядра, не следует смело изменять любые настройки в ядре. Сначала настройте базовое и загружающееся ядро, всегда можно вернуться к настройке позже, чтобы добавить поддержку звука, печати и так далее.
Настройки «базово-рабочего» ядра помогут в последующей конфигурации, поскольку пользователь будет знать, что может нарушить базовую работу систему, а что нет. Разумно будет сохранить базовую (рабочую) конфигурацию ядра в другой каталог, а не в каталог с исходным кодом ядра до добавления новых функций или поддержки аппаратного обеспечения.
Статья ALSA описывает в подробностях параметры, требуемые для звуковой карты. Следует заметить, что ALSA является исключением из предложенной схемы сборки компонентов не в качестве модулей: систему ALSA намного проще сконфигурировать, если компоненты являются модульными.
![[заметка] redis cluster](https://myeditor.ru/wp-content/uploads/e/f/7/ef71ee839981aeec461a7211349f908c.png)
Статься Bluetooth описывает параметры, необходимые для использования устройств Bluetooth.
Руководство по развертыванию IPv6-маршрутизатора описывает как сконфигурировать ядро для маршрутизации, используя схему сетевой адресации нового поколения.
При использовании закрытых графических драйверов nVidia для улучшенной производительности 3D-графики, в руководстве по nVidia перечисляются параметры, которые требуется выбрать или отключить.
В числе прочих вещей, в руководстве по управлению питанием объясняется как настроить ядро для управления частотой центрального процессора и для функций энергосбережения и режима сна.
Если используется система PowerPC, в списке часто задаваемых вопросов по PPC имеются несколько разделов, посвященных конфигурации ядра для PPC.
Руководство по печати перечисляет параметры ядра, необходимые для поддержки печати в Linux.
Руководство по USB описывает конфигурацию, необходимую для использования распространенных USB-устройств, таких как клавиатуры и мыши, запоминающие устройства и USB-принтеры.
Какие факторы следует учитывать при использовании общих команд Redis?
- Избегайте определенных команд Redis, которые выполняются слишком долго, если не до конца понимаете результат этих команд. Например, не запускайте команду KEYS в рабочей среде. В зависимости от числа ключей выполнение может занять много времени. Redis является однопотоковым сервером и обрабатывает команды по одной. Если вы выдадите после KEYS другие команды, они не будут обрабатываться, пока Redis обрабатывает команду KEYS. Сайт redis.io содержит сведения о временной сложности каждой поддерживаемой операции. Щелкните каждую команду, чтобы просмотреть сведения о сложности операции.
- Размеры ключей — следует использовать пары «ключ-значение» небольшого или большого размера? Это зависит от сценария развертывания. Если в сценарии требуются большие ключи, то можно настроить значения повторов и ConnectionTimeout, а также настроить логику повторов. С точки зрения сервера Redis чем меньше значения, тем выше производительность.
- Это не означает, что в Redis нельзя хранить большие значения; вы должны учитывать описанные ниже факторы. Задержки будут выше. Если один из используемых наборов данных больше, а другой меньше, можно использовать несколько экземпляров ConnectionMultiplexer. Настройте для каждого из них свои значения времени ожидания и повтора, как описано в предыдущем разделе:
Когда следует включать порт, не являющийся портом TLS/SSL, для подключения к Redis?
Сервер Redis не имеет встроенной поддержки TLS, но Кэш Azure для Redis имеет. Если вы подключаетесь к Кэшу Azure для Redis и ваш клиент поддерживает протокол TLS, например StackExchange.Redis, то следует использовать TLS.
Примечание
По умолчанию порт без TLS отключен для новых экземпляров кэша Azure для Redis. Если ваш клиент не поддерживает TLS, необходимо включить порт, не являющийся портом TLS, следуя указаниям, приведенным в разделе статьи Настройка кэша Azure для Redis.
Инструменты Redis, такие как , не работают с портом TLS, но вы можете использовать служебную программу, например , для безопасного подключения инструментов к порту TLS в соответствии с указаниями в записи блога Анонс поставщика состояний сеансов ASP.NET для предварительной версии Redis.
Инструкции по скачиванию инструментов Redis см. в разделе .
Консоль Redis
В экземплярах кэша Azure для Redis можно безопасно выполнять команды с помощью консоли Redis, доступной на портале Azure для всех категорий кэшей.
Важно!
- Консоль Redis не работает с VNET. Если кэш является частью виртуальной сети, то к нему могут обращаться только клиенты в этой виртуальной сети. Так как консоль Redis работает в локальном браузере вне виртуальной сети, она не может подключиться к кэшу.
- В кэше Azure для Redis поддерживаются не все команды Redis. Список команд Redis, отключенных в кэше Azure для Redis, см. в предыдущем разделе — . Дополнительные сведения о командах Redis см здесь: https://redis.io/commands.
Чтобы иметь доступ к консоли Redis, в разделе Кэш Azure для Redis слева выберите Консоль.
![]()
Чтобы выполнить команду в своем экземпляре кэша, введите нужную команду в консоль.
![]()
Использование консоли Redis с кластеризированным кэшем категории «Премиум»
При использовании консоли Redis с кластеризированным кэшем категории «Премиум» можно выполнять команды для одного сегмента кэша. Чтобы выполнить команду для конкретного сегмента, сначала подключитесь к нужному сегменту, выбрав его в окне выбора сегментов.
![]()
При попытке получить доступ к ключу, который хранится в другом сегменте, вы получите следующее сообщение об ошибке.
В предыдущем примере выбран сегмент 1, но находится в сегменте 0, как указано в части сообщения об ошибке. В этом примере для доступа к выберите сегмент 0 с помощью средства выбора сегментов, а затем выполните необходимую команду.





