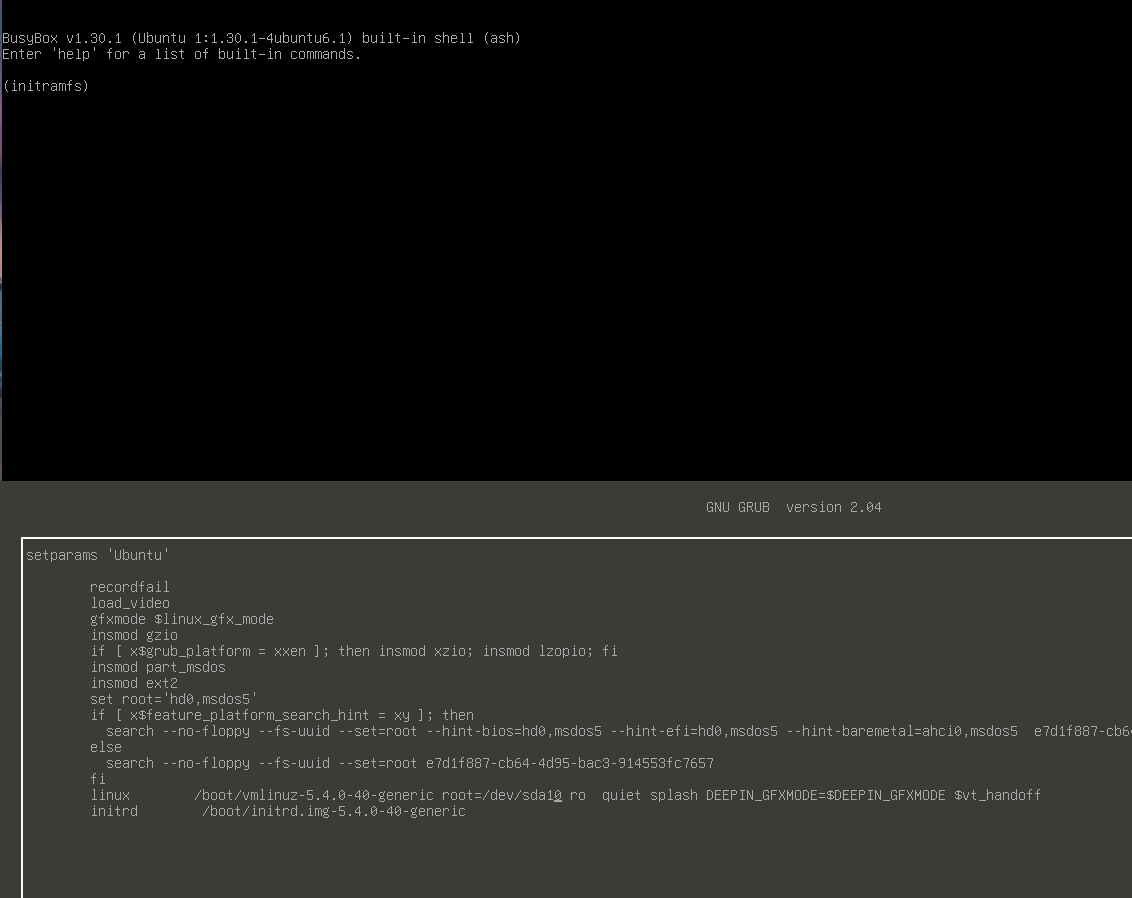
Force fsck on reboot
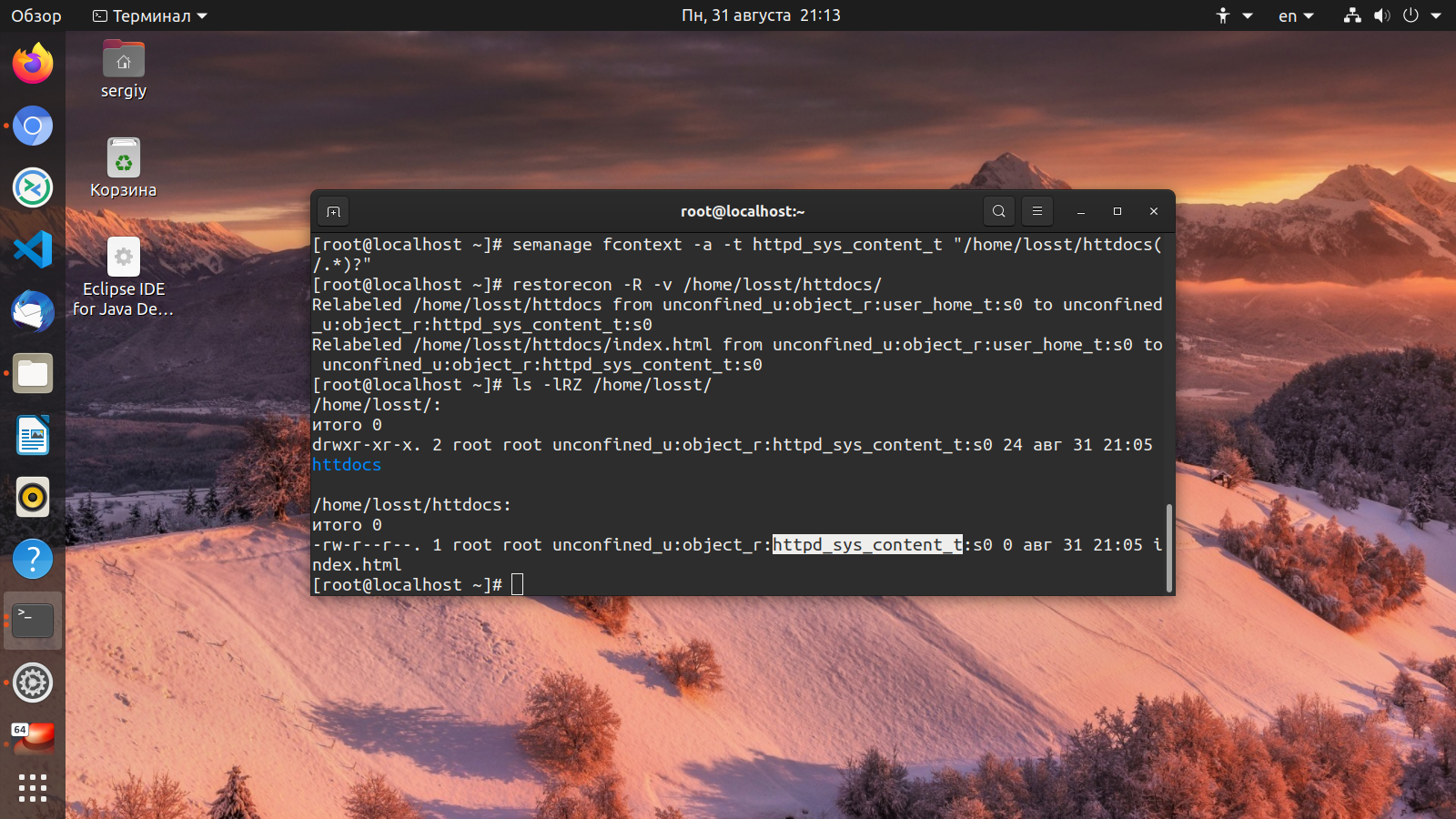
Удивительно, но на за все время своей работы системным администратором Linux, с подобной проблемой я столкнулся впервые. Как говорится, ничто не предвещало беды. Выбрал наиболее подходящее время для обновления системы и сделал его. После этого решил перезагрузить сервер. Операция была запланированная и до этого я уже обновил с десяток серверов. Но с этим последним что-то пошло не так. Долго не возвращается в мониторинг. Решил сходить на гипервизор и посмотреть, что с ним. А там такая картинка.
![]()
A start job is running for File System Check on /dev/vgmail/mail
Идет проверка раздела на ошибки. При чем этот lvm раздел размером в 3Tb, на нем хранится почтовый архив. Нет никакой индикации и не понятно, с чем вообще все это связано и сколько времени продлится. Сервер в работе, подключается куча людей. Я вижу, что операция вроде как плановая, так как никаких ошибок нет. Но то, что сервер не работает, уже ошибка. Самое главное, не понятно, сколько эта проверка может длиться. И еще всегда остается шанс, что это внештатная ситуация и с разделом какие-то проблемы. Это самый плохой расклад.
Я терпеливо подождал где-то час и не выдержал. В первую очередь хотел понять, происходил ли вообще что-то с диском. Пошел на гипервизор и проверил. Реально идет активное чтение с диска. Записи нет. Из этого сделал вывод, что можно безопасно сбросить виртуалку. К слову, весь тот час, что я ждал, прогуглил весь буржунет, чтобы понять, как принудительно прервать эту проверку. Перепробовал все, что только можно. Не помогло ничего. Прервать или отложить проверку не смог.
Параллельно сходил и проверил бэкап. Он был, свежий, все в порядке. Но сколько времени займет восстановление, если забирать эти данные по сети? Я так прикинул, никак не меньше суток, скорее ближе к двум. Надо было бы ехать и забирать локально. Сначала в один цод, потом во второй. Везде надо договариваться о приезде, оформлять пропуск и т.д. Сидеть ждать, пока локально скопируется файлы. Как-то еще внешний диск надо подключить и найти подходящего объема. В общем, та еще проблема. Одно наличие актуального бэкапа вообще не решает проблему восстановления данных.
В итоге сбросил виртуалку и при загрузке выбрал режим Rescue.
![]()
Я рассчитывал, что в этом режиме проверка диска не будет запускаться. По факту ошибся, проверка тоже запустилась, но в этот раз периодически в строке проскакивала индикация выполнения и было видно, что она продолжается. Так же, по изменению статуса, я прикинул, что проверка будет длиться около двух часов. Я посчитал, что для меня это время приемлемо в данной ситуации и решил больше не дергать виртуалку, чтобы не сделать хуже. Дождался окончания процесса.
В итоге, все завершилось и операционная система штатно загрузилась. В логах увидел подробности:
![]()
systemd-fsck: /dev/mapper/vgmail-mail has gone 357 days without beign checked, check forced.
Система в системе в виде systemd решила, что диск давно не проверяли на ошибки, поэтому принудительно инициировала этот процесс, который длился в итоге 1,5 часа. Первый раз немного не дождался окончания.
![]()
Как отключить fsck при загрузки системы
По идее, чтобы подобные проверки не запускались автоматически, достаточно в fstab, в последнем столбце написать 0. Напомню, что это за параметр. Формат файла fstab следующий:
filesystem dir type options dump pass
Последняя строка как раз для fsck, может принимать следующие значения:
- 0 — проверка отключена полностью. То, что надо было указать мне в самом начале.
- 1 — наивысший приоритет проверки.
- 2 — менее высокий приоритет очередности проверки.
У меня стояла цифра 2. Я не знаю, чем руководствовался, когда настраивал fstab. Скорее всего на автомате указал или скопировал. Не подумал о последствиях. Есть только один момент, который меня беспокоит. Не факт, что systemd руководствуется этим параметром, а не каким-то своим. Она давно уже живет своей жизнью и требует отдельных настроек и внимания к себе. Нужно будет разобраться с этим моментом повнимательнее.
Настройка системы
Во-первых SELinux отключен не полностью. Для полного отключения добавляем строку в файл /etc/selinux/config:
Во-вторых, проверка файловых систем тоже может занять некоторое время. Оставляем проверку на ошибки только для корня. Для этого откройте файл /etc/fstab и приведите строчку для корня к такому виду:
Последний параметр отвечает за проверку, 1 — проверять, 0 — не проверять. Установите для всех других разделов 0. К тому же boot раздел лучше монтировать по требованию. Для этого изменяем его запись:
Затем давайте перенесем папку /tmp в оперативную память, чтобы уменьшить количество операций на жестком диске:
Как проходит загрузка Linux
Во всех подробностях процесс загрузки Linux описан в отдельной статье, здесь же мы рассмотрим только то, что будет касаться ускорения.
На то как BIOS тестирует устройства и запускает загрузчик мы повлиять не можем. Работу загрузчика тоже ускорить не получится, можно только убрать ожидание выбора пункта меню.
Но самое интересное начинается дальше. Перед тем как начать загрузку системы ядро выполняет несколько проверок, загружает модули и так далее. Не все проверки нужно выполнять и не все модули нам нужны.
После того как ядро передало управление системе инициализации, начинается монтирование дисков. Это тоже отнимает время, лучше не использовать виртуальные разделы дисков, например, raid или lvm, да и вообще, чем меньше разделов — тем лучше. Идеальный вариант — только корневой раздел, тогда скорость загрузки linux будет максимальной. Но это очень невыгодный в плане удобства вариант, поэтому найдите золотую серединку. Перед тем как примонтировать каждый диск, система инициализации пытается проверить файловую систему на ошибки, это тоже замедляет загрузку.
Загрузка сервисов отнимает больше всего времени и больше всего работы придется проделать здесь, определить какие сервисы не нужны и отключить их также скрыть те сервисы, которые отключить нельзя. Чтобы понять что именно отключать нам нужно знать сколько времени занимает загрузка каждого сервиса. Давайте рассмотрим анализ скорости загрузки systemd.
Как исправить ошибку «не выключается Linux»
Чтобы понять, почему система не может выключиться, нам сначала необходимо посмотреть лог её выключения. И тут у нас тоже есть два пути: либо отключить заставку и выводить лог в реальном времени, либо записывать лог выключения с помощью journalctl.
1. Лог выключения в реальном времени
Первый способ не настолько информативный, но всё же может быть полезным. Для отключения заставки откройте /etc/default/grub и в строке GRUB_CMDLINE_LINUX_DEFAULT замените слова quiet splash на verbose:
![]()
![]()
Выполите:
![]()
Затем перезагрузите компьютер. Сначала вы будете видеть полный лог загрузки, а при выключении вы увидите полный лог выключения. Преимущество этого пути в том, что вы увидите, на какой команде загрузка зависает, и сможете понять, куда копать дальше. Например, часто бывает, что Linux не может выключиться из-за ошибки «a stop job is running for Session c2 of user», т.е. мы не можем завершить сессию пользователя. Ещё выключению могут препятствовать примонтированные удалённые файловые системы.
2. Лог выключения в journalctl
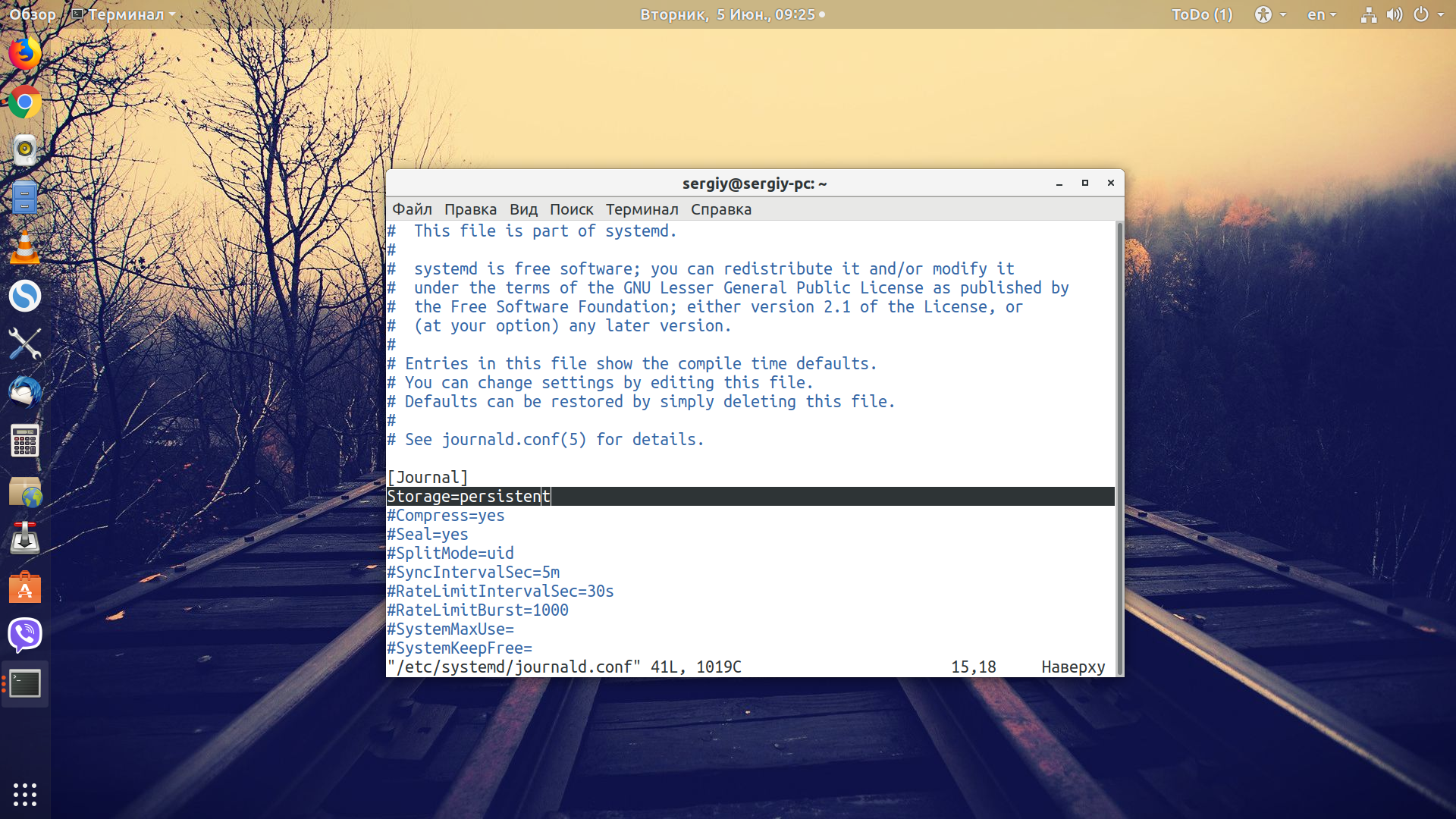
Утилита journalctl занимается обработкой логов в Linux, но есть одна проблема: она записывает журналы только из текущей сессии, при перезагрузке всё стирается. Но это можно исправить. Для этого окройте конфигурационный файл /etc/systemd/journald.conf и замените в нём значение строки Storage=auto на Storage=persistent:
![]()
Затем два раза перезапустите компьютер. Первый раз мы перезапускаем, чтобы настройки логирования вступили в силу, а второй, чтобы собрать лог последнего выключения Linux. После того, как загрузка завершиться, вы можете посмотреть лог с помощью такой команды:

![]()
Опция -b позволяет вывести лог загрузки, -1 говорит, что нужно брать не текущую загрузку, а предыдущую, а -n300 отображает только последние 300 строк. Здесь вы можете видеть, что по таймауту была завершена именно сессия session-c1. Мы можем отфильтровать сообщения только по ней:
Если вы увидели ошибку и смогли её решить, то ваша система будет выключаться уже мгновенно, если же нет, то всё ещё есть несколько путей решения.
3. Настройка таймаутов в systemd
Если никакое из предыдущих решение не помогло, и в системе просто баг, который не позволяет ей адекватно выключиться, то вы всё ещё можете уменьшить время ожидания до того, как процессу будет отправлен сигнал экстренного завершения. Для этого откройте файл /etc/systemd/system.conf и добавьте туда такие строки:
![]()
Теперь система будет ждать только 5 секунд перед тем, как завершить проблемный процесс. Также на некоторых форумах рекомендуют установить сервис watchdog, чтобы он следил за правильностью работы системного таймера. Это тоже делается очень просто:
![]()
SNP Background Processes
To maximize performance and accommodate many users, a multi-process Oracle system uses some additional processes called background processes. Background processes consolidate functions that would otherwise be handled by multiple Oracle programs running for each user process. Background processes asynchronously perform I/O and monitor other Oracle processes to provide increased parallelism for better performance and reliability.
SNP background processes execute job queues. You can schedule routines, which are any PL/SQL code, to be performed periodically using the job queue. To schedule a job, you submit it to the job queue and specify the frequency at which the job is to be run. You can also alter, disable, or delete jobs you have submitted.
You must have at least one SNP process running to execute queued jobs in the background. SNP processes periodically wake up and execute any queued jobs that are due to be run. SNP background processes differ from other Oracle background processes, in that the failure of an SNP process does not cause the instance to fail. If an SNP process fails, Oracle restarts it.
SNP background processes will not execute jobs if the system has been started in restricted mode. However, you can use the ALTER SYSTEM statement to turn this behavior on and off as follows:
ALTER SYSTEM ENABLE RESTRICTED SESSION; ALTER SYSTEM DISABLE RESTRICTED SESSION;
When you ENABLE a restricted session, SNP background processes do not execute jobs; when you DISABLE a restricted session, SNP background processes execute jobs.
|
See also: For more information on SNP background processes, see Oracle8i Concepts. |
Multiple SNP processes
An instance can have up to 36 SNP processes, named SNP0 to SNP9, and SNPA to SNPZ. If an instance has multiple SNP processes, the task of executing queued jobs can be shared across these processes, thus improving performance. Note, however, that each job is run at any point in time by only one process. A single job cannot be shared simultaneously by multiple SNP processes.
Starting up SNP processes
Job queue initialization parameters enable you to control the operation of the SNP background processes. When you set these parameters in the initialization parameter file for an instance, they take effect the next time you start the instance.
The JOB_QUEUE_PROCESSES parameter specifies the number of job queue process per instance. Different instances can have different values. This initialization parameter can be altered dynamically using the ALTER SYSTEM statement as shown in the following example.
ALTER SYSTEM SET JOB_QUEUE_PROCESSES = 10;
The JOB_QUEUE_INTERVAL parameter specifies the interval between wake ups for the SNP processes. Different instances can have different values.
|
See Also: For a description of these initialization parameters, see the Oracle8i Reference, |
Как получить доступ к службам Linux в WSL (какой IP у Linux)
Для дистрибутивов Linux создаётся виртуальная сеть Ethernet. Благодаря этой сети можно получить доступ из Windows в Linux, а также в обратном направлении.
Чтобы узнать IP адрес Linux выполните команду:
ip a
На скриншоте видно, что IP адресом Linux является 172.26.173.37. На предыдущем шаге мы запустили веб-сервер — попробуем в веб-браузере из Windows открыть страницу с веб-сервера в Linux:
Мы видим «Apache2 Debian Default Page», то есть страницу по умолчанию веб-сервера Apache2 на Debian.
Это означает, что
- Веб-сервер действительно работает
- Мы можем получить доступ к сетевым службам Linux из Windows
Что мне осталось непонятным — все запущенные дистрибутивы имеют один и тот же IP адрес. Более того, если запустить службу (открыть порт) на одном из дистрибутивов, то этот же порт окажется открытым и на всех остальных. Следовательно, например, не получится запустить веб-сервер одновременно на двух или более дистрибутивах… У всех дистрибутивах в WSL один сетевой интерфейс на всех.
Ошибка «unable to connect to socket: Подключение не установлено, т.к. конечный компьютер отверг запрос на подключение. (10061)»
При использовании команды kex в Kali Linux (Win-KeX) может возникнуть ошибка:
unable to connect to socket: Подключение не установлено, т.к. конечный компьютер отверг запрос на подключение. (10061)
В командной строке выводится:
TigerVNC Viewer 32-bit v1.10.80
Built on: 2020-06-15 22:33
Copyright (C) 1999-2020 TigerVNC Team and many others (see README.rst)
See https://www.tigervnc.org for information on TigerVNC.
Fri Sep 11 06:41:39 2020
DecodeManager: Detected 12 CPU core(s)
DecodeManager: Creating 4 decoder thread(s)
Fri Sep 11 06:41:41 2020
CConn: unable to connect to socket: Подключение не
установлено, т.к. конечный
компьютер отверг запрос на
подключение. (10061)
Для исправления этой ошибки нажмите Ctrl+c.
Затем введите команду
kex stop
Эта команда может вывести что-то вроде следующего:
Killing Win-KeX process ID 1618... which was already dead Cleaning stale pidfile '/home/mial/.vnc/HackWare-MiAl.localdomain:1.pid'! Cleaning stale x11 lock '/tmp/.X1-lock'! Cleaning stale x11 lock '/tmp/.X11-unix/X1'!
Вновь попробуйте открыть графический интерфейс:
kex
На этот раз всё должно заработать:
Причина ошибки до конца не ясна — возможно, дело в неудачном старте VNC сервера или процесса Win-KeX, на это указывает строка «Win-KeX process ID 1618… which was already dead», то есть процесс уже мёртвый.
Командой kex stop мы принудительно останавливаем Win-KeX, который при следующем запуске работает нормально.
Характеристика дистрибутивов Linux в WSL
Debian
Debian — популярен как дистрибутив, например, для серверов, так и как основа для других дистрибутивов. Например, на Debian основываются Ubuntu, Kali Linux, Linux Mint (есть версия LMDE, которая основывается непосредственно на Debian, а также «классическая» версия, которая основывается на Ubuntu, которая, в свою очередь, также основывается на Debian).

То есть Debian и производные очень популярна.
Вы сможете использовать полную среду командной строки Debian, содержащую среду полной текущей стабильной версии.
Kali Linux
Kali Linux — это популярнейший дистрибутив для специалистов в информационной безопасности, цифровой криминалистике, хакеров и продвинутых пользователей. Вы можете установить и использовать в родной среде Linux множество специализированных инструментов. Для Kali Linux разработано ПО для упрощённого запуска графического интерфейса (смотрите статью «Как установить Kali Linux с Win-KeX (графический интерфейс) в WSL2 (подсистему Windows для Linux)», а также для инструкций на HackWare.ru взят именно этот дистрибутив, поэтому для него вы найдёте много детаьлных инструкций. По этой причине рекомендуется Kali Linux.
SUSE Linux Enterprise Server
SUSE Linux Enterprise Server — это мультимодальная операционная система, которая открывает путь к трансформации ИТ в эпоху программного обеспечения. Современная модульная ОС помогает упростить мультимодальные ИТ, делает традиционную ИТ-инфраструктуру эффективной и обеспечивает привлекательную платформу для разработчиков. В результате вы можете легко развертывать и переносить критически важные для бизнеса рабочие нагрузки в локальную и общедоступную облачные среды. SUSE Linux Enterprise Server 15 SP1 с его мультимодальным дизайном помогает организациям трансформировать свой ИТ-ландшафт за счет объединения традиционной и программно определяемой инфраструктуры.
Ubuntu
В WSL у дистрибутива Ubuntu также отсутствует графический интерфейс (как по умолчанию у всех других дистрибутивов), поэтому её нельзя назвать более «дружественной» к пользователю. Основана на Debian.
Fedora
Обещают добавить, но пока отсутствует.
Ускорение загрузки Linux отключением сервисов
Вот мы и добрались к сервисам. Оптимизация сервисов заключается в том, чтобы отключить лишнее, а также использовать только возможности, встроенные в systemd, так будет быстрее. Сначала перенесем всю функциональность на systemd.
Первым отключим rsyslog. В systemd используется свой механизм записи логов journald, поэтому вести еще один не нужно. Для отключения выполните:
Опция mask позволяет спрятать юнит, система будет думать что его не существует и не сможет загрузить. Восстановить такой юнит можно командой systemctl unmask.
В systemd реализована своя служба настройки сети — networkd, поэтому необязательно использовать NetworkManager. Работа со встроенной службой будет намного быстрее. Здесь нужно заметить, что если вы используете wifi и не хотите настраивать его вручную, через консоль, то отключать NetworkManager не стоит.
Отключаем NetworkManager и включаем networkd:
Службу networking тоже можно отключить, если не используете:
Включаем resolved, который отвечает за настройку DNS серверов:
Даем символическую ссылку на файл /etc/resolv.conf
Осталось настроить динамическое получение ip адреса при загрузке:
enp0* значит, что сеть нужно подымать только для устройств, имена которых начинаются на enp0. Готово, сеть настроена.
В systemd есть свое решение для выполнения задач по расписанию, поэтому cron можно не использовать:
С заменой разобрались, перейдем к удалению лишнего. Отключаем фаервол, на домашней машине, за маршрутизатором он не нужен:
Отключаем apport (служба отчетов об ошибках):
Я не использую ppp и мобильные соединения, поэтому и эти сервисы можно отключить.
Если вы не используете Avahi, его тоже можно отключить:
Систему AppArmor тоже можно отключить:
Также если у вас загружаются такие программы, как postfix (почтовый сервер), apache (веб-сервер), mysql (сервер баз данных) лучше их тоже убрать из автозагрузки и запускать потом вручную.
Перезагружаемся и проверяем скорость загрузки:
У меня скорость загрузки linux выросла на пять секунд. Но это нормально, учитывая, что используется VirtualBox, на реальной машине можно получить и больше. А самая лучшая оптимизация — купить SSD, там можно достичь даже скорости загрузки до двух-трех секунд.
Ошибка «E: Release file for http://http.kali.org/kali/dists/kali-rolling/InRelease is not valid yet (invalid for another 2h 43min 57s). Updates for this repository will not be applied»
При попытке обновления Kali Linux я столкнулся с ошибкой:
Суть её в том, что релизный файл для репозитория ещё не является действительным и, следовательно, обновление из этого репозитория невозможно.
Такое может произойти из-за неправильной цифровой подписи репозитория или неправильного времени.
Я столкнулся с этой ошибкой в WSL2 (подсистеме Windows для Linux), но, теоретически, она может возникнуть и в обычном дистрибутиве Kali Linux, а также в Docker.
При запуске команды:
sudo apt update && sudo apt full-upgrade -y
Я получил:
Get:1 http://kali.download/kali kali-rolling InRelease Reading package lists... Done E: Release file for http://http.kali.org/kali/dists/kali-rolling/InRelease is not valid yet (invalid for another 2h 43min 57s). Updates for this repository will not be applied.
Эта проблема вызвана тем, что неверно установлена временная зона (timezone) в Windows в следствии чего дистрибутив Linux в WSL также получает неверное время.
Время дистрибутив в WSL получает при своём запуске, то есть даже если вы впоследствии исправили время в Windows, в запущенных ранее дистрибутивах WSL по-прежнему время будет неправильным и ошибка сохранится.
Для исправления, как уже было сказано, начать нужно с установки правильного времени и правильной временной зоны в хостовом компьютере Windows.
Затем вам нужно использовать один из следующих способов:
1. Можно выключить и заново запустить все дистрибутивы Linux, для этого выполните команду:
wsl —shutdown
2. Другой способ, внутри дистрибутива Linux выполните команду:
sudo hwclock --hctosys
Эта команда получает последнее время от RTC вашей машины Windows и использует его для установки системного времени в Linux.
Вновь попробуйте сделать обновление:
sudo apt update && sudo apt full-upgrade -y
Как можно убедиться по скриншоту, в этот раз обновление началось без ошибок: