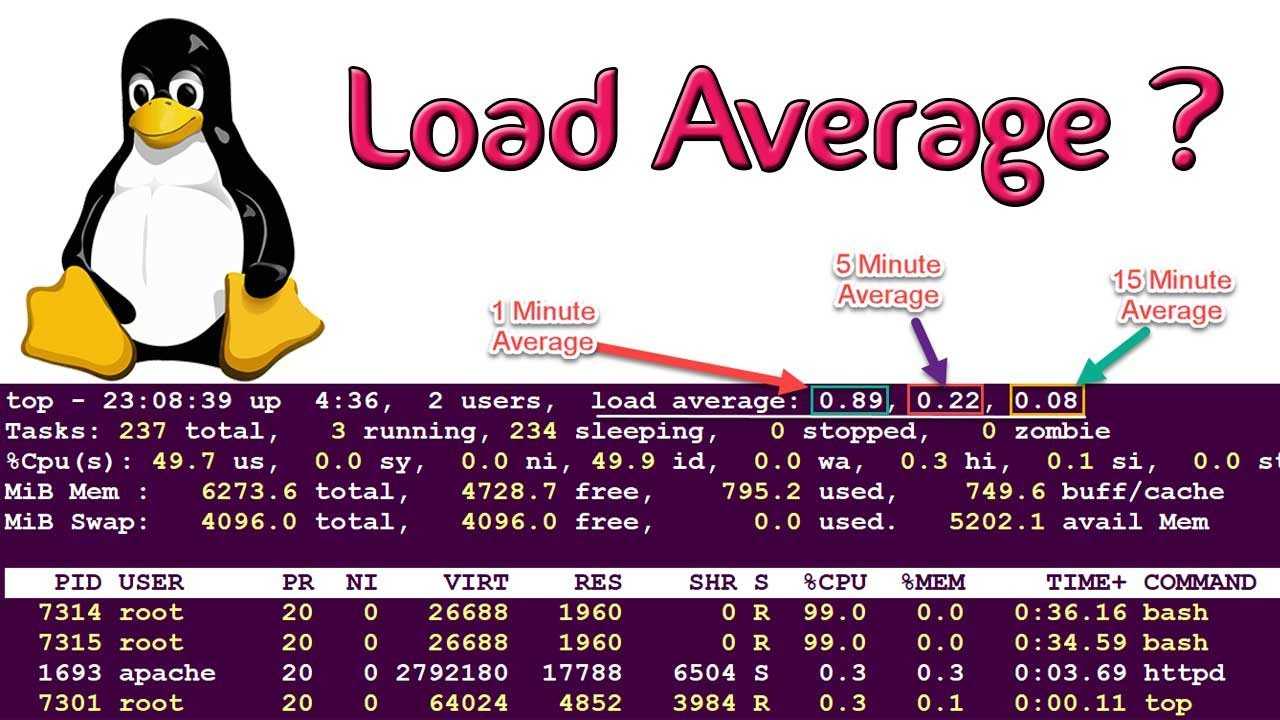
Understanding Load Average in Linux
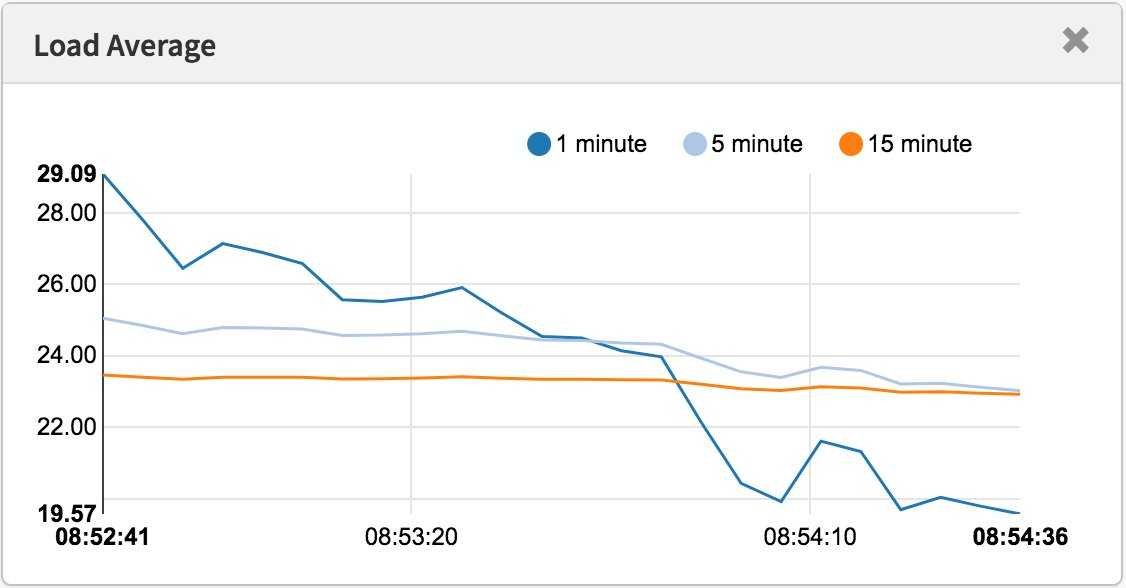
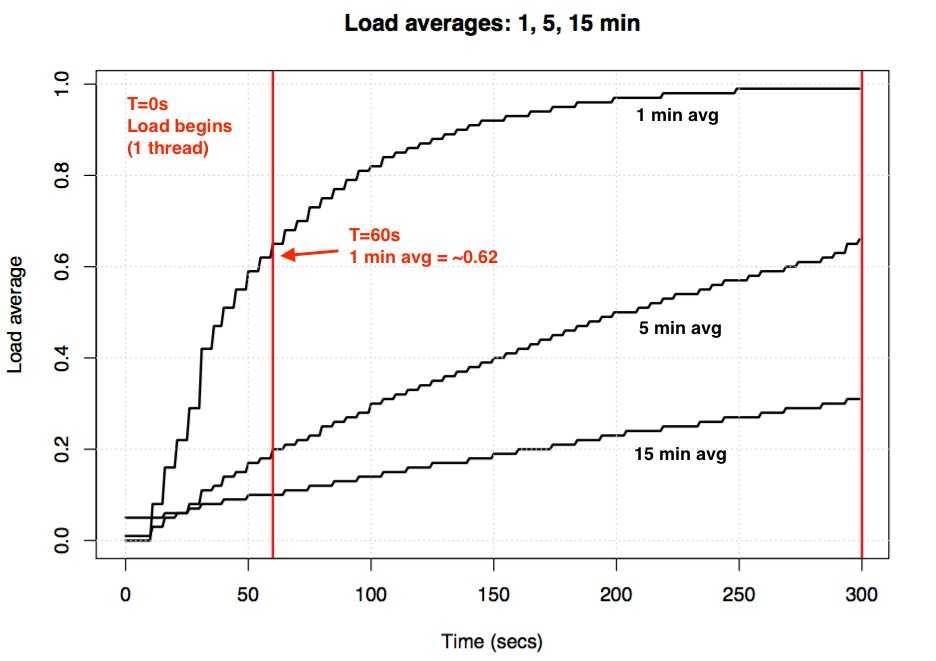
At first, this extra layer of detail seems unnecessary if you simply want to know the current state of CPU load in your system. But since the averages of three time periods are given, rather than an instant measurement, you can get a more complete idea of the change of system load over time in a single glance of three numbers
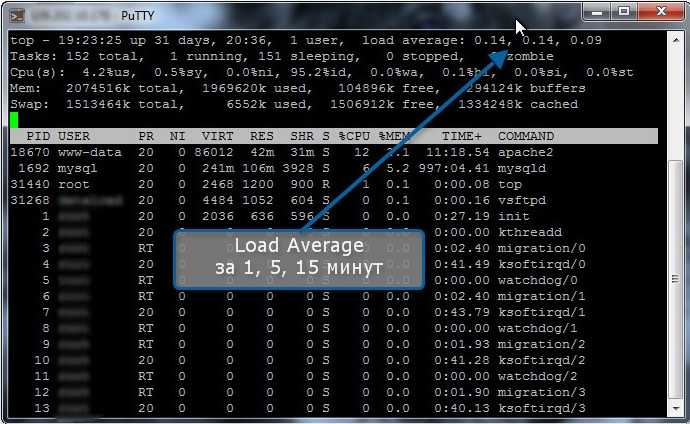
Displaying the load average is simple. On the command line, you can use a variety of commands. I simply use the “w” command:
root@virgo ~# w21:08:43 up 38 days, 4:34, 4 users, load average: 3.11, 2.75, 2.70
The rest of the command will display who’s logged on and what they’re executing, but for our purposes this information is irrelevant so I’ve clipped it from the above display.
In an ideal system, no process should be held up by another process (or thread), but in a single processor system, this occurs when the load goes above 1.00.
The words “single processor system” are incredibly important here. Unless you’re running an ancient computer, your machine probably has multiple CPU cores. In the machine I’m on, I have 16 cores:
root@virgo ~# nproc16
In this case, a load average of 3.11 is not alarming at all. It simply means that a bit more than three processes were ready to execute and CPU cores were present to handle their execution. On this particular system, the load would have to reach 16 to be considered at “100%”.
To translate this to a percent-based system load, you could use this simple, if not obtuse, command:
cat procloadavg | cut -c 1-4 | echo «scale=2; ($(</dev/stdin)/`nproc`)*100» | bc -l
This command sequences isolates the 1-minute average via cut and echos it, divided by the number of CPU cores, through bc, a command-line calculator, to derive the percentage.
This value is by no means scientific but does provide a rough approximation of CPU load in percent.
A Minute to Learn, a Lifetime to Master
In the previous section I put the “100%” example of a load of 16.0 on a 16 CPU core system in quotes because the calculation of load in Linux is a bit more nebulous than Windows. The system administrator must keep in mind that:
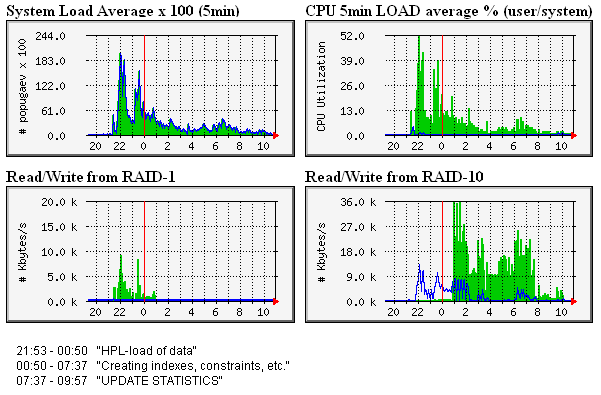
- Load is expressed in waiting processes and threads
- It is not an instantaneous value, rather an average, and
- It’s interpretation must include the number of CPU cores, and
- May over-inflate I/O waits like disk reads
Because of this, getting a handle of CPU load on a Linux system is not entirely an empirical matter. Even if it were, CPU load alone is not an adequate measurement of overall system resource utilization. As such, an experienced Linux administrator will consider CPU load in concert with other values such as I/O wait and the percentage of kernel versus system time.
I/O Wait
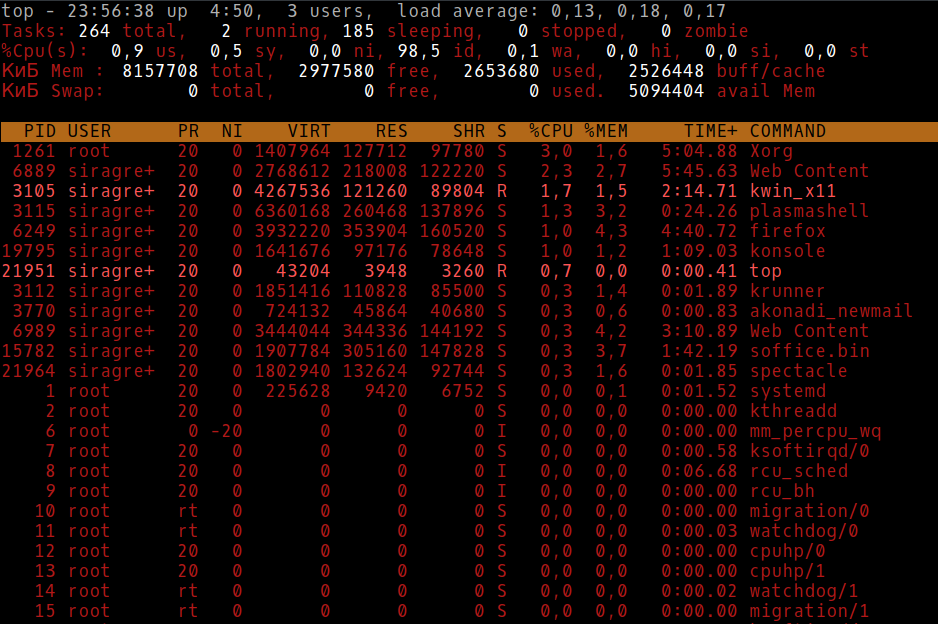
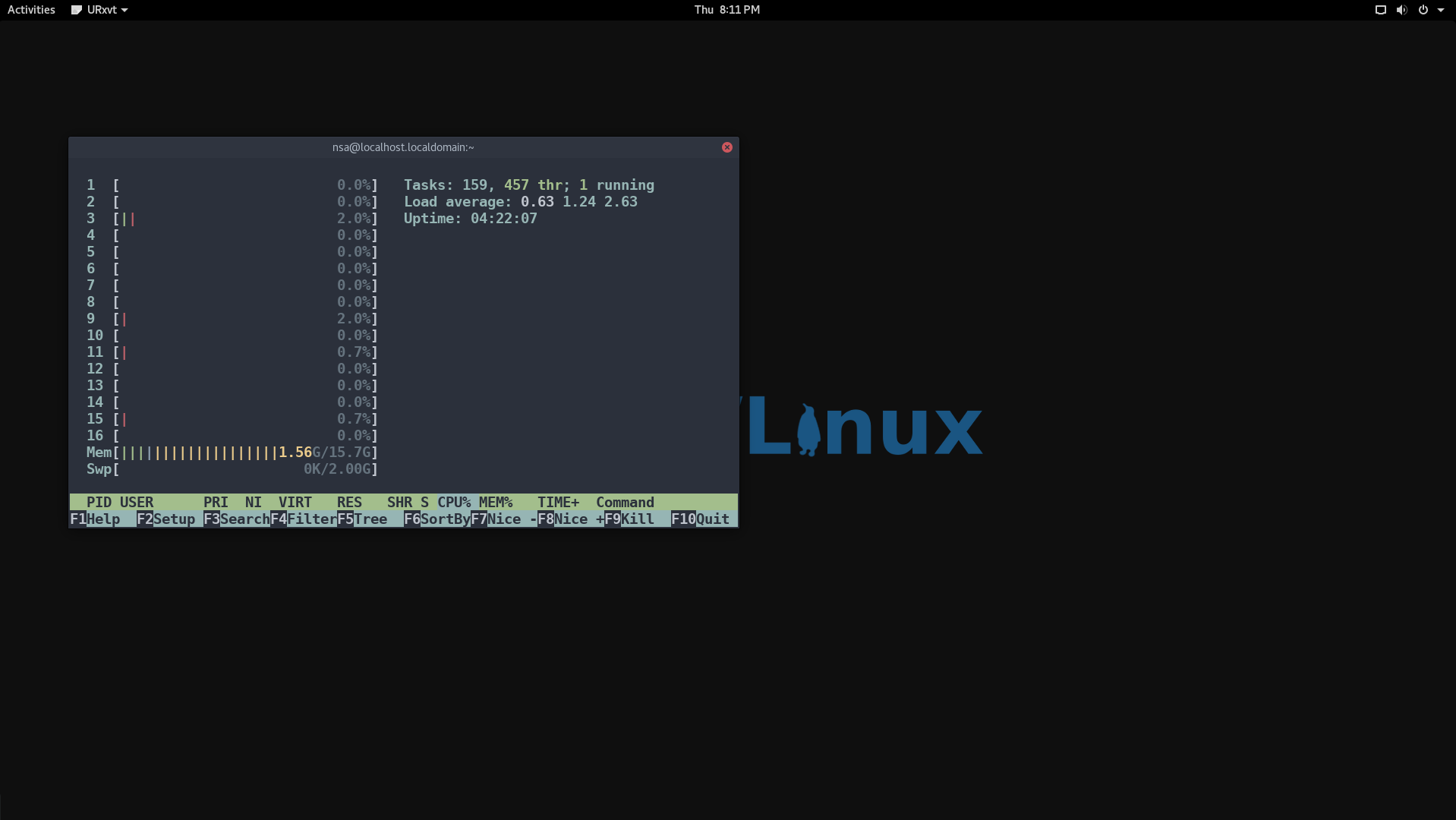
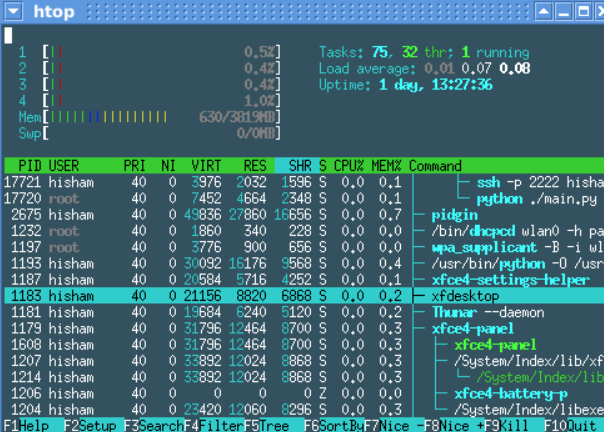
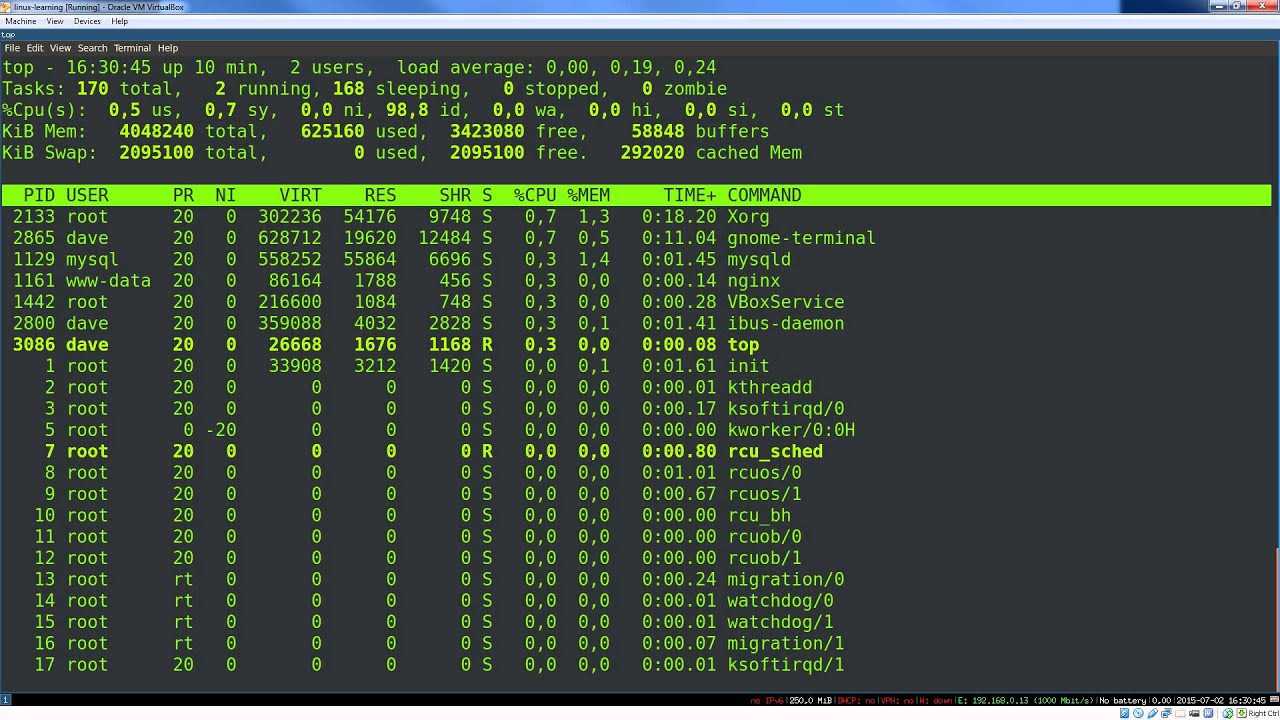
I/O wait is most easily seen via the “top” command:
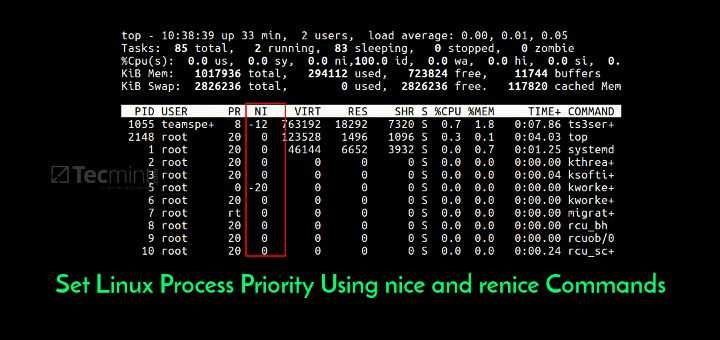
![]()
In the screenshot above I have highlighted the I/O wait value. This is a percentage of time that the CPU was waiting on input or output commands to complete. This is usually indicative of high disk activity. While a high wait percentage alone may not significantly degrade CPU-bound tasks, it will reduce I/O performance for other tasks and will make the system feel sluggish.
High I/O wait without any obvious cause might indicate a problem with a disk. Use the “dmesg” command to see if any errors have occurred.
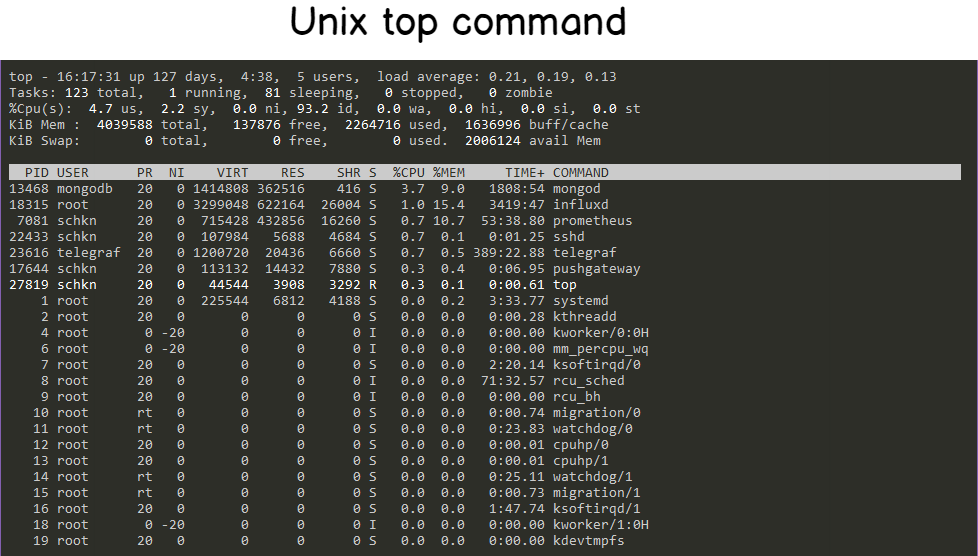
Kernel vs. System Time
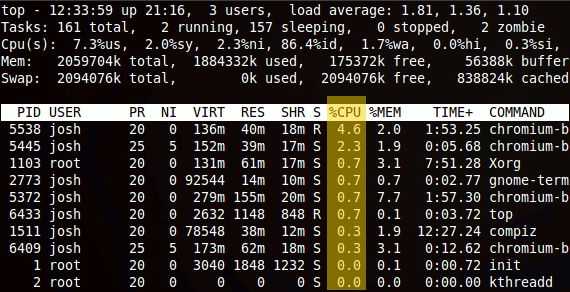
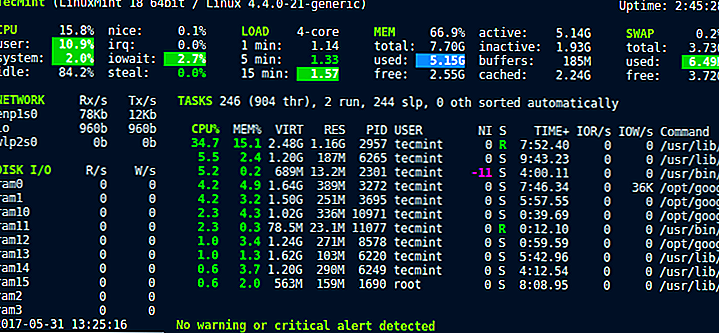
![]()
The above highlighted values represent the user and kernel (system) time. This is a breakdown of the overall consumption of CPU time by users (i.e. applications, etc.) and the kernel (i.e. interaction with system devices). Higher user time will indicate more CPU usage by programs where higher kernel time will indicate more system-level processing.
В поисках древнего патча для Linux
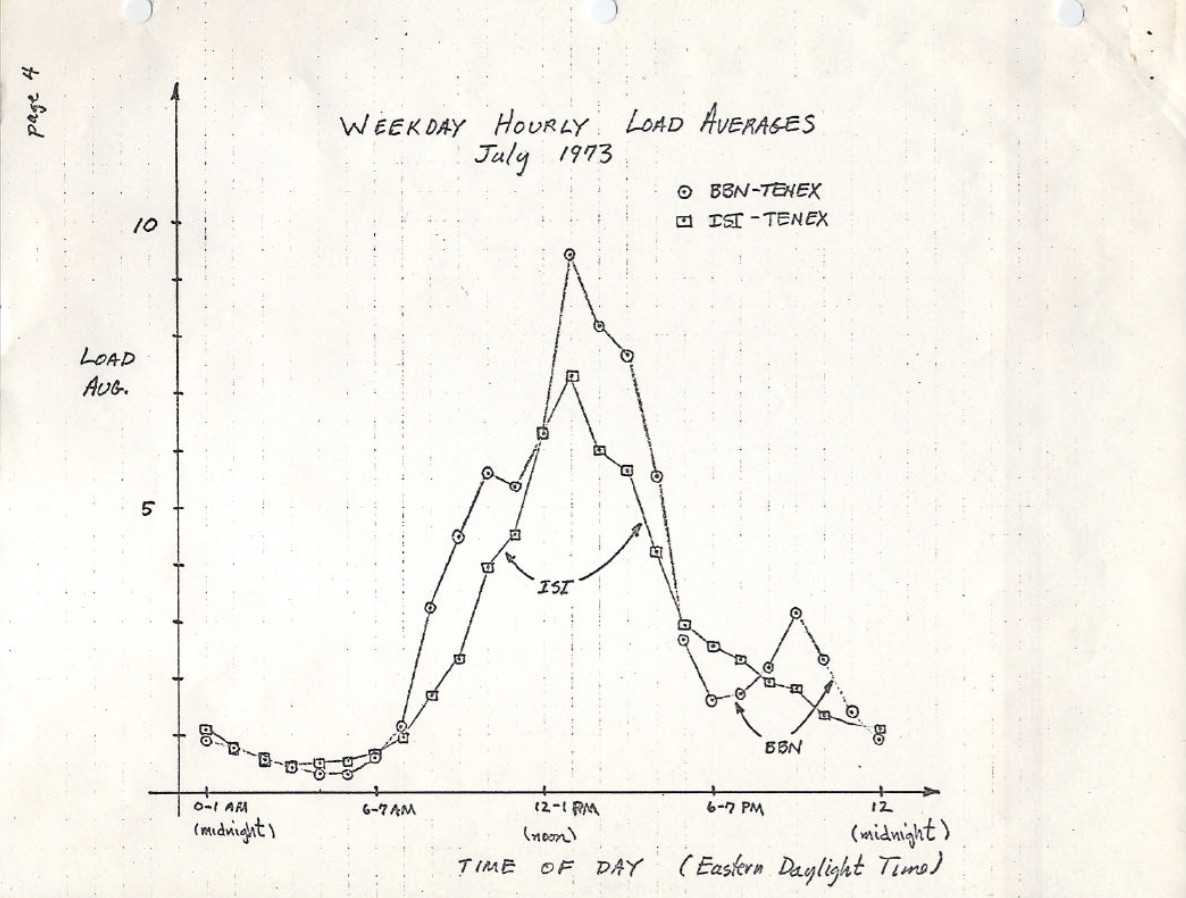
Легко понять, почему в Linux что-то меняется: просматриваешь историю git-коммитов для нужного файла и читаешь описания изменений. Я просмотрел историю на loadavg.c, но изменение, добавляющее неизменяемое состояние, датировано более ранним числом, чем файл, содержащий код из более раннего файла. Я проверил другой файл, но это ничего не дало: код «скакал» по разным файлам. Надеясь на удачу, я задампил по всему Github-репозиторию Linux, содержащему 4 Гб текста, и начал читать с конца, отыскивая место, где впервые появился этот код. Это мне тоже не помогло. Самое старое изменение в репозитории датировано 2005-м, когда Линус импортировал Linux 2.6.12-rc2, а искомое изменение было внесено ещё раньше.
Есть старинные репозитории Linux ( и ), но и в них отсутствует описание этого изменения. Стараясь найти хотя бы дату его внедрения, я изучил архив на kernel.org и обнаружил, что оно было в 0.99.15, а в 0.99.13 ещё не было. Однако версия 0.99.14 отсутствовала. Мне удалось её отыскать и подтвердить, что искомое изменение появилось в Linux 0.99.14, в ноябре 1993. Я надеялся, что мне поможет описание этого релиза, но и здесь я не нашёл объяснения:
Он упомянул лишь основные изменения, не связанные со средним значением нагрузки.
По дате мне удалось найти архивы почтовой рассылки kernel и конкретный патч, но более старое письмо было датировано аж июнем 1995:
Я начал ощущать себя проклятым. К счастью мне удалось обнаружить старые архивы почтовой рассылки linux-devel, вытащенные из серверного бэкапа, зачастую хранящиеся как архивы дайджестов. Я просмотрел более 6000 дайджестов, содержащих свыше 98 000 писем, из которых 30 000 относились к 1993 году. Но ничего не нашёл. Казалось, исходное описание патча потеряно навеки, и ответа на вопрос «зачем» мы уже не получим.
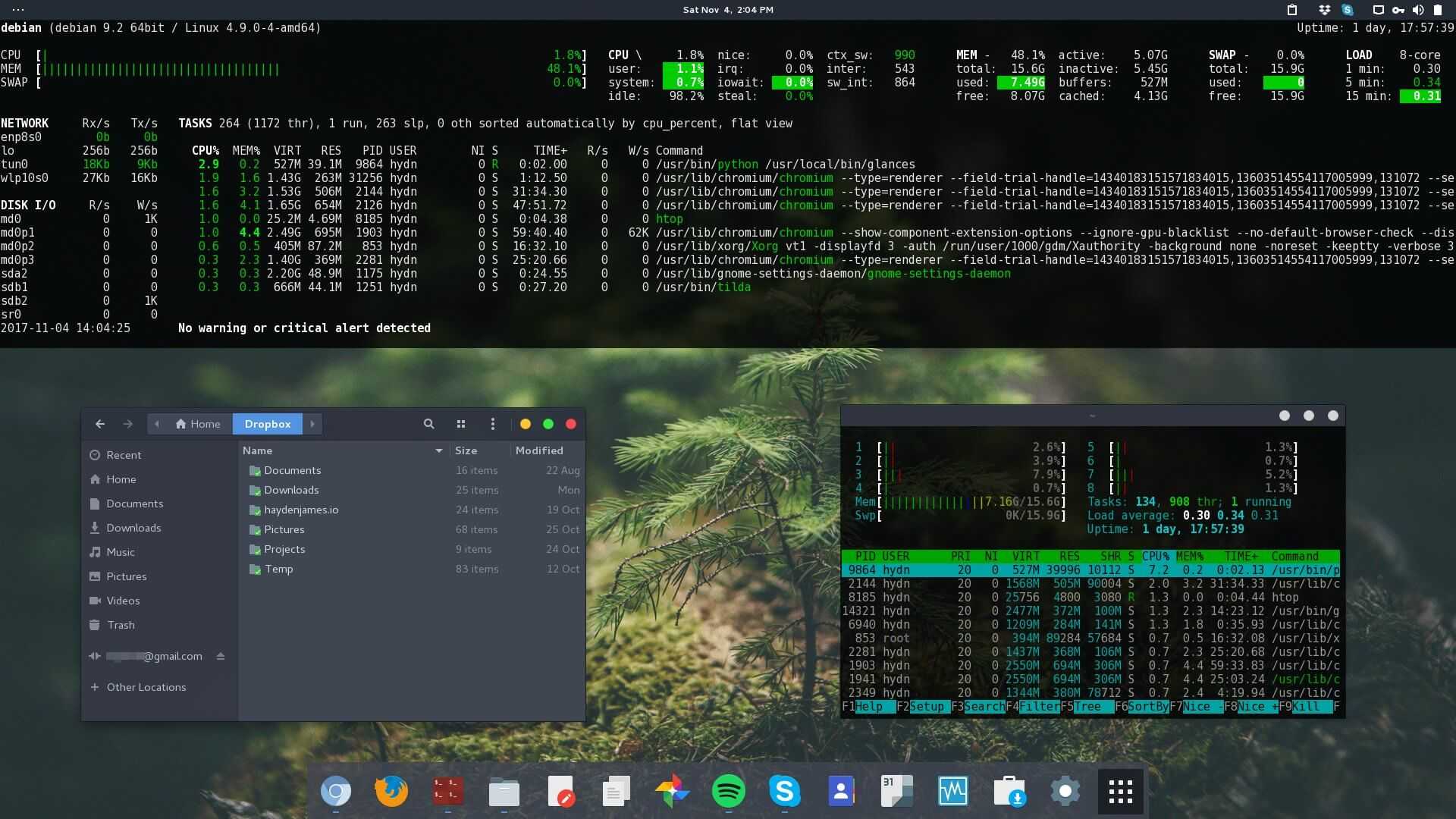
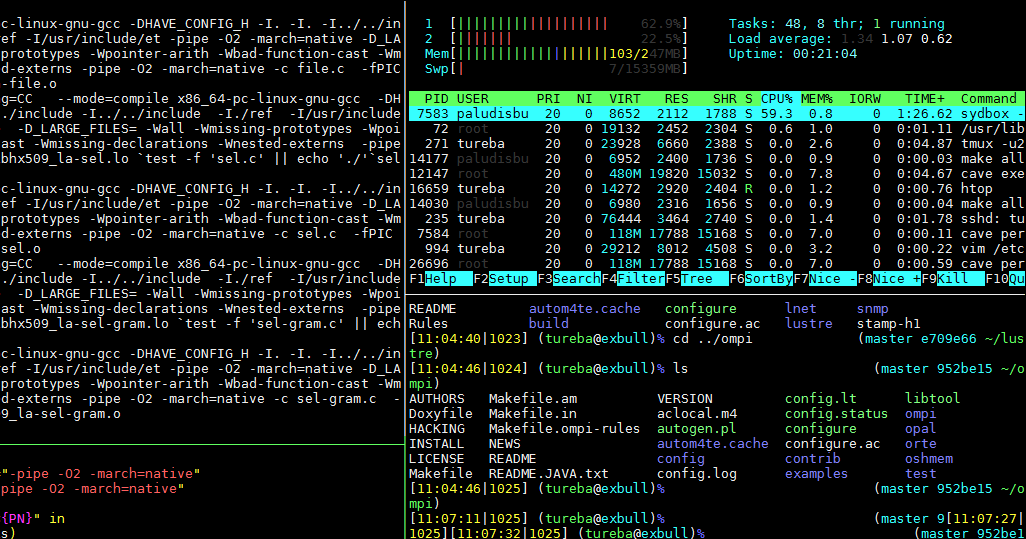
Более подходящие метрики
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
- использование каждого процессора (per-CPU utilization): например, используя .
- использование процессора для каждого процесса (per-process CPU utilization): например, и так далее.
- задержка очереди выполнения (диспетчера) для каждого потока (per-thread run queue (scheduler) latency): например, в /proc/PID/schedstats, delaystats, perf sched
- задержка очереди выполнения процессора (CPU run queue latency): например, в , , моём инструменте runqlat bcc.
- длина очереди выполнения процессора (CPU run queue length): например, используя vmstat 1 и колонку ‘r’, или мой инструмент .
Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция () стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
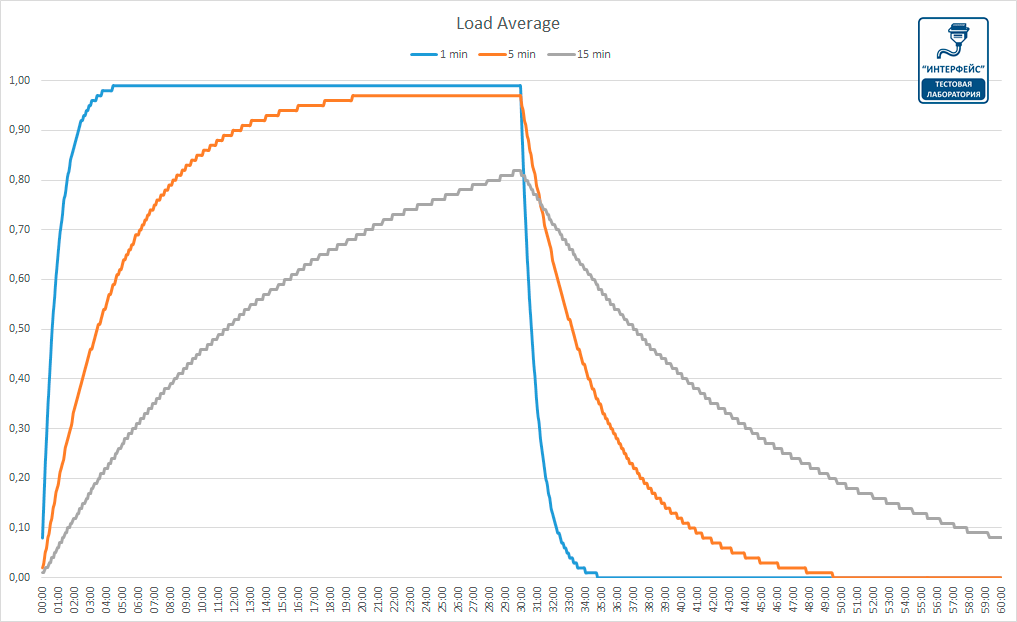
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация
Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим