Отобразить список правил с номерами строк.
Примерный вывод:
Chain INPUT (policy DROP) num target prot opt source destination 1 DROP all -- 0.0.0.0/0 0.0.0.0/0 state INVALID 2 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 3 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 4 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 Chain FORWARD (policy DROP) num target prot opt source destination 1 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 2 DROP all -- 0.0.0.0/0 0.0.0.0/0 state INVALID 3 TCPMSS tcp -- 0.0.0.0/0 0.0.0.0/0 tcp flags:0x06/0x02 TCPMSS clamp to PMTU 4 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED 5 wanin all -- 0.0.0.0/0 0.0.0.0/0 6 wanout all -- 0.0.0.0/0 0.0.0.0/0 7 ACCEPT all -- 0.0.0.0/0 0.0.0.0/0 Chain OUTPUT (policy ACCEPT) num target prot opt source destination Chain wanin (1 references) num target prot opt source destination Chain wanout (1 references) num target prot opt source destination
Вы можете использовать номера строк для того, чтобы добавлять новые правила.
Как определиться с назначением файрвола
Перед тем, как заниматься настройкой утилиты, потребуется разобраться с ее предназначением, а именно – действующими цепочками правил, то есть то, что она будет делать по умолчанию. Как отреагировать, когда запрашиваемые соединения не подходят ни к одному правилу?
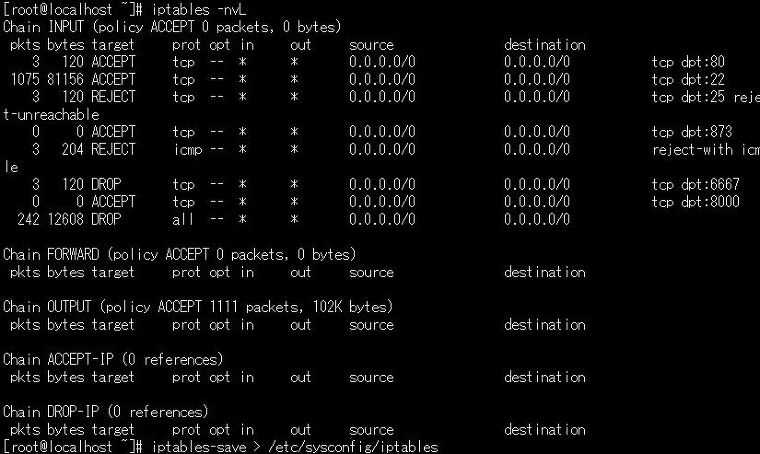
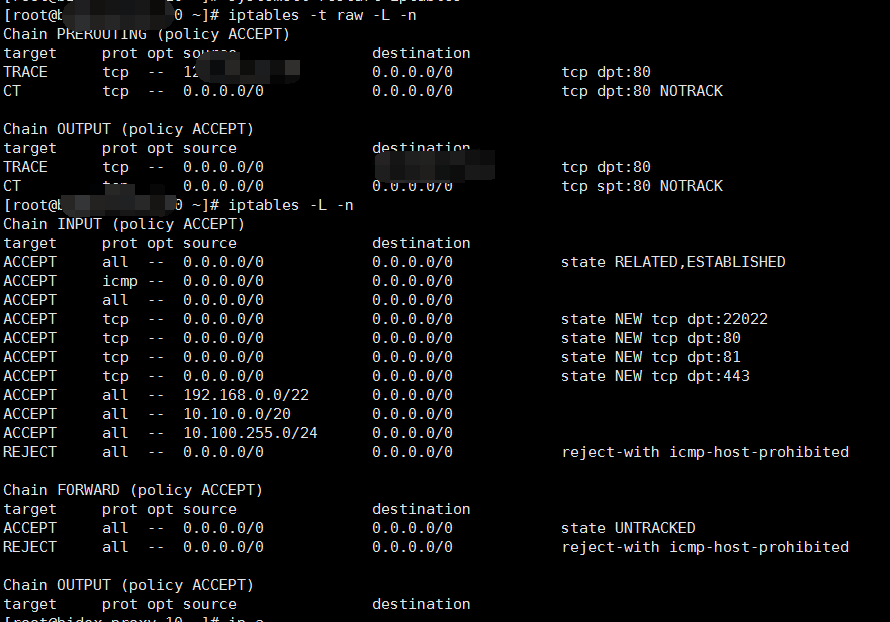
Для начала потребуется понять, какие из настроек межсетевого экрана уже установлены. Для этого применяется команда –L:
Скриншот №1. Настройки межсетевого экрана
Для четкого и понятного вывода информации можно воспользоваться дополнительной командой «grep». В итоге мы получаем тройку цепочек, у каждой из которых стоит разрешение приема трафика. Подобные правила предпочитают устанавливать при стандартной настройке.
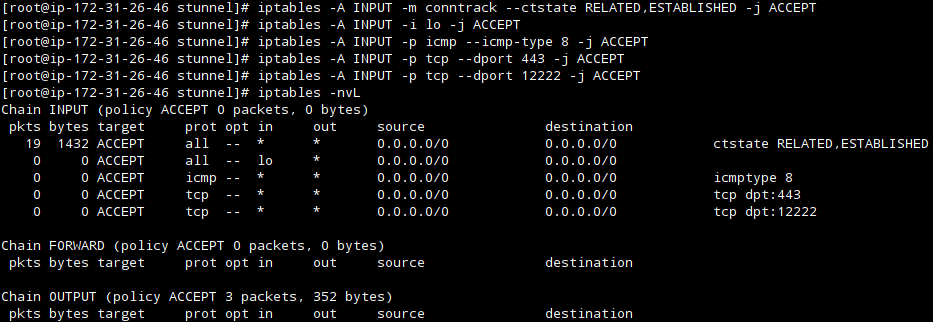
Если в процессе эксплуатации Iptables конфигурация была кем-то изменена, значения могут стоять другие. Проверить это можно за пару секунд, достаточно ввести команды:
Правильнее будет заблаговременно разрешить все входящие/исходящие подключения, после чего выставлять запреты под конкретный порт и айпи-адрес.
Можно поступить диаметрально противоположным методом: установить запрет на все соединения, после чего давать разрешения только некоторым из них. Это можно реализовать таким способом:
Что такое Iptables?
Операционные системы Linux, на которых чаще всего и функционируют серверы (виртуальные машины), имеют встроенный инструмент защиты – программный фильтр Iptables. Все сетевые пакеты идут через ядро приложения и проходят проверку на безопасность для компьютера. Сценария всего два – или данные передаются дальше на обработку, или полностью блокируются.
Виды пакетов
Информационные пакеты фильтруются исходя из назначения. Под контроль попадают все данные, входящие на сервер, исходящие из него или проходящие через него как маршрутизатор (например, если компьютер используется в качестве прокси). Такой подход создает сплошной защитный экран (файрвол), через который практически нереально проникнуть с вредоносными целями.
Описания пакетов:
- Input. Обрабатываются входящие подключения вроде подключения по протоколу SSH или при отправке на веб-сайт каких-либо файлов.
- Forward. Цепочка формируется при активации проходящего соединения, когда информация предназначена «третьему» компьютеру, а текущий сервер выполняет роль маршрутизатора.
- Output. Исходящие пакеты данных, например, при запуске какого-либо сайта в браузере или при проверке скорости соединения и доступности PING.
В реальной работе сервера постоянно формируется минимум два вида пакетов – Input и Output. Ведь на каждый запрос пользователя положено дать ответ: сначала о поступлении данных на сервер, а затем и о результате обработки. Если «принято решение» отказать в доступе, об этом также сообщается на удаленное рабочее место. Иначе запрос зависнет, и пользователь будет видеть пустой экран.
Правила и действия Iptables
На каждый тип пакетов распространяется определенный набор правил, и их следует учитывать при настройке программы Iptables. Большая часть запросов проходит в виде последовательных цепочек в различных комбинациях. Если ошибиться на этом этапе, приложение будет функционировать со сбоями и блокировать «полезные» запросы.
Примеры действий:
- ACCEPT – пропустить пакет данных далее по цепочке;
- DROP – полностью удалить пакет;
- REJECT – отклонить запрос и направить пользователю ответ с информацией об этом;
- LOG – инициируется запись в лог-файл об обработанном пакете;
- QUEUE – отправка данных на компьютер пользователя.
Правила проверки устанавливаются в зависимости от характера соединения. Возможен мониторинг IP-адреса, порта подключения, отправителя, заголовка. Если пакет не проходит хотя бы по одному критерию, осуществляется действие ACCEPT (сквозное пропускание пакета, который не требуется блокировать файрволом). Фильтрация возможна на двух этапах:
- prerouting – система только получила пакет, и нет команды «что с ним делать»: обрабатывать на сервере, возвращать пользователю или пропускать насквозь;
- postroutnig – обработка после оценки «пункта назначения».
Советы и рекомендации
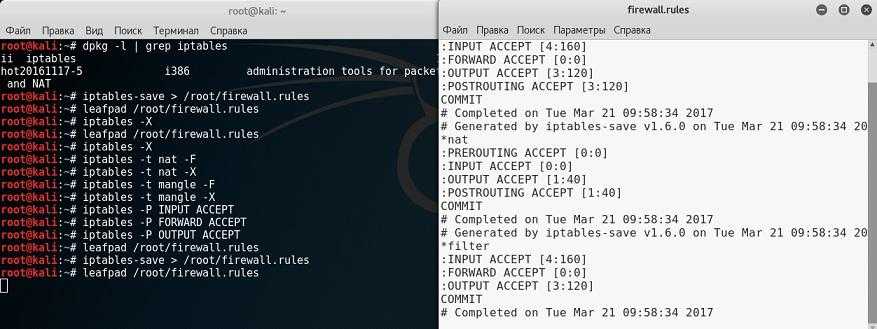
Сохранение текущего набора правил
Вывод команды можно использовать в качестве входных данных для других команд. Текущий набор правил можно сохранить в файл, а позже — загрузить их из него.
# nft -s list ruleset | tee название_файла
Примечание: Команда не выводит определения переменных. Если в файле есть какие-либо переменные, то в выводе команды вы их не увидите — все переменные будут заменены на значения.
Настройка межсетевого экрана
См. также Настройка межсетевого экрана.
Одиночная машина
Сотрите текущий набор правил:
# nft flush ruleset
Добавьте таблицу:
# nft add table inet my_table
Добавьте базовые цепочки input, forward и output. Политика для входящих и пересылаемых пакетов должна быть drop. Политика для исходящих пакетов — accept.
# nft add chain inet my_table my_input '{ type filter hook input priority 0 ; policy drop ; }'
# nft add chain inet my_table my_forward '{ type filter hook forward priority 0 ; policy drop ; }'
# nft add chain inet my_table my_output '{ type filter hook output priority 0 ; policy accept ; }'
Добавьте две обычные цепочки, которые будут обрабатывать пакеты протоколов TCP и UDP:
# nft add chain inet my_table my_tcp_chain # nft add chain inet my_table my_udp_chain
Разрешите related и established трафик:
# nft add rule inet my_table my_input ct state related,established accept
Разрешите трафик на петлевой интерфейс:
# nft add rule inet my_table my_input iif lo accept
Заблокируйте invalid трафик:
# nft add rule inet my_table my_input ct state invalid drop
Разрешите пакеты ICMP и IGMP:
# nft add rule inet my_table my_input meta l4proto ipv6-icmp icmpv6 type '{ destination-unreachable, packet-too-big, time-exceeded, parameter-problem, mld-listener-query, mld-listener-report, mld-listener-reduction, nd-router-solicit, nd-router-advert, nd-neighbor-solicit, nd-neighbor-advert, ind-neighbor-solicit, ind-neighbor-advert, mld2-listener-report }' accept
# nft add rule inet my_table my_input meta l4proto icmp icmp type '{ destination-unreachable, router-solicitation, router-advertisement, time-exceeded, parameter-problem }' accept
# nft add rule inet my_table my_input ip protocol igmp accept
Новый UDP-трафик будет передаваться цепочке :
# nft add rule inet my_table my_input meta l4proto udp ct state new jump my_udp_chain
Новый TCP-трафик будет передаваться цепочке :
# nft add rule inet my_table my_input 'meta l4proto tcp tcp flags & (fin|syn|rst|ack) == syn ct state new jump my_tcp_chain'
Заблокировать весь трафик, который не обрабатывается другими правилами:
# nft add rule inet my_table my_input meta l4proto udp reject # nft add rule inet my_table my_input meta l4proto tcp reject with tcp reset # nft add rule inet my_table my_input counter reject with icmpx type port-unreachable
В этом месте необходимо выбрать, какие порты будут оставаться открытыми для входящих соединений, обрабатываемых цепочками и . Например, открыть соединения для веб-сервера:
# nft add rule inet my_table my_tcp_chain tcp dport 80 accept
Разрешить HTTPS-соединения для веб-сервера на порте 443:
# nft add rule inet my_table my_tcp_chain tcp dport 443 accept
Разрешить SSH-трафик на порт 22:
# nft add rule inet my_table my_tcp_chain tcp dport 22 accept
Разрешить входящие DNS-запросы:
# nft add rule inet my_table my_tcp_chain tcp dport 53 accept # nft add rule inet my_table my_udp_chain udp dport 53 accept
В конце не забудьте сохранить набор правил, чтобы они стали постоянными.
Предотвращение атак перебором
Sshguard может обнаруживать атаки перебором и модифицировать сетевые экраны, временно помещая IP-адреса в чёрный список. Описание настройки nftables для работы с sshguard можно найти в статье .
Журналирование трафика
Действие позволяет вести журнал пакетов. Простейшее правило для сохранения информации обо всём поступающем трафике:
# nft add rule inet filter input log
Какие бывают правила
Для легкой работы с файрволом разработана тройка основных правил (команд):
1.Input.
Правило применяется, когда необходимо контролировать входящий трафик. Например, когда юзер подключается к удаленному серверу по протоколу Secure Shell, файрвол начнет сравнивать его айпи с другими айпи из своего списка. В зависимости от результата, то есть от наличия в списке запретов, доступ пользователю будет открыт или закрыт.
2.Forward.
Правило применяется в случаях, когда необходимо проверить входящее сообщение, проходящее через данный компьютер. Например, маршрутизатор постоянно пересылает сообщения к адресату от сетевых пользователей или приложений. Зачастую данное правило не используется, если только юзер целенаправленно не настраивает маршрутизацию на своем устройстве.
3.Output.
Правило применяется к исходящим соединениям. Например, юзер хочет проверить пинг к одному из заданных сайтов – утилита вновь сверится со своими правилами из списка и определит, как поступить при пинге веб-сайта: разрешить или запретить.
Примечание:
Делая ping к внешнему хосту, машина не только отправляет пакет, но и дожидается обратного ответа. Поэтому, настраивая Iptables, не нужно забывать о наличии двухсторонних коммуникаций и запрещать подключение к серверам через протокол SSH.
Предварительные требования
Это учебное руководство предполагает использование сервера Linux с установленной командой и наличие у пользователя привилегий .
Если вам нужна помощь с данной начальной настройкой, воспользуйтесь нашим руководством по начальной настройке сервера Ubuntu 20.04. Вы также можете воспользоваться руководствами для Debian и CentOS
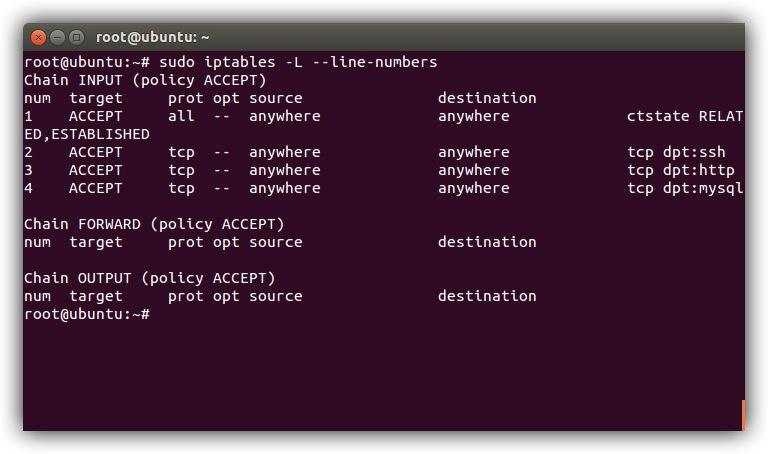
Давайте сначала рассмотрим, как просмотреть существующий список правил. Существует два различных способа просмотра действующих правил Iptables: в форме таблицы или списка спецификаций правил. Оба метода предоставляют приблизительно одну и ту же информацию в разных форматах.
Действия с соединениями
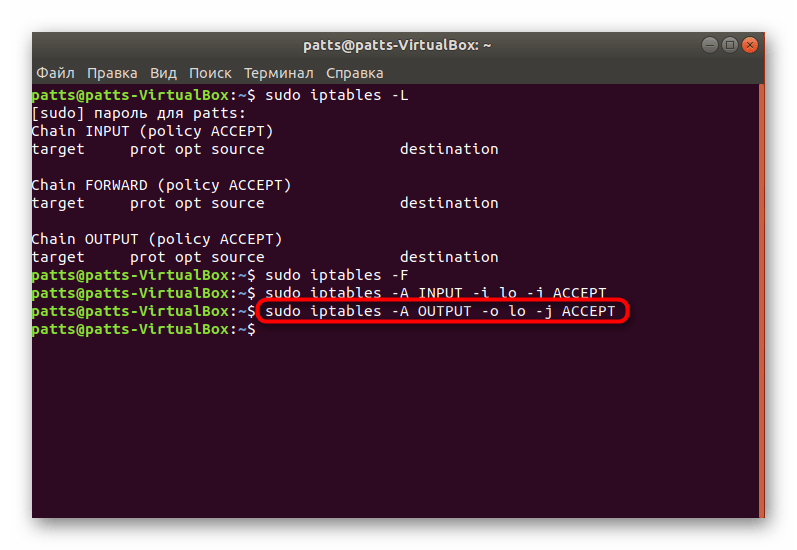
Перед настройкой фильтра проверьте, какие условия выполняются по умолчанию. Если соединение не подпадает под существующие правила, будут выполниться действия, заданные по умолчанию. Узнать уже сконфигурированные правила можно командой .
В идеале все три цепочки должны разрешать приём трафика. Это можно задать вручную так:
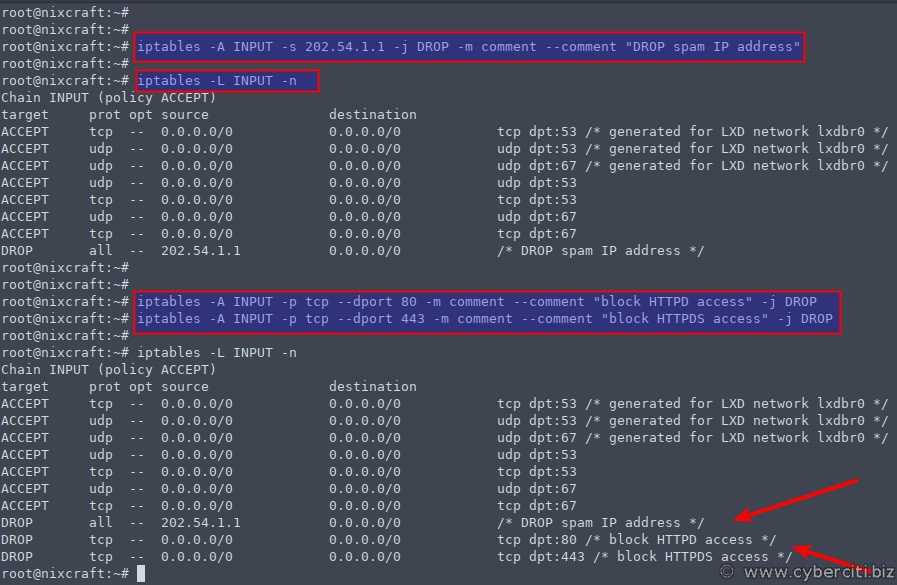
Можно запретить весь трафик, чтобы потом выборочно разрешить какой-то. Для этого используйте команды:
При перезапуске iptables все внесённые изменения пропадут. Сохраните изменения в цепочках правил, выполнив команду для Ubuntu или для Red Hat/CentOS.
Включение логов
Во время настройки полезно включить логи, чтобы мониторить заблокированные пакеты и выяснять, почему отсутствует доступ к необходимым сервисам, которые мы вроде бы уже открыли. Я отправляю все заблокированные пакеты в отдельные цепочки (block_in, block_out, block_fw), соответствующие направлению трафика и маркирую в логах каждое направление. Так удобнее делать разбор полетов. Добавляем следующие правила в самый конец скрипта, перед сохранением настроек:
Все заблокированные пакеты вы сможете отследить в файле /var/log/messages.
После того, как закончите настройку, закомментируйте эти строки, отключив логирование. Обязательно стоит это сделать, так как логи очень быстро разрастаются. Практического смысла в хранении подобной информации лично я не вижу.
Запуск утилиты Iptables
Перед активацией приложение требуется установить из стандартного репозитория Linux. Так, для инсталляции в Ubuntu подойдет команда:
$ sudo apt install iptables
В дистрибутиве, базируемом на ядре Fedora, она выглядит несколько иначе:
$ sudo yum install iptables
Общий синтаксис запуска программы выглядит следующим образом:
$ iptables -t таблица действие цепочка дополнительные_параметры
Перечень основных действий, для выполнения которых используется Iptables:
- -A – добавить правило в цепочку;
- -C – проверить применяемые правила;
- -D – удалить текущее правило;
- -I – вставить правило с указанным номером;
- -L – вывести правила текущей цепочки;
- -S – вывести все активные правила;
- -F – очистить все правила;
- -N – создать цепочку;
- -X – удалить цепочку;
- -P – установить действие «по умолчанию».
В качестве дополнительных параметров используются опции:
- -p – вручную установить протокол (TCP, UDP, UDPLITE, ICMP, ICMPv6, ESP, AH, SCTP, MH);
- -s – указать статичный IP-адрес оборудования, откуда отправляется пакет данных;
- -d – установить IP получателя;
- -i – настроить входной сетевой интерфейс;
- -o – то же самое в отношении исходящего интерфейса;
- -j – выбрать действие при подтверждении правила.
Закрыть или открыть стандартные порты.
Заменить ACCEPT на DROP, чтобы заблокировать порт.
## ssh tcp port 22 ##
iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
# cups (printing service) udp/tcp port 631 для локальной сети ##
iptables -A INPUT -s 192.168.1.0/24 -p udp -m udp --dport 631 -j ACCEPT iptables -A INPUT -s 192.168.1.0/24 -p tcp -m tcp --dport 631 -j ACCEPT
## time sync via NTP для локальной сети (udp port 123) ##
iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p udp --dport 123 -j ACCEPT
## tcp port 25 (smtp) ##
iptables -A INPUT -m state --state NEW -p tcp --dport 25 -j ACCEPT
#dns server ports ##
iptables -A INPUT -m state --state NEW -p udp --dport 53 -j ACCEPT iptables -A INPUT -m state --state NEW -p tcp --dport 53 -j ACCEPT
## http/https www server port ##
iptables -A INPUT -m state --state NEW -p tcp --dport 80 -j ACCEPT iptables -A INPUT -m state --state NEW -p tcp --dport 443 -j ACCEPT
## tcp port 110 (pop3) ##
iptables -A INPUT -m state --state NEW -p tcp --dport 110 -j ACCEPT
# tcp port 143 (imap) ##
iptables -A INPUT -m state --state NEW -p tcp --dport 143 -j ACCEPT
## Samba file server для локальной сети ##
iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 137 -j ACCEPT iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 138 -j ACCEPT iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 139 -j ACCEPT iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 445 -j ACCEPT
## proxy server для локальной сети ##
iptables -A INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 3128 -j ACCEPT
## mysql server для локальной сети ##
iptables -I INPUT -p tcp --dport 3306 -j ACCEPT
Сброс всех правил, удаление всех цепочек и разрешение любого трафика
Из этого раздела вы узнаете, как выполнить сброс всех правил брандмауэра, таблиц и цепочек, чтобы разрешить прием любого сетевого трафика.
Примечание: результатом этих действий станет полное отключение вашего брандмауэра. Вам следует выполнять описанные в данном разделе действия только в том случае, если вы хотите начать настройку вашего брандмауэра с нуля.
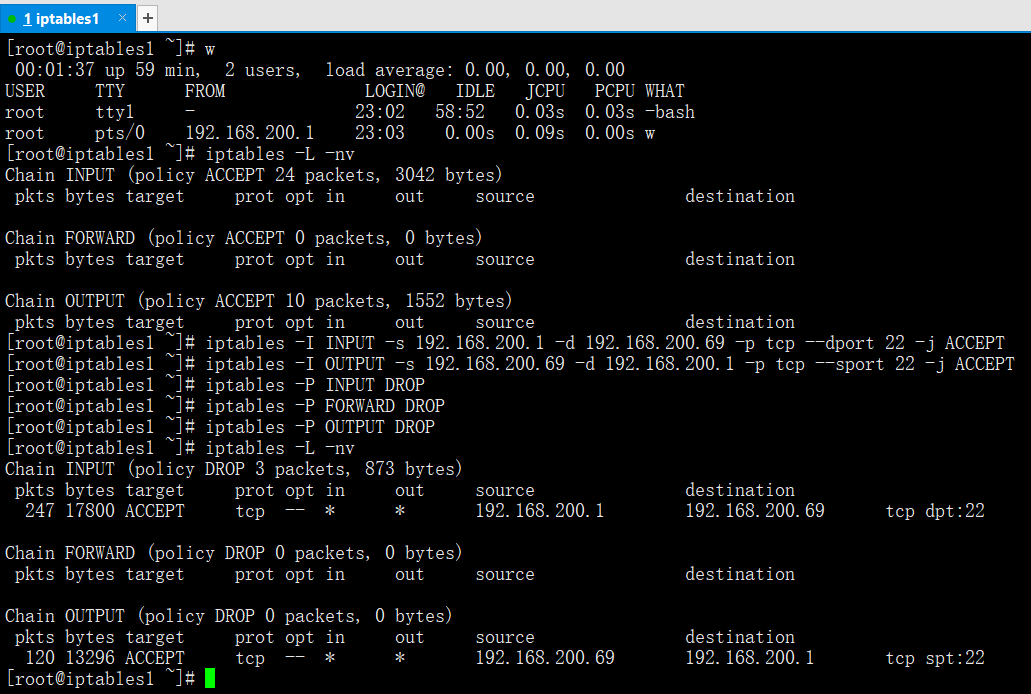
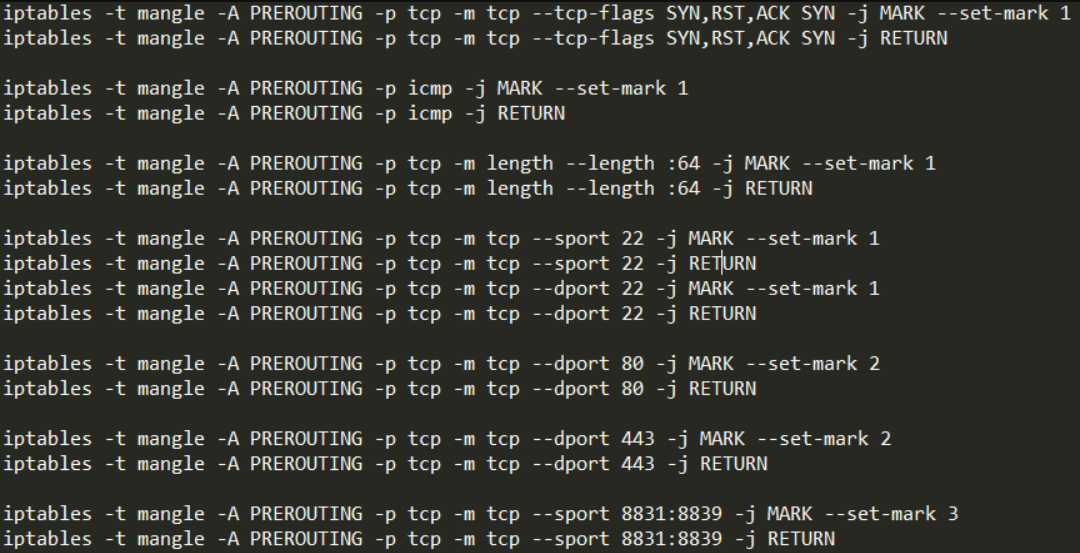
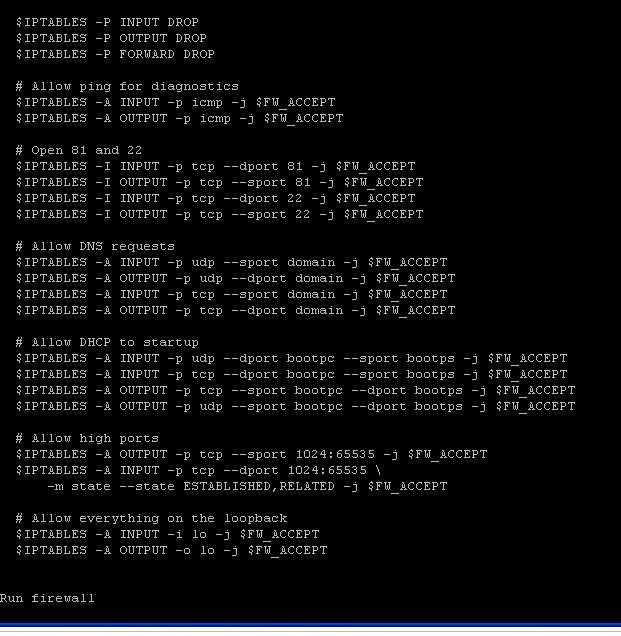
Сначала задайте в качестве используемой по умолчанию политики для каждой встроенной цепочки. Главная причина этого шага состоит в том, чтобы гарантировать, что вы не заблокируете собственный доступ к вашему серверу через SSH:
Затем выполните сброс таблиц и , сбросьте все цепочки () и удалите все цепочки, не используемые по умолчанию ():
Теперь ваш брандмауэр будет принимать любой сетевой трафик. Если вы сейчас попробуете вывести список ваших правил, то увидите, что он пуст, и остались только три используемые по умолчанию цепочки (, и ).
Как посмотреть правила iptables
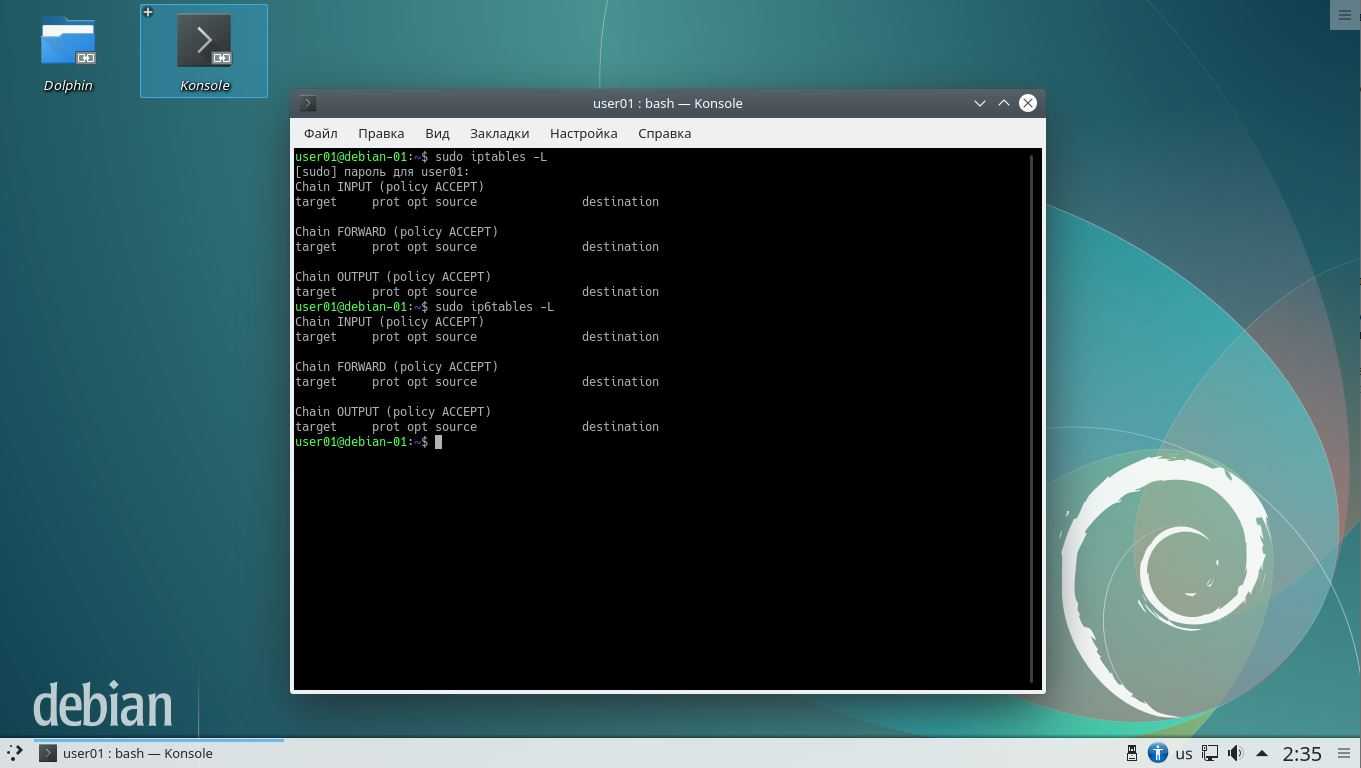
В данном случае для демонстрации возможностей iptables используется операционная система Debian 10.2. Для возможности выполнения команды iptables необходимо, чтобы пользователю были предоставлены привилегии суперпользователя с помощью команды sudo. В связи с этим все команды будут выглядеть как sudo iptables или sudo ip6tables для IPv6.
Примечание: Для того, чтобы пользователю было позволено предоставлять привилегии суперпользователя, этого пользователя надо добавить в файл sudoers с помощью специального редактора visudo. Посмотрим на скриншот с результатом выполнения команды:
![]()
Существуют две версии утилиты для настройки брандмауэра Linux: iptables и ip6tables. Iptables используется для протокола IPv4, а ip6tables для протокола IPv6. Соответственно команда вывести все цепочки правил для межсетевого экрана имеет два варианта синтаксиса.
Для протокола IPv4:
Для протокола IPv6:
В дальнейшем рассмотрим только вариант для протокола IPv4, вариант для протокола IPv6 использует такой же синтаксис.
Выводимая на экран информация разбита на столбцы и строки. У каждого столбца свое наименование. С помощью дополнительных параметров команды sudo iptables -L можно добавлять дополнительные столбцы в выводимой таблице правил iptables. Рассмотрим название столбцов в стандартном выводе sudo iptables -L:
- target – выполняемое действие с пакетом при соответствии его данному правилу
- prot – протокол передачи данных, при котором применяется данное правило
- opt – дополнительные опции для правила
- source – IP адрес, подсеть, домен узла источника пакета, попадающего под выполнение данного правила
- destination – IP адрес, подсеть, домен узла назначения пакета, попадающего под выполнение данного правила
1. Список правил из цепочки
Команда чтобы вывести на экран конкретную цепочку правил выглядит следующим образом:
sudo iptables
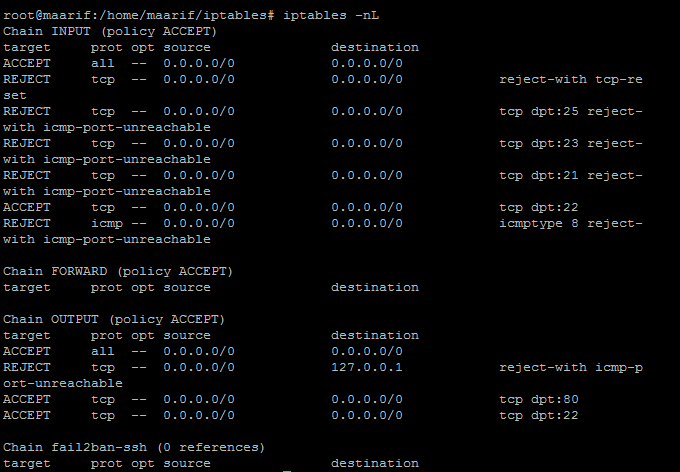
Например просмотр правил iptables из цепочки OUTPUT:
![]()
2. Список правил из таблицы
По умолчанию выводится содержимое таблицы фильтрации пакетов filter. Команда вывода содержимого конкретно указанной таблицы выглядит следующим образом:
sudo iptables
Например:
![]()
Вот список всех таблиц правил iptables:
- filter – таблица по умолчанию. Используется для фильтрации пакетов. Содержится в цепочках INPUT, FORWARD, OUTPUT
- raw – используется редко. Пакет проверяется на соответствие условиям данной таблицы до передачи системе определения состояний (conntrack), например, для того, чтобы не обрабатываться с помощью данной системы (действие NOTRACK). Система определения состояний позволяет фильтровать пакеты на уровне взаимодействия сеансов приложений. То есть фильтрует пакеты по сеансу связи – новый сеанс связи (NEW), уже установленный сеанс связи (ESTABLISHED), дополнительный сеанс связи к уже существующему (RELATED). Данная система позволяет реализовать высокоуровневый межсетевой экран, который вместо работы с пакетами работает с сеансами связи в рамках приложений. Содержится в цепочках PREROUTING и OUTPUT.
- mangle – содержит правила модификации обрабатываемых IP-пакетов. Например, изменение полей заголовков IP-пакетов, содержащих служебную информацию. Используется редко. Содержится в цепочках PREROUTING, INPUT, FORWARD, OUTPUT,
- nat – предназначена для подмены адреса отправителя или получателя. Данная таблица применяется только к первому пакету из потока протокола передачи данных по сети, к остальным пакетам потока пакетов выбранное действие применяется далее автоматически. Таблицу используют, например, для трансляции адресов отправителя и получателя, для маскировки адресов отправителя или получателя. Это делается в основном в двух случаях. Первый – когда необходимо организовать доступ к сети Интернет нескольким компьютерам, расположенным за данным компьютером. Второй – когда необходимо спрятать (замаскировать) в целях безопасности отправителя или получателя информации, передаваемой по сети Интернет. Содержится в цепочках PREROUTING, OUTPUT, POSTROUTING.
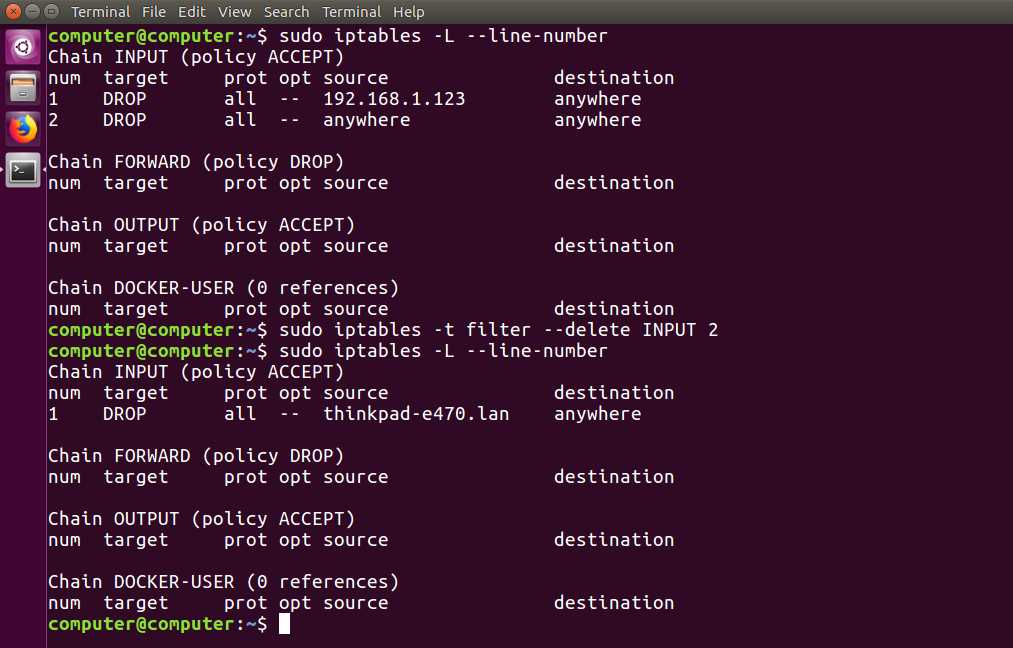
3. Номера правил в iptables
Следующая команда позволяет нам вывести номера правил iptables, которые потом можно использовать для управления ими на экран:
sudo iptables —line-numbers -n
Например:
![]()
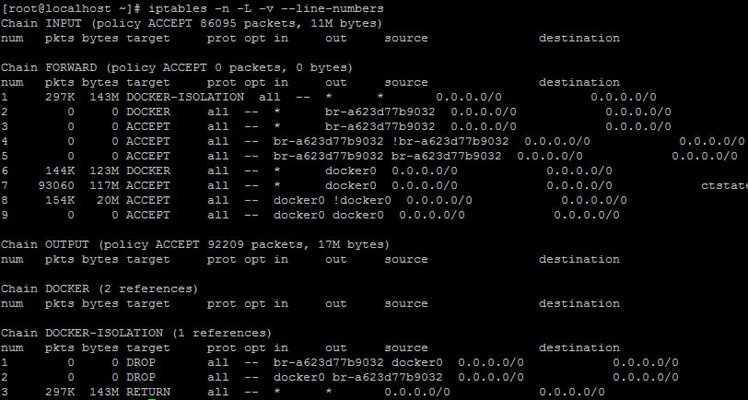
4. Просмотр правил со статистикой пакетов
Чтобы посмотреть таблицу правил со счетчиком переданного (полученного) количества байтов (bytes) и пакетов (pkts) используется следующая команда:
sudo iptables -n -v
Например:
![]()
Настройка netfilter/iptables для подключения нескольких клиентов к одному соединению.
Давайте теперь рассмотрим наш Linux в качестве шлюза для локальной сети во внешнюю сеть Internet. Предположим, что интерфейс eth0 подключен к интернету и имеет IP 198.166.0.200, а интерфейс eth1 подключен к локальной сети и имеет IP 10.0.0.1. По умолчанию, в ядре Linux пересылка пакетов через цепочку FORWARD (пакетов, не предназначенных локальной системе) отключена. Чтобы включить данную функцию, необходимо задать значение 1 в файле /proc/sys/net/ipv4/ip_forward:
netfilter:~# echo 1 > /proc/sys/net/ipv4/ip_forward
Чтобы форвардинг пакетов сохранился после перезагрузки, необходимо в файле /etc/sysctl.conf раскомментировать (или просто добавить) строку net.ipv4.ip_forward=1.
Итак, у нас есть внешний адрес (198.166.0.200), в локальной сети имеется некоторое количество гипотетических клиентов, которые имеют адреса из диапазона локальной сети и посылают запросы во внешнюю сеть. Если эти клиенты будут отправлять во внешнюю сеть запросы через шлюз «как есть», без преобразования, то удаленный сервер не сможет на них ответить, т.к. обратным адресом будет получатель из «локальной сети». Для того, чтобы эта схема корректно работала, необходимо подменять адрес отправителя, на внешний адрес шлюза Linux. Это достигается за счет (маскарадинг) в , в .
netfilter:~# iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A FORWARD -m conntrack --ctstate NEW -i eth1 -s 10.0.0.1/24 -j ACCEPT netfilter:~# iptables -P FORWARD DROP netfilter:~# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Итак, по порядку сверху-вниз мы разрешаем уже установленные соединения в цепочке FORWARD, таблице filter, далее мы разрешаем устанавливать новые соединения в цепочке FORWARD, таблице filter, которые пришли с интерфейса eth1 и из сети 10.0.0.1/24. Все остальные пакеты, которые проходят через цепочку FORWARD — отбрасывать. Далее, выполняем маскирование (подмену адреса отправителя пакета в заголовках) всех пакетов, исходящих с интерфейса eth0.
Примечание. Есть некая общая рекомендация: использовать правило -j MASQUERADE для интерфейсов с динамически получаемым IP (например, по DHCP от провайдера). При статическом IP, -j MASQUERADE можно заменить на аналогичное -j SNAT —to-source IP_интерфейса_eth0. Кроме того, SNAT умеет «помнить» об установленных соединениях при кратковременной недоступности интерфейса. Сравнение MASQUERADE и SNAT в таблице:
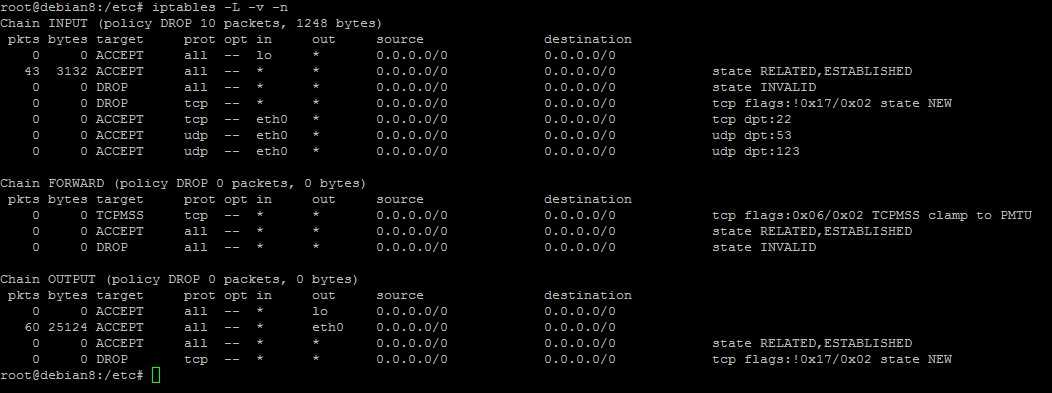
Кроме указанных правил так же можно нужно добавить правила для фильтрации пакетов, предназначенных локальному хосту — как описано в . То есть добавить запрещающие и разрешающие правила для входящих и исходящих соединений:
netfilter:~# iptables -P INPUT DROP netfilter:~# iptables -P OUTPUT DROP netfilter:~# iptables -A INPUT -i lo -j ACCEPT netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000 netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
В результате, если один из хостов локальной сети, например 10.0.0.2, попытается связаться с одним из интернет-хостов, например, 93.158.134.3 (ya.ru), при , их исходный адрес будет подменяться на внешний адрес шлюза в цепочке POSTROUTING таблице nat, то есть исходящий IP 10.0.0.2 будет заменен на 198.166.0.200. С точки зрения удаленного хоста (ya.ru), это будет выглядеть, как будто с ним связывается непосредственно сам шлюз. Когда же удаленный хост начнет ответную передачу данных, он будет адресовать их именно шлюзу, то есть 198.166.0.200. Однако, на шлюзе адрес назначения этих пакетов будет подменяться на 10.0.0.2, после чего пакеты будут передаваться настоящему получателю в локальной сети. Для такого обратного преобразования никаких дополнительных правил указывать не нужно — это будет делать все та же операция MASQUERADE, которая помнит какой хост из локальной сети отправил запрос и какому хосту необходимо вернуть пришедший ответ.
Примечание: желательно негласно принято, перед всеми командами iptables очищать цепочки, в которые будут добавляться правила:
netfilter:~# iptables -F ИМЯ_ЦЕПОЧКИ
Проброс портов в iptables
Первое что нужно сделать, это включить переадресацию трафика на уровне ядра, если это еще не сделано. Для этого выполните:
Чтобы настройка сохранялась после перезагрузки используйте такую команду:
Мы не будем здесь подробно рассматривать правила iptables и значение каждой опции, поэтому перед тем, как читать дальше вам лучше ознакомиться со статьей iptables для начинающих. Дальше рассмотрим проброс портов iptables nat.

Настройка прохождения пакетов
Сначала мы рассмотрим как разрешить прохождение пакетов через маршрутизатор. Для этого в брандмауэре есть цепочка FORWARD. По умолчанию для всех пакетов применяется правило DROP, которое означает что все нужно отбросить. Сначала разрешим инициализацию новых соединений, проходящих от eth0 до eth1. Они имеют тип contrack и представлены пакетом SYN:
Действие ACCEPT означает, что мы разрешаем это соединение. Но это правило разрешает только первый пакет, а нам нужно пропускать любой следующий трафик в обоих направлениях для этого порта (80). поэтому добавим правила для ESTABLIHED и RLEATED:
Дальше явно установим что наша политика по умолчанию — DROP:
Это еще не проброс портов, мы только разрешили определенному трафику, а именно на порт 80, проходить через маршрутизатор на другие машины локальной сети. Теперь настроим правила, которые будут отвечать за перенаправление трафика.
Модификация пакетов в iptables
Далее мы настроим правила, которые будут указывать как и куда нужно перенаправить пакеты, приходящие на порт 80. Сейчас маршрутизатор может их пропускать в сеть, но он еще не знает куда. Для этого нам нужно будет настроить две вещи — модификацию адреса назначения (Destination) DNAT и модификацию адреса отправителя (Source) SNAT.
Правила DNAT настраиваются в цепочке PREROUTING, в таблице NAT. Эта операция изменяет адрес назначения пакета чтобы он достиг нужной нам цели, когда проходит между сетями. Клиенты будут отправлять пакеты нашему маршрутизатору, и им не нужно знать топологию внутренней сети. Пакет автоматически будет приходить нашему веб-серверу (192.168.1.2).
С помощью этого правила мы перенаправляем все пакеты, пришедшие на порт 80, к 192.168.1.2 опять же на порт 80:
Но это только половина работы. Пакет будет иметь исходный адрес клиента, а значит будет пытаться отправить ответ ему. Так как клиент ожидает получить ответ от маршрутизатора, то нормального TCP соединения не получиться. Чтобы решить эту проблему нужно модифицировать адрес источника и заменить его на адрес маршрутизатора 192.168.1.1. Тогда ответ придет маршрутизатору, а тот уже от своего имени передаст его в сеть.
Если вы хотите перенаправить трафик на порт 8080, то нужно указать его после ip адреса:
Также может понадобиться выполнить проброс диапазона портов iptables, для этого просто укажите диапазон, например, 1000:2000:
После добавления этого правила можете проверять работу перенаправление портов iptables будет выполняться и все будет отправляться так, как нужно.
Сохранение настроек iptables
Теперь, когда все настроено, нужно сохранить этот набор правил, чтобы он загружался автоматически при каждом старте. Для этого выполните:
Готово. Теперь проброс портов iptables ubuntu будет работать так, как нужно.





