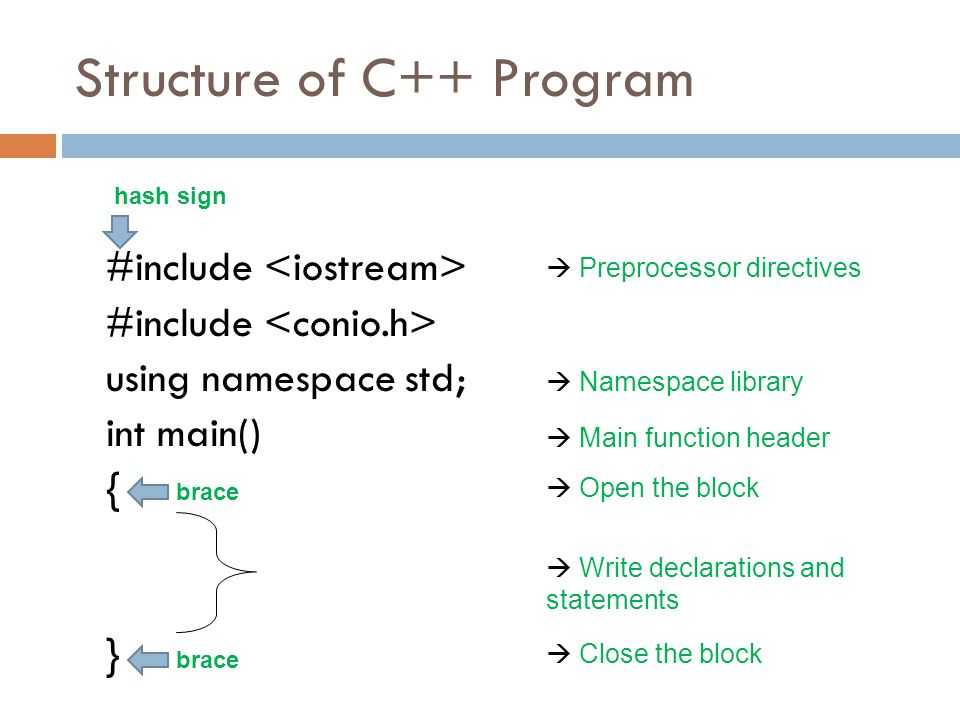
Remarks
identifier
The name of the alias.
type
The type identifier you are creating an alias for.
An alias does not introduce a new type and cannot change the meaning of an existing type name.
The simplest form of an alias is equivalent to the mechanism from C++03:
Both of these enable the creation of variables of type «counter». Something more useful would be a type alias like this one for :
Aliases also work with function pointers, but are much more readable than the equivalent typedef:
A limitation of the mechanism is that it doesn’t work with templates. However, the type alias syntax in C++11 enables the creation of alias templates:
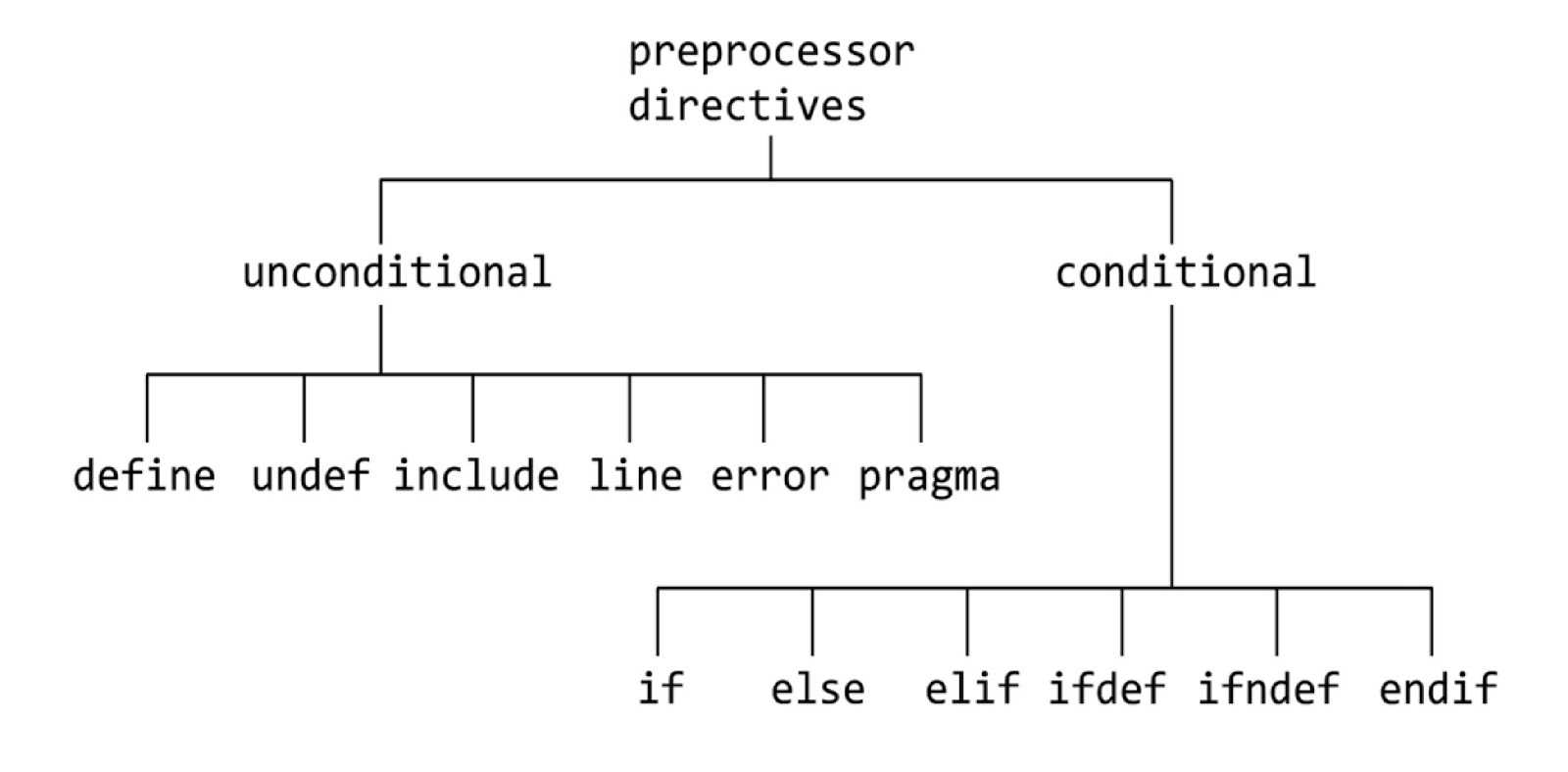
Синтаксис директив
Директивой (командной строкой) препроцессора называется строка в исходном коде, имеющая следующий формат: :
- ноль или более символов пробелов и/или табуляции;
- символ ;
- одно из предопределённых ключевых слов;
- параметры, зависимые от ключевого слова.
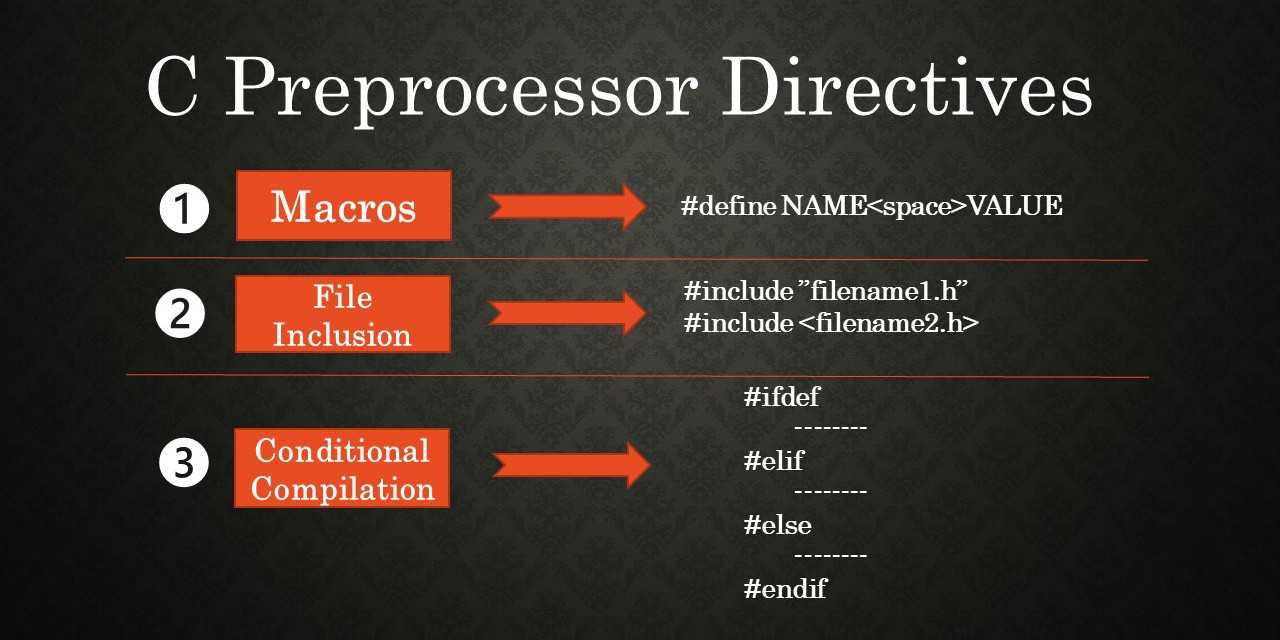
Список ключевых слов:
- — создание константы или макроса;
- — удаление константы или макроса;
- — вставка содержимого указанного файла;
- — проверка истинности выражения;
- — проверка существования константы или макроса;
- — проверка не существования константы или макроса;
- — ветка условной компиляции при ложности выражения ;
- — проверка истинности другого выражения; краткая форма записи для комбинации и ;
- — конец ветки условной компиляции;
- — указание имени файла и номера текущей строки для компилятора;
- — вывод сообщения и остановка компиляции;
- — вывод сообщения без остановки компиляции;
- — указание действия, зависящего от реализации, для препроцессора или компилятора;
Иначе:
- если ключевое слово не указано, директива игнорируется;
- если указано несуществующее ключевое слово, выводится сообщение об ошибке и компиляция прерывается.
DECLARE_DYNCREATE
Позволяет динамически создавать объекты производных классов во время выполнения.
Комментарии
Платформа использует эту возможность для динамического создания новых объектов. Например, новое представление, созданное при открытии нового документа. Классы документов, представлений и фреймов должны поддерживать динамическое создание, так как платформа должна создавать их динамически.
Добавьте макрос DECLARE_DYNCREATE в модуль h для класса, а затем включите этот модуль во все cpp модули, которым требуется доступ к объектам этого класса.
Если в объявление класса входит DECLARE_DYNCREATE, то IMPLEMENT_DYNCREATE необходимо включать в реализацию класса.
Дополнительные сведения о макросе DECLARE_DYNCREATE см. в разделах о классах CObject.
Примечание
Макрос DECLARE_DYNCREATE включает все функции DECLARE_DYNAMIC.
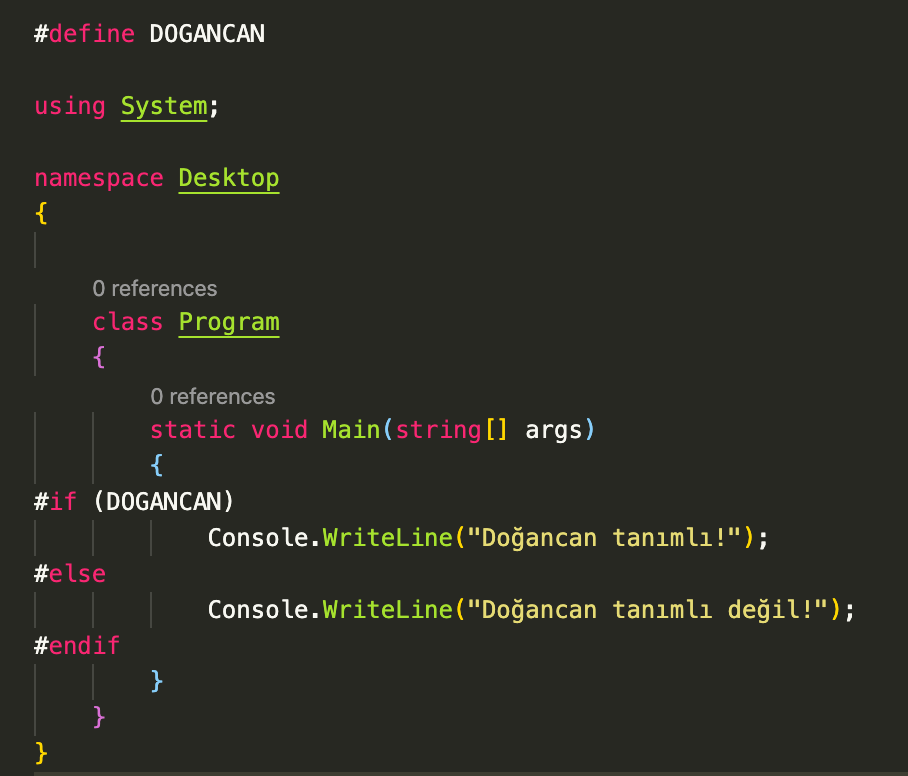
Директива #define
Последнее обновление: 22.05.2017
Директива #define определяет идентификатор и последовательность символов, которые будут подставляться вместо
идентификатора каждый раз, когда он встретится в исходном файле. Формальное определение директивы:
#define идентификатор последовательность_символов
Используем директиву #define:
#define BEGIN {
#define END }
#define N 23
int main(void)
BEGIN
int x = N;
return 0;
END
Здесь определены три идентификатора BEGIN, END, N. Как правило, идентификаторы имеют имена в верхнем регистре, хотя это необязательно, можно определять имена и строчными символами.
В итоге все вхождения последовательности символов «BEGIN» будут заменяться на открывающую фигурную скобку, а «END» — на закрывающую, а символ «N» на число 23.
Таким образом, после обработки препроцессора программа приобретет следующий вид:
int main(void)
{
int x = 23;
return 0;
}
Для идентификатора необязательно определять последовательность символов, можно ограничиться одним идентификаторов:
#define DEBUG
Особенно удобно использовать директиву #define для определения размеров массивов:
#include <stdio.h>
#define N 4
int main(void)
{
int numbers = {1, 2, 3, 4};
for(int i=0; i<N; i++)
{
printf("%d ", numbers);
}
return 0;
}
В данном случае если мы захотим глобально поменять размер массива, то достаточно изменить значение N в директиве define.
#include <stdio.h>
#define N 4
int main(void)
{
char symbol = 'N';
printf("%c \n", symbol); // N
printf("N"); //N
return 0;
}
Причем если идентификатор должен представлять одно слово, то его последовательность символов может состоять из нескольких слов или символов, разделенных пробелами:
#define REAL long double
Директива #undef
В процессе работы мы можем многократно определять новое значение для одного идентификатора:
#define N 23 #define N 32 #define N 55
Но некоторые компиляторы, в частности, gcc, могут выдавать предупреждения при повторном определении идентификатора, и чтобы выйти из этой ситуации, мы можем
использовать директиву #undef для отмены действия макроса. Эта директива имеет следующее определение:
#undef идентификатор
Например:
#include <stdio.h>
#define STRING "Good morning \n"
int main(void)
{
printf(STRING);
#undef STRING
#define STRING "Good afternoon \n"
printf(STRING);
#undef STRING
#define STRING "Good evening \n"
printf(STRING);
return 0;
}
НазадВперед
Pragmas
gives the compiler special instructions for the compilation of the file in which it appears. The instructions must be supported by the compiler. In other words, you can’t use to create custom preprocessing instructions.
- : Enable or disable warnings.
- : Generate a checksum.
Where is the name of a recognized pragma and is the pragma-specific arguments.
#pragma warning
can enable or disable certain warnings.
Where is a comma-separated list of warning numbers. The «CS» prefix is optional. When no warning numbers are specified, disables all warnings and enables all warnings.





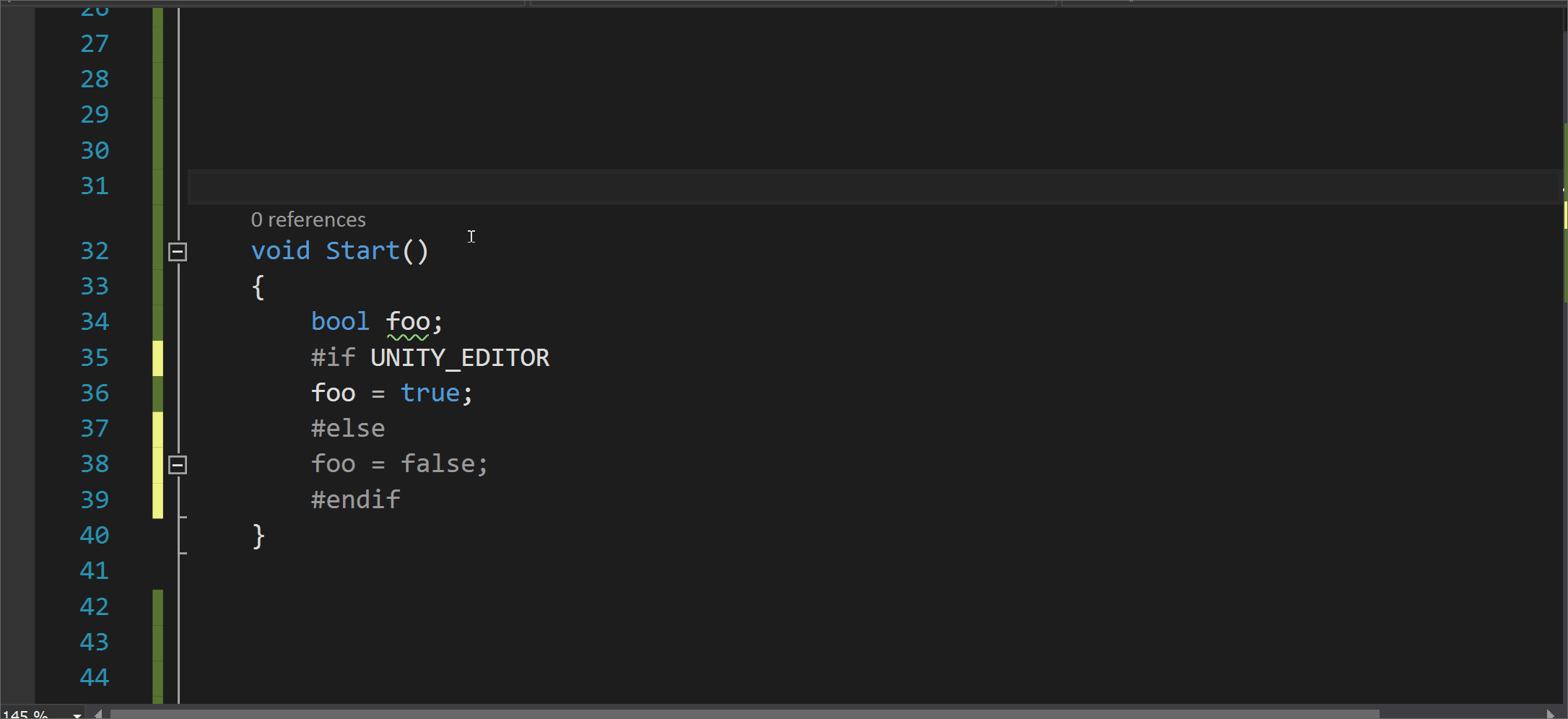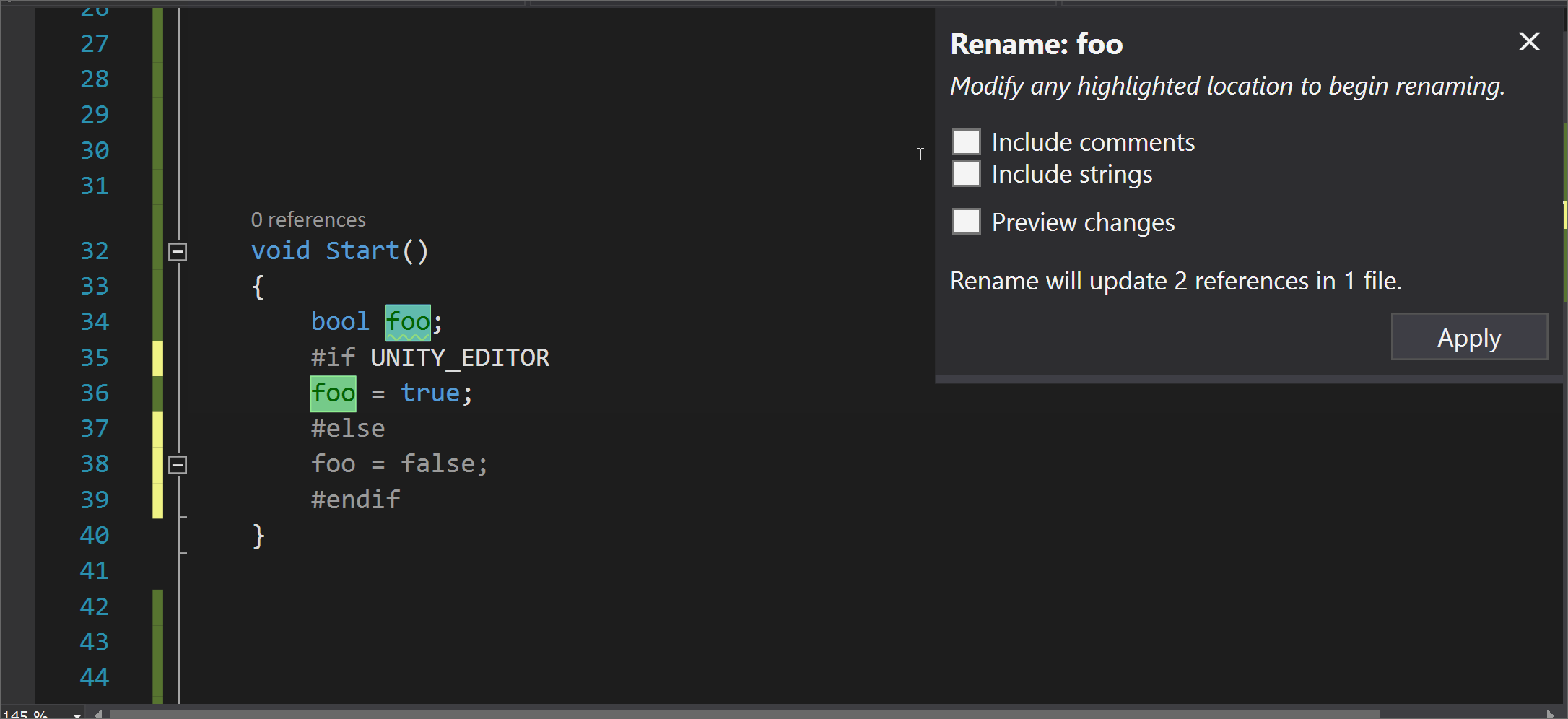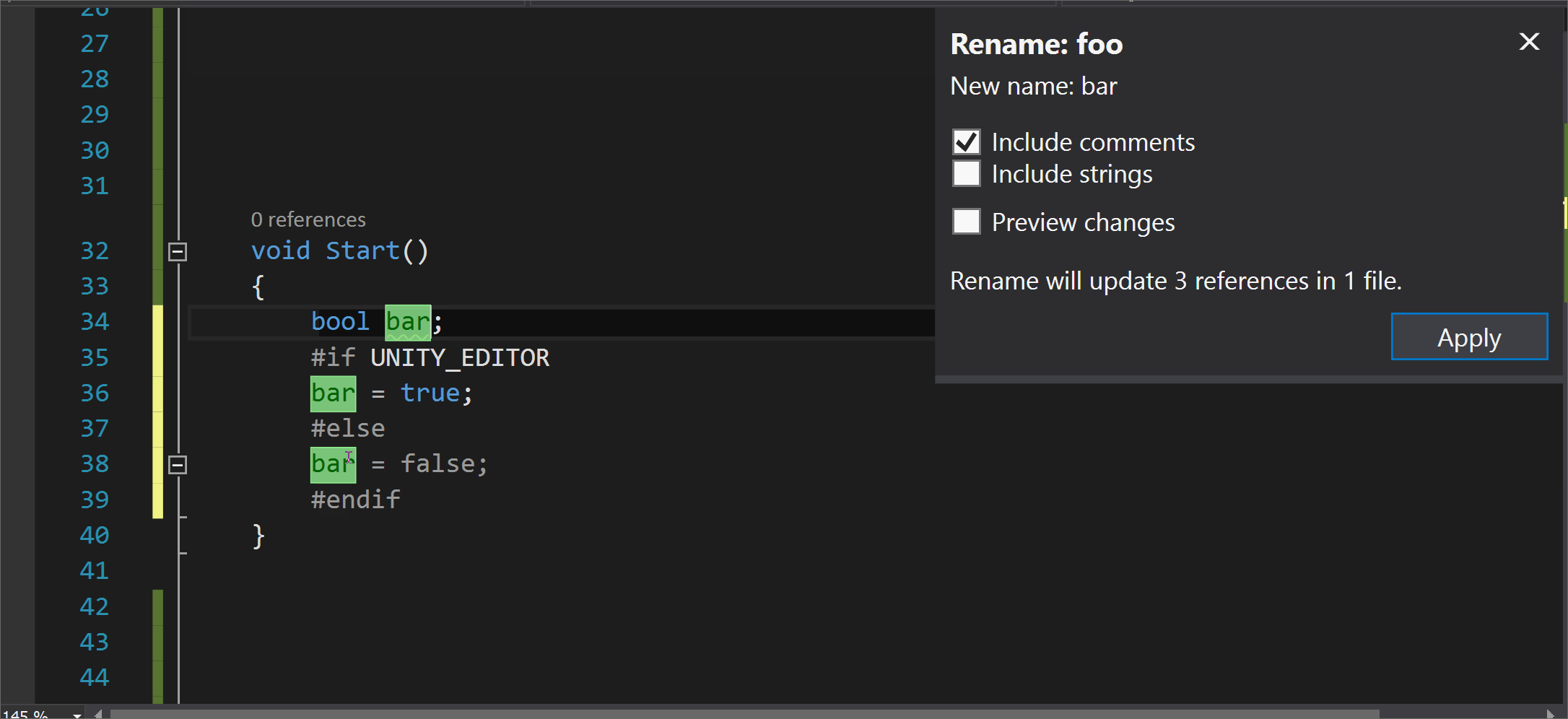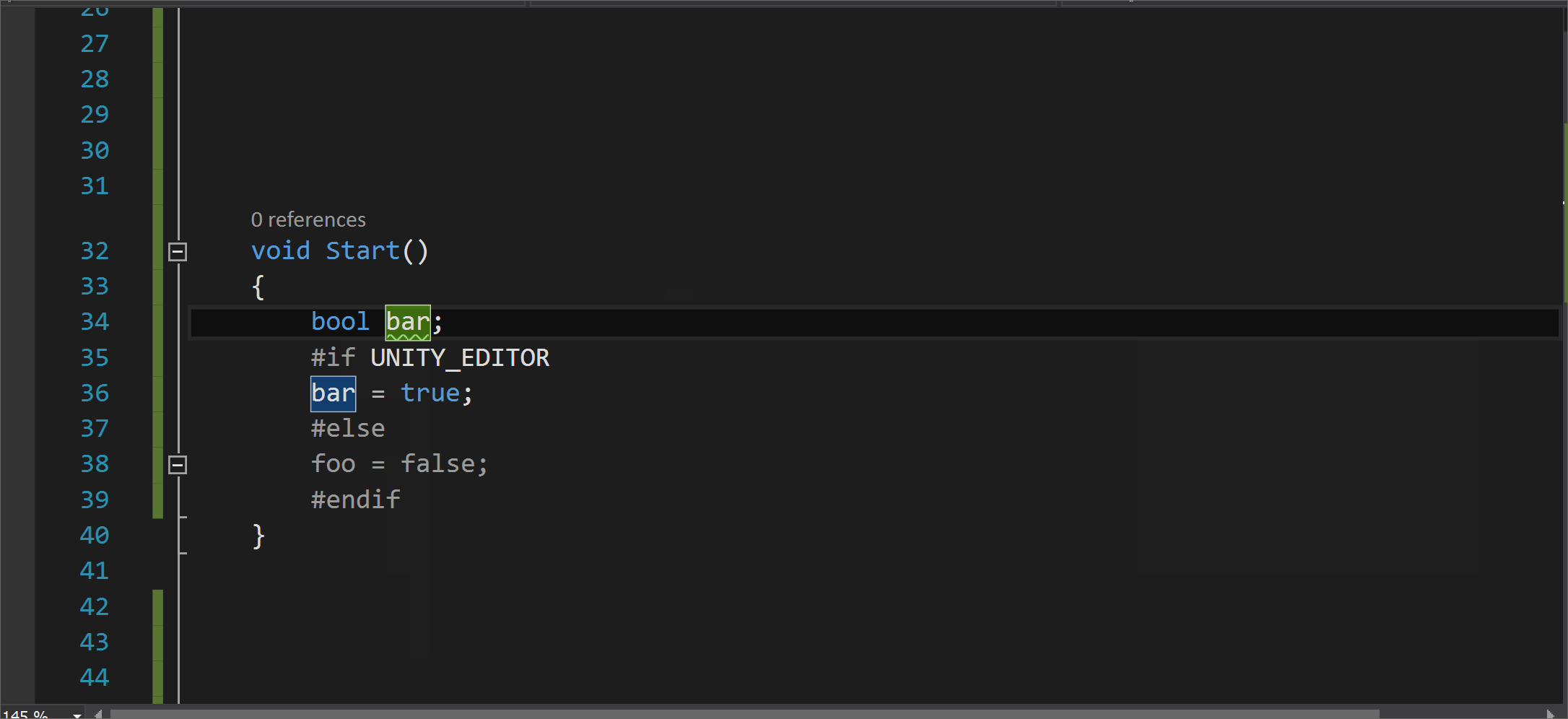
Note
To find warning numbers in Visual Studio, build your project and then look for the warning numbers in the Output window.
The takes effect beginning on the next line of the source file. The warning is restored on the line following the . If there’s no in the file, the warnings are restored to their default state at the first line of any later files in the same compilation.
#pragma checksum
Generates checksums for source files to aid with debugging ASP.NET pages.
Where is the name of the file that requires monitoring for changes or updates, is the Globally Unique Identifier (GUID) for the hash algorithm, and is the string of hexadecimal digits representing the bytes of the checksum. Must be an even number of hexadecimal digits. An odd number of digits results in a compile-time warning, and the directive is ignored.
The Visual Studio debugger uses a checksum to make sure that it always finds the right source. The compiler computes the checksum for a source file, and then emits the output to the program database (PDB) file. The debugger then uses the PDB to compare against the checksum that it computes for the source file.
This solution doesn’t work for ASP.NET projects, because the computed checksum is for the generated source file, rather than the .aspx file. To address this problem, provides checksum support for ASP.NET pages.
When you create an ASP.NET project in Visual C#, the generated source file contains a checksum for the .aspx file, from which the source is generated. The compiler then writes this information into the PDB file.
If the compiler doesn’t find a directive in the file, it computes the checksum and writes the value to the PDB file.
Conversion constructors
Conversion constructors define conversions from user-defined or built-in types to a user-defined type. The following example demonstrates a conversion constructor that converts from the built-in type to a user-defined type .
Notice that the first call to the function , which takes an argument of type , doesn’t require a conversion because its argument is the correct type. However, on the second call to , a conversion is needed because the type of the argument, a with a value of , is not what the function expects. The function can’t use this value directly, but because there’s a conversion from the type of the argument——to the type of the matching parameter——a temporary value of type is constructed from the argument and used to complete the function call. In the third call to , notice that the argument is not a , but is instead a with a value of —and yet the function call can still be completed because the compiler can perform a standard conversion—in this case, from to —and then perform the user-defined conversion from to to complete the necessary conversion.
Declaring conversion constructors
The following rules apply to declaring a conversion constructor:
-
The target type of the conversion is the user-defined type that’s being constructed.
-
Conversion constructors typically take exactly one argument, which is of the source type. However, a conversion constructor can specify additional parameters if each additional parameter has a default value. The source type remains the type of the first parameter.
-
Conversion constructors, like all constructors, do not specify a return type. Specifying a return type in the declaration is an error.
-
Conversion constructors can be explicit.
Explicit conversion constructors
By declaring a conversion constructor to be , it can only be used to perform direct initialization of an object or to perform an explicit cast. This prevents functions that accept an argument of the class type from also implicitly accepting arguments of the conversion constructor’s source type, and prevents the class type from being copy-initialized from a value of the source type. The following example demonstrates how to define an explicit conversion constructor, and the effect it has on what code is well-formed.
In this example, notice that you can still use the explicit conversion constructor to perform direct initialization of . If instead you were to copy-initialize , it would be an error. The first call to is unaffected because the argument is the correct type. The second call to is an error, because the conversion constructor can’t be used to perform implicit conversions. The third call to is legal because of the explicit cast to , but notice that the compiler still helped complete the cast by inserting an implicit cast from to .
Although the convenience of allowing implicit conversions can be tempting, doing so can introduce hard-to-find bugs. The rule of thumb is to make all conversion constructors explicit except when you’re sure that you want a specific conversion to occur implicitly.
Сведения об ошибках и предупреждениях
Вы указываете компилятору создавать определенные пользователем ошибки и предупреждения компилятора, а также управлять сведениями о строках с помощью следующих директив.
- : создание ошибки компилятора с указанным сообщением.
- : создание предупреждения компилятора с конкретным сообщением.
- : изменение номера строки, выводимого с сообщениями компилятора.
позволяет создать определяемую пользователем ошибку CS1029 из определенного места в коде. Пример:
Примечание
Компилятор обрабатывает особым образом и сообщает об ошибке компилятора CS8304 с сообщением, содержащим используемые версии компилятора и языка.
позволяет создать предупреждение компилятора CS1030 первого уровня из определенного места в коде. Пример:
Директива позволяет изменять номер строки компилятора и при необходимости имя файла, в который будут выводиться ошибки и предупреждения.
В следующем примере показано, как включить в отчет два предупреждения, связанные с номерами строк. Директива принудительно устанавливает номер следующей строки 200 (по умолчанию используется номер 6). До выполнения следующей директивы в отчете будет указываться имя файла Special. Директива по умолчанию восстанавливает нумерацию строк в исходное состояние с учетом строк, номера которых были изменены с помощью предшествующей директивы.
В результате компиляции формируются следующие результаты:
Директива может использоваться на автоматизированном промежуточном этапе процесса построения. Например, если строки были удалены из первоначального файла с исходным кодом, но вам по-прежнему требуется создавать выходные файлы компилятора на основе изначальной нумерации строк в файле, можно удалить строки и затем смоделировать их первичную нумерацию с помощью директивы .
Директива скрывает последующие строки для отладчика. В этом случае при пошаговой проверке кода разработчиком все строки между и следующей директивой (кроме случаев, когда это также директива ) будут пропущены. Этот параметр также можно использовать для того, чтобы дать ASP.NET возможность различать определяемый пользователем и создаваемый компьютером код. В основном эта функция используется в ASP.NET, но также может быть полезна и в других генераторах исходного кода.
Директива не влияет на имена файлов и номера строк в отчетах об ошибках. Это значит, что при обнаружении ошибки в скрытом блоке компилятор укажет в отчете текущие имя файла и номер строки, где найдена ошибка.
Директива задает имя файла, которое будет отображаться в выходных данных компилятора. По умолчанию используется фактическое имя файла с исходным кодом. Имя файла должно заключаться в двойные кавычки (» «). Перед ним должен указываться номер строки.
Начиная с C# 10 можно использовать новую форму директивы :
Компоненты этой формы:
- : начальная строка и столбец для первого символа строки, следующей за директивой. В этом примере следующая строка будет отображаться как строка 1, столбец 1.
- : конечная строка и столбец для помеченной области.
- : смещение столбца, чтобы директива вступила в силу. В этом примере в качестве столбца 1 будет отображаться десятый столбец. Здесь начинается объявление . Это поле является необязательным. Если этот параметр опущен, директива вступает в силу в первом столбце.
- : имя выходного файла.
В предыдущем примере будет создано следующее предупреждение:
После повторного сопоставления переменная находится в первой строке, в шестом символе.
Предметно-ориентированные языки (DSL) обычно используют этот формат, чтобы обеспечить более эффективное сопоставление исходного файла с созданными выходными данными C#. Дополнительные примеры этого формата см. в разделе примеров в .






What it Means to Define Something in C and C++
Defining something means providing all of the necessary information to create that thing in its entirity. Defining a function means providing a function body; defining a class means giving all of the methods of the class and the fields. Once something is defined, that also counts as declaring it; so you can often both declare and define a funtion, class or variable at the same time. But you don’t have to.
For example, having a declaration is often good enough for the compiler. You can write code like this:
Since the compiler knows the return value of func, and the number of arguments it takes, it can compile the call to func even though it doesn’t yet have the definition. In fact, the definition of the method func could go into another file!
You can also declare a class without defining it
Code that needs to know the details of what is in MyClass can’t work—you can’t do this:
Because the compiler needs to know the size of the variable an_object, and it can’t do that from the declaration of MyClass; it needs the definition that shows up below.
Common Cases
If you want to use a function across multiple source files, you should declare the function in one header file (.h) and then put the function definition in one source file (.c or .cpp). All code that uses the function should include just the .h file, and you should link the resulting object files with the object file from compiling the source file.
If you want to use a class in multiple files, you should put the class definition in a header file and define the class methods in a corresponding source file. (You an also use inline functions for the methods.)
If you want to use a variable in multiple files, you should put the declaration of the variable using the extern keyword in one header file, and then include that header file in all source files that need that variable. Then you should put the definition of that variable in one source file that is linked with all the object files that use that variable.
Read more similar articlesCompiling and LinkingThe C PreprocessorLearn more about dealing with compiler warnings
Popular pages
- Jumping into C++, the Cprogramming.com ebook
- How to learn C++ or C
- C Tutorial
- C++ Tutorial
- 5 ways you can learn to program faster
- The 5 most common problems new programmers face
- How to set up a compiler
- How to make a game in 48 hours
What it Means to Declare Something in C and C++
When you declare a variable, a function, or even a class all you are doing is saying: there is something with this name, and it has this type. The compiler can then handle most (but not all) uses of that name without needing the full definition of that name. Declaring a value—without defining it—allows you to write code that the compiler can understand without having to put all of the details. This is particularly useful if you are working with multiple source files, and you need to use a function in multiple files. You don’t want to put the body of the function in multiple files, but you do need to provide a declaration for it.
So what does a declaration look like? For example, if you write:
This is a function declaration; it does not provide the body of the function, but it does tell the compiler that it can use this function and expect that it will be defined somewhere.
Declaring and Defining Variables with Extern
Most of the time, when you declare a variable, you are also providing the definition. What does it mean to define a variable, exactly? It means you are telling the compiler where to create the storage for that variable. For example, if you write:
int x;
int main()
{
x = 3;
}
The line int x; both declares and defines the variable; it effectively says, «create a variable named x, of type int. Also, the storage for the variable is that it is a global variable defined in the object file associated with this source file.» That’s kind of weird, isn’t it? What is going on is that someone else could actually write a second source file that has this code:
extern int x;
int func()
{
x = 3;
}
Now the use of extern is creating a declaration of a variable but NOT defining it; it is saying that the storage for the variable is somewhere else. Technically, you could even write code like this:
extern int x;
int func()
{
x = 3;
}
int x;
And now you have a declaration of x at the top of the program and a definition at the bottom. But usually extern is used when you want to access a global variable declared in another source file, as I showed above, and then link the two resulting object files together after compilation. Using extern to declare a global variable is pretty much the same thing as using a function declaration to declare a function in a header file. (In fact, you’d generally put extern in a header file rather than putting it in a source file.)
In fact, if you put a variable into a header file and do not use extern, you will run into the inverse problem of an undefined symbol; you will have a symbol with multiple definitions, with an error like «redefinition of ‘foo'». This will happen when the linker goes to link together multiple object files.
Example: automatic vs. static initialization
A local automatic object or variable is initialized every time the flow of control reaches its definition. A local static object or variable is initialized the first time the flow of control reaches its definition.
Consider the following example, which defines a class that logs initialization and destruction of objects and then defines three objects, , , and :
This example demonstrates how and when the objects , , and are initialized and when they are destroyed.
There are several points to note about the program:
-
First, and are automatically destroyed when the flow of control exits the block in which they are defined.
-
Second, in C++, it is not necessary to declare objects or variables at the beginning of a block. Furthermore, these objects are initialized only when the flow of control reaches their definitions. ( and are examples of such definitions.) The output shows exactly when they are initialized.
-
Finally, static local variables such as retain their values for the duration of the program, but are destroyed as the program terminates.
thread_local (C++11)
A variable declared with the specifier is accessible only on the thread on which it is created. The variable is created when the thread is created, and destroyed when the thread is destroyed. Each thread has its own copy of the variable. On Windows, is functionally equivalent to the Microsoft-specific attribute.
Things to note about the specifier:
-
Dynamically initialized thread-local variables in DLLs may not be correctly initialized on all calling threads. For more information, see .
-
The specifier may be combined with or .
-
You can apply only to data declarations and definitions; cannot be used on function declarations or definitions.
-
You can specify only on data items with static storage duration. This includes global data objects (both and ), local static objects, and static data members of classes. Any local variable declared is implicitly static if no other storage class is provided; in other words, at block scope is equivalent to .
-
You must specify for both the declaration and the definition of a thread local object, whether the declaration and definition occur in the same file or separate files.
On Windows, is functionally equivalent to except that * can be applied to a type definition and is valid in C code. Whenever possible, use because it is part of the C++ standard and is therefore more portable.





What it Means to Declare Something in C and C++
When you declare a variable, a function, or even a class all you are doing is saying: there is something with this name, and it has this type. The compiler can then handle most (but not all) uses of that name without needing the full definition of that name. Declaring a value—without defining it—allows you to write code that the compiler can understand without having to put all of the details. This is particularly useful if you are working with multiple source files, and you need to use a function in multiple files. You don’t want to put the body of the function in multiple files, but you do need to provide a declaration for it.
So what does a declaration look like? For example, if you write:
int func();
This is a function declaration; it does not provide the body of the function, but it does tell the compiler that it can use this function and expect that it will be defined somewhere.
The explicit keyword and problems with implicit conversion
By default when you create a user-defined conversion, the compiler can use it to perform implicit conversions. Sometimes this is what you want, but other times the simple rules that guide the compiler in making implicit conversions can lead it to accept code that you don’t want it to.
One well-known example of an implicit conversion that can cause problems is the conversion to . There are many reasons that you might want to create a class type that can be used in a Boolean context—for example, so that it can be used to control an statement or loop—but when the compiler performs a user-defined conversion to a built-in type, the compiler is allowed to apply an additional standard conversion afterwards. The intent of this additional standard conversion is to allow for things like promotion from to , but it also opens the door for less-obvious conversions—for example, from to , which allows your class type to be used in integer contexts you never intended. This particular problem is known as the Safe Bool Problem. This kind of problem is where the keyword can help.
The keyword tells the compiler that the specified conversion can’t be used to perform implicit conversions. If you wanted the syntactic convenience of implicit conversions before the keyword was introduced, you had to either accept the unintended consequences that implicit conversion sometimes created or use less-convenient, named conversion functions as a workaround. Now, by using the keyword, you can create convenient conversions that can only be used to perform explicit casts or direct initialization, and that won’t lead to the kind of problems exemplified by the Safe Bool Problem.
The keyword can be applied to conversion constructors since C++98, and to conversion functions since C++11. The following sections contain more information about how to use the keyword.
Декларация против определения
Одна основная дихотомия заключается в том, содержит ли объявление определение: например, указывает ли объявление константы или переменной значение константы (соответственно, начальное значение переменной) или только ее тип; и аналогично, определяет ли объявление функции тело ( реализацию ) функции или только ее сигнатуру типа. Не все языки делают это различие: во многих языках объявления всегда включают определение и могут называться либо «объявлениями», либо «определениями», в зависимости от языка. Однако эти концепции различаются в языках, которые требуют объявления перед использованием (для которых используются предварительные объявления), и в языках, где интерфейс и реализация разделены: интерфейс содержит объявления, реализация содержит определения.
В неформальном использовании «объявление» относится только к чистому объявлению (только типы, без значения или тела), в то время как «определение» относится к объявлению, которое включает значение или тело. Однако при формальном использовании (в языковых спецификациях) «объявление» включает оба этих смысла с более тонкими различиями по языку: в C и C ++ объявление функции, не включающее тело, называется прототипом функции , в то время как Объявление функции, которая действительно включает тело, называется «определением функции». В Java объявления встречаются в двух формах. Для общедоступных методов они могут быть представлены в интерфейсах как сигнатуры методов, которые состоят из имен методов, типов ввода и типа вывода. Аналогичные обозначения можно использовать в определении абстрактных методов , не содержащих определения. Ограждающий класс может быть реализован, а новый производный класс, который обеспечивает определение метода, необходимо будет создан для того , чтобы создать экземпляр класса. Начиная с Java 8 , в язык было включено лямбда-выражение, которое можно было рассматривать как объявление функции.
Defining regions
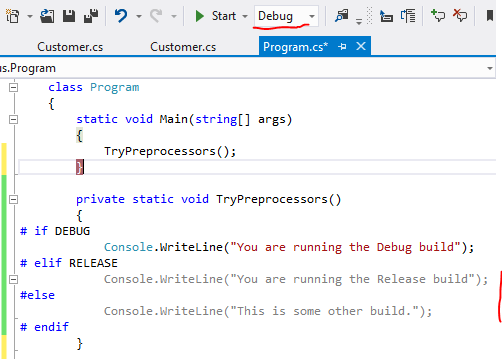
You can define regions of code that can be collapsed in an outline using the following two preprocessor directives:
- : Start a region.
- : End a region.
lets you specify a block of code that you can expand or collapse when using the outlining feature of the code editor. In longer code files, it’s convenient to collapse or hide one or more regions so that you can focus on the part of the file that you’re currently working on. The following example shows how to define a region:
A block must be terminated with an directive. A block can’t overlap with an block. However, a block can be nested in an block, and an block can be nested in a block.
DECLARE_DYNAMIC
Добавляет возможность доступа к сведениям времени выполнения о классе объекта при наследовании класса от .
Комментарии
Добавьте DECLARE_DYNAMIC макрос в модуль header (. h) для класса, а затем включите этот модуль во все cpp-модули, которым требуется доступ к объектам этого класса.
При использовании DECLARE_ динамических и IMPLEMENT_DYNAMICных макросов, как описано выше, можно использовать макрос RUNTIME_CLASS и функцию для определения класса объектов во время выполнения.
Если в объявление класса входит DECLARE_DYNAMIC, то IMPLEMENT_DYNAMIC необходимо включать в реализацию класса.
Дополнительные сведения о макросе DECLARE_DYNAMIC см. в разделах о классах CObject.





