Create CronJob in Kubernetes
Imagine you need to run the batch job from your previous example every 2 minutes. To do that, create a resource with the following specification.
# cat pod-cronjob.yml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: pod-cronjob
spec:
schedule: "*/2 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: pod-cronjob
image: busybox
args:
- /bin/sh
- -c
- date; echo hello from k8s cluster
restartPolicy: OnFailure
The highlighted section is the template for the Job resources that will be created by this CronJob where our defined task will run every 2 minutes.
Now to create a cronjob we use following command:
# kubectl create -f pod-cronjob.yml cronjob.batch/pod-cronjob created
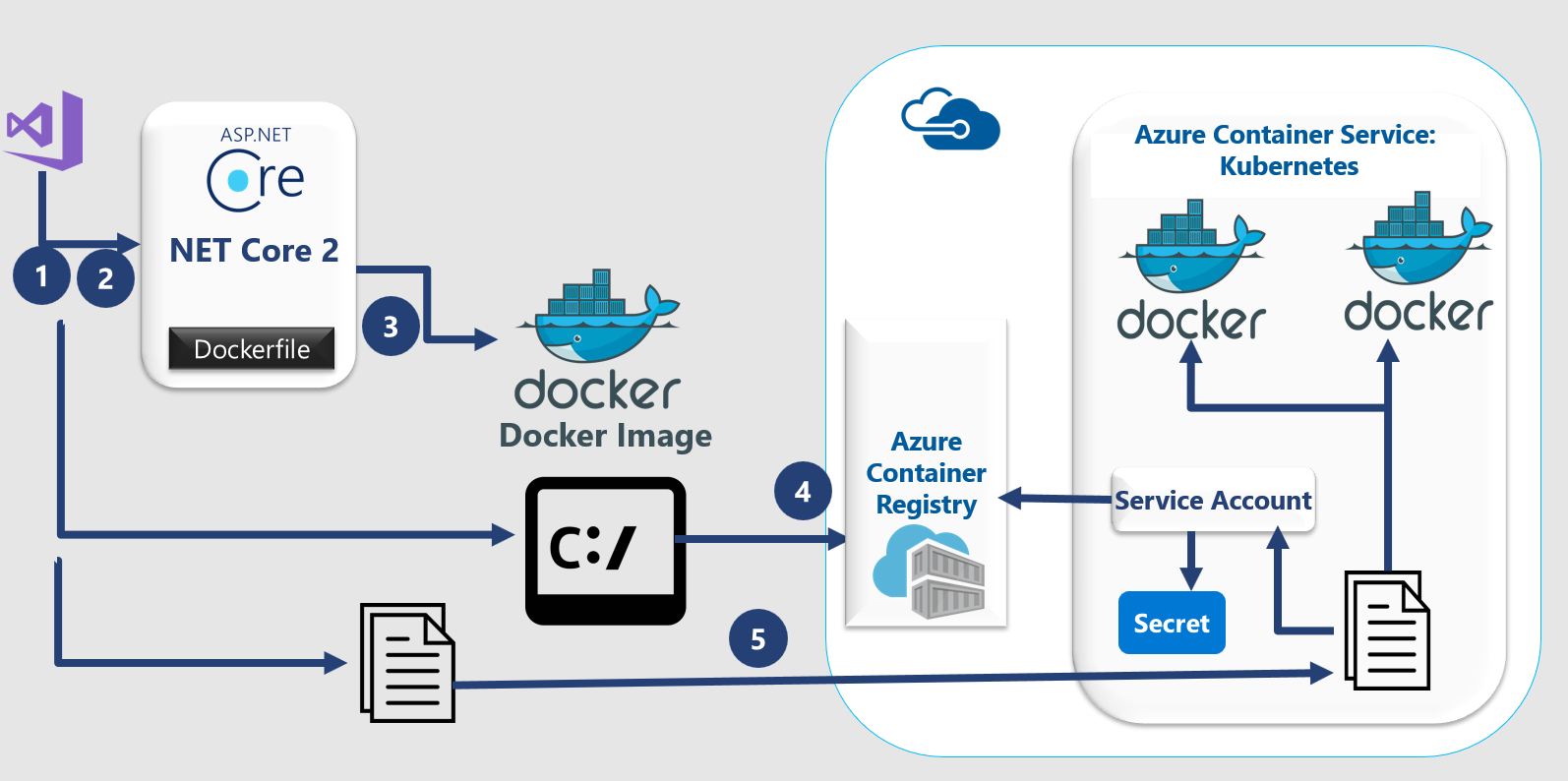
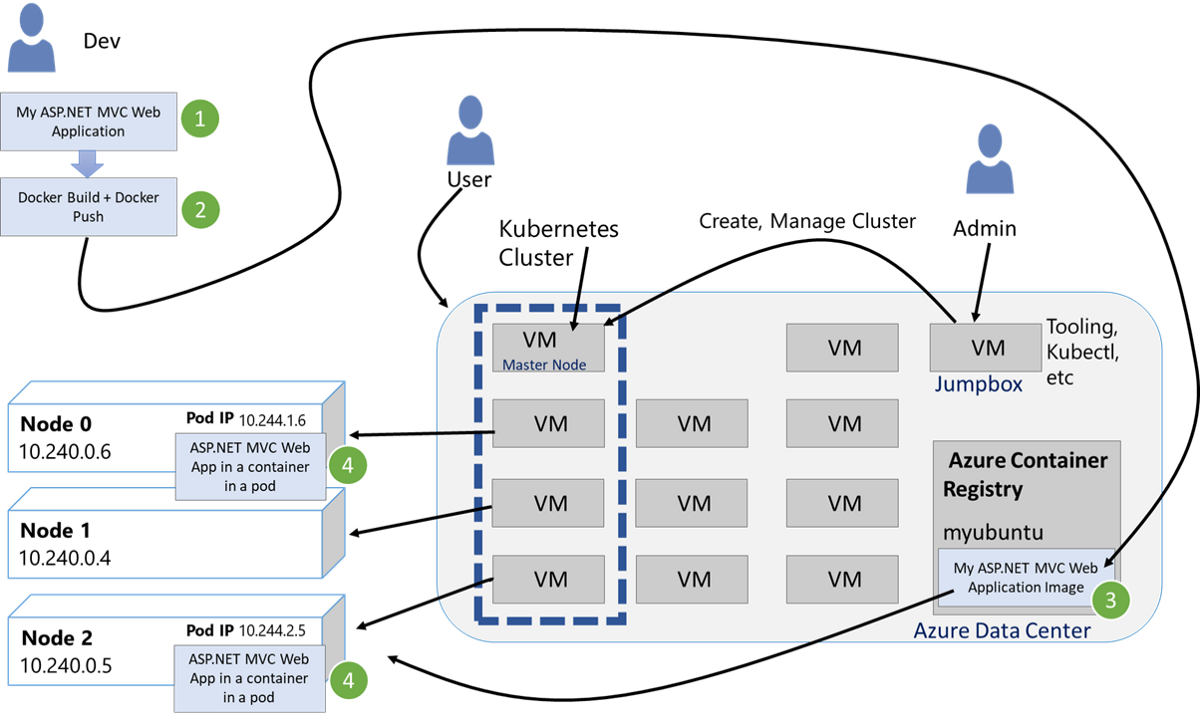
Настройка Kubernetes
Инициализация кластера
Нужно указать сервер, на котором установлен K8s (он будет первичным — там будут запускаться остальные операции) и выполнить инициализацию кластера:
kubeadm init --pod-network-cidr=10.244.0.0/16
В данном примере будем использован наиболее распространенный сетевой плагин — Flannel. По умолчанию он использует сеть «10.244.0.0/16», которая была указана в параметре, приведенном выше.
При выполнении команды в консоли, есть вероятность появления ошибок или предупреждений
Ошибки нужно исправлять в обязательном порядке, а на предупреждения можно не обращать внимание, если это не окружение «production»
Если все сделано правильно, на экране отобразится команда, позволяющая присоединить остальные ноды кластера к первичному хосту. Команда может отличаться, в зависимости от структуры кластера. Ее нужно сохранить на будущее.
После выполнения этой команды система выведет примерный результат:
![]()
Остается выполнить следующие команды от имени пользователя, который будет управлять кластером:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
Настройка CNI
Перед тем, как начать запускать в кластере приложения, нужно выполнить настройку Container Network Interface («сетевой интерфейс контейнера» или CNI). CNI нужен для настройки взаимодействия и управления контейнерами внутри кластера.
Существует много плагинов для создания CNI. В данном примере применяется Flannel, так как это наиболее простое и проверенное решение. Однако, не меньшей популярностью пользуются плагины Weave Net от компании Weaveworks и Calico (Project Calico), обладающие более широким функционалом и возможностями сетевых настроек.
Чтобы установить Flannel, выполните в терминале команду:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
![]()
В выводе будут отображены имена всех созданных ресурсов.
Добавление узлов (нод) в кластер
Чтобы добавить новые ноды в существующий кластер, требуется выполнить следующий алгоритм:
- Подключиться к серверу через SSH.
- Установить на сервер Docker, Kubelet, Kubeadm (как показано выше).
- Выполнить команду:
kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
Данная команда была выведена при выполнении команды «kubeadm init» на мастер-ноде.
Если команда не была сохранена, то можно ее составить повторно.
Получение токена авторизации кластера (<token>)
- Подключиться к серверу через SSH.
- Запустить команду, которая присутствовала на выводе команды «kubeadm init». Например:
kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
Если токена нет, его можно получить, выполнив следующую команду на мастер-ноде:
kubeadm token list
Вывод должен быть примерно таков:
По умолчанию, срок действия токена — 24 часа. Если требуется добавить новый узел в кластер по окончанию этого периода, можно создать новый токен следующей командой:
kubeadm token create
Вывод будет примерно таков:
5didvk.d09sbcov8ph2amjw
Если значение параметра «—discovery-token-ca-cert-hash» неизвестно, его можно получить следующей командой:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \ openssl dgst -sha256 -hex | sed 's/^.* //'
Будет получен примерно такой вывод:
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
Для ввода IPv6-адреса в параметр «<control-plane-host>:<control-plane-port>», адрес должен быть заключен в квадратные скобки. Например:
:2073
- Должен быть получен вывод следующего вида:
- Спустя несколько секунд нода должна появиться в выводе команды:
kubectl get nodes
Дополнительные настройки
В дефолтной конфигурации мастер-нода не запускает контейнеры, так как занимается отслеживанием состояния кластера и перераспределением ресурсов. Ввод данной команды даст возможность запускать контейнеры на мастере, собенно, если кластер содержит лишь одну ноду:
kubectl taint nodes --all node-role.kubernetes.io/master-
Проверка работоспособности кластера
Проверить, что кластер запустился и правильно работает, можно так:
kubectl -n kube-system get pods
Вывод будет аналогичен. В нем будут отображены системные POD’ы k8s.
![]()
Теперь установку можно считать завершенной. Далее можно продолжить настройку K8s для работы с веб-приложениями. Например, подключить диспетчер пакетов «helm» для автоматического развертывания приложений или контроллер «nginx ingress», отвечающий за маршрутизацию внешнего трафика.

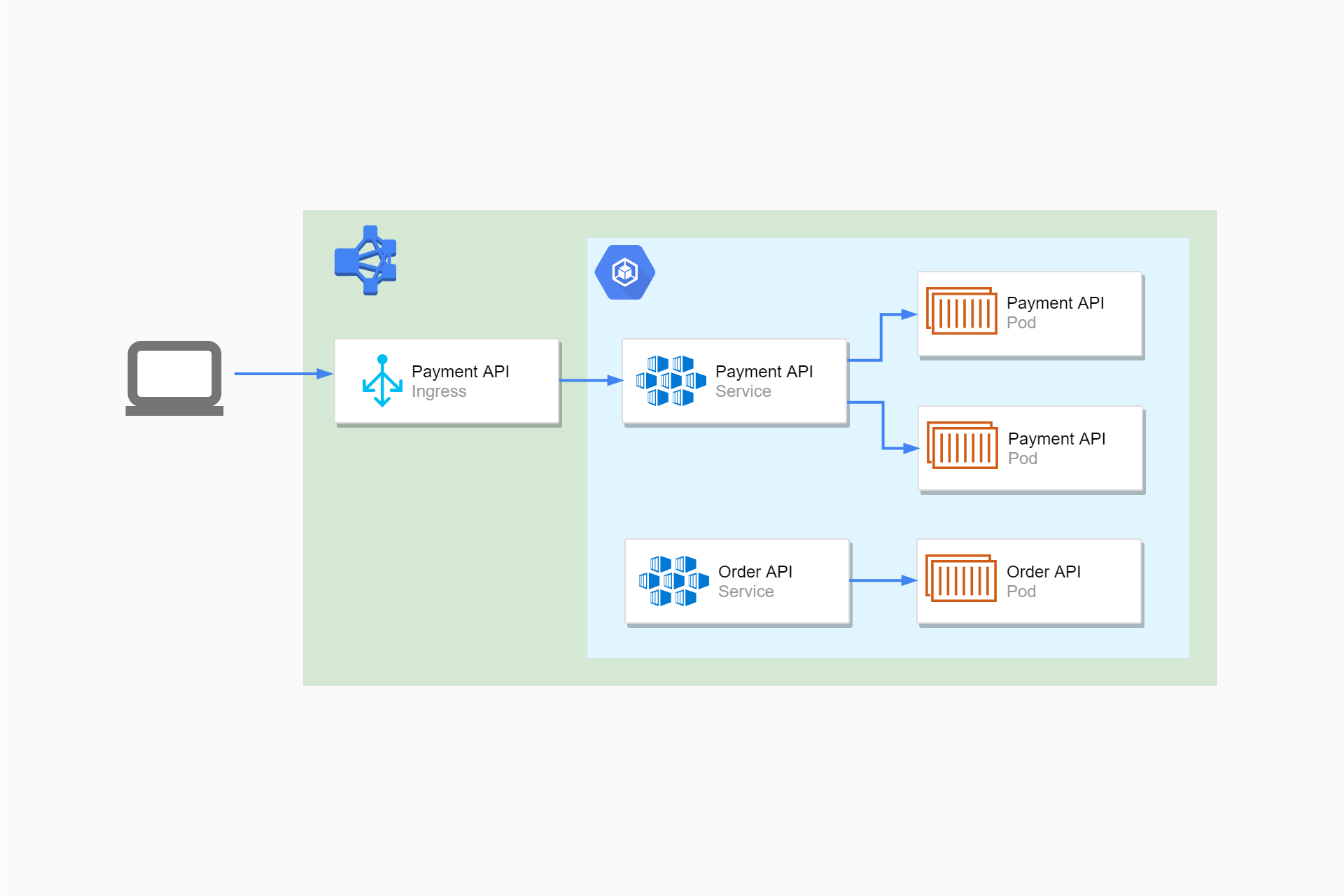
How Pods with resource limits are run
When the kubelet starts a Container of a Pod, it passes the CPU and memory limits
to the container runtime.
When using Docker:
-
The is converted to its core value,
which is potentially fractional, and multiplied by 1024. The greater of this number
or 2 is used as the value of theflag in the command.
-
The is converted to its millicore value and
multiplied by 100. The resulting value is the total amount of CPU time in microseconds
that a container can use every 100ms. A container cannot use more than its share of
CPU time during this interval.Note: The default quota period is 100ms. The minimum resolution of CPU quota is 1ms.
-
The is converted to an integer, and
used as the value of theflag in the command.
If a Container exceeds its memory limit, it might be terminated. If it is
restartable, the kubelet will restart it, as with any other type of runtime
failure.
If a Container exceeds its memory request, it is likely that its Pod will
be evicted whenever the node runs out of memory.
A Container might or might not be allowed to exceed its CPU limit for extended
periods of time. However, it will not be killed for excessive CPU usage.
To determine whether a Container cannot be scheduled or is being killed due to
resource limits, see the
section.
Monitoring compute & memory resource usage
The resource usage of a Pod is reported as part of the Pod status.
If optional tools for monitoring
are available in your cluster, then Pod resource usage can be retrieved either
from the
directly or from your monitoring tools.
Resource types
CPU and memory are each a resource type. A resource type has a base unit.
CPU represents compute processing and is specified in units of .
Memory is specified in units of bytes.
If you’re using Kubernetes v1.14 or newer, you can specify huge page resources.
Huge pages are a Linux-specific feature where the node kernel allocates blocks of memory
that are much larger than the default page size.
For example, on a system where the default page size is 4KiB, you could specify a limit,
. If the container tries allocating over 40 2MiB huge pages (a
total of 80 MiB), that allocation fails.
Note: You cannot overcommit resources.
This is different from the and resources.
CPU and memory are collectively referred to as compute resources, or resources. Compute
resources are measurable quantities that can be requested, allocated, and
consumed. They are distinct from
API resources. API resources, such as Pods and
Services are objects that can be read and modified
through the Kubernetes API server.
Running an example Job
Here is an example Job config. It computes π to 2000 places and prints it out.
It takes around 10s to complete.
You can run the example with this command:
The output is similar to this:
Check on the status of the Job with :
The output is similar to this:
To view completed Pods of a Job, use .
To list all the Pods that belong to a Job in a machine readable form, you can use a command like this:
The output is similar to this:
Here, the selector is the same as the selector for the Job. The option specifies an expression
with the name from each Pod in the returned list.
View the standard output of one of the pods:
The output is similar to this:
Conclusion
In this Kubernetes Tutorial we learned about Kubernetes job scheduler for jobs that need to run sometime in the future can be created through CronJob resources. In normal circumstances, a CronJob always creates only a single Job for each execution configured in the schedule, but it may happen that two Jobs are created at the same time, or none at all. To combat the first problem, your jobs should be idempotent (running them multiple times instead of once shouldn’t lead to unwanted results). For the second problem, make sure that the next job run performs any work that should have been done by the previous (missed) run.
2 ответа
Лучший ответ
Из одного из комментариев я вижу, что вы используете Helm, поэтому я хотел бы предложить решение, использующее хуков Helm:
Вы можете упаковать свою миграцию как k8s и использовать ловушку или для запуска задания. Эти перехваты запускаются после рендеринга шаблонов, но до создания любых новых ресурсов в Kubernetes. Таким образом, ваши миграции будут выполняться до развертывания ваших модулей.
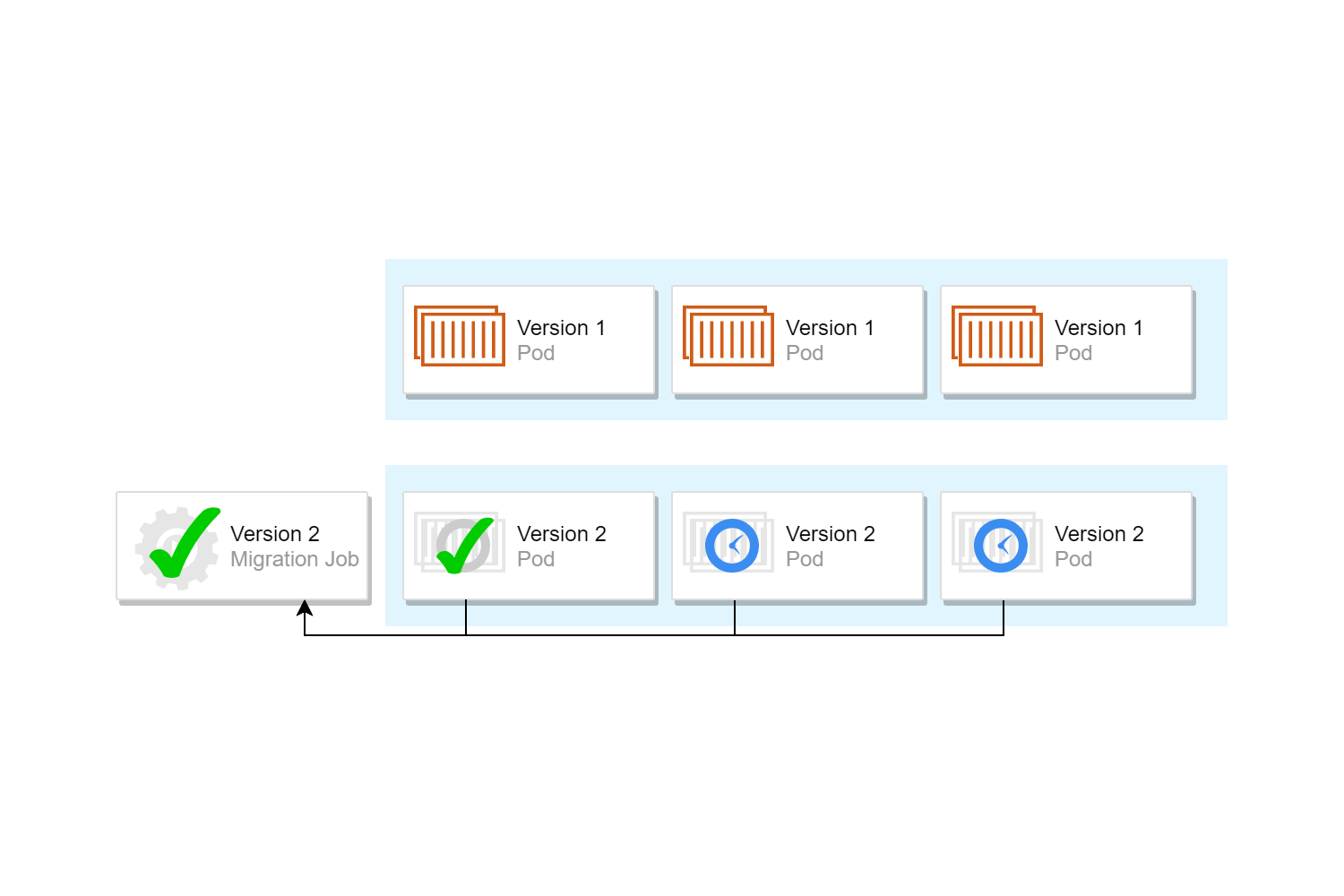
Чтобы удалить развертывания до запуска ваших миграций, создайте второй хук перед установкой / обновлением с нижним , который удаляет целевые развертывания:
Меньший вес крючка обеспечит выполнение этой работы до выполнения миграции. Это обеспечит следующую серию событий:
- Вы запускаете
- Крюк штурвала с наименьшим весом крюка запускает и удаляет соответствующие развертывания
- Второй хук запускает и запускает ваши миграции
- Ваша диаграмма будет установлена с новыми развертываниями, модулями и т. Д.
Просто убедитесь, что все соответствующие развертывания находятся на одной диаграмме.
14
Ivan Aracki
17 Дек 2019 в 08:01
Это во многом зависит от вашего подхода, в частности от ваших инструментов CI / CD. Есть несколько стратегий, которые вы можете применить, но, в качестве иллюстрации, предположим, что у вас есть конвейер Gitlab (Дженкинс мог бы сделать то же самое, терминология отличается и т. Д.), Вот шаги:
Сделайте следующие шаги в gitlab-ci.yaml: Сборка (где вы создаете все необходимые образы и подготавливаете миграции перед развертыванием)
Остановить все затронутые активы — развертывание, службы, наборы состояний (это можно сделать как довольно простой kubectl delete -f all_required_assets.yaml, где в одном манифесте вы определили все ресурсы, которые вы хотите полностью остановить. Вы также можете установить льготный период или принудительное завершение, и вам не нужно удалять статические ресурсы — только связанные с остановкой
Обратите внимание, что для остановки модулей вам необходимо удалить их ресурс создания верхнего уровня, будь то модуль, развертывание, контроллер репликации или Statefulset, чтобы остановить их полностью, а не просто перезапустить)
Миграция , реализованная в виде Job или Pod, которая будет обрабатывать миграции с базой данных (например, kubectl create -f migrate_job.yaml). Предпочтительная работа для отслеживания ошибок после ее завершения
Начать все активы (тот же файл манифеста с определениями затронутых ресурсов, что и для этапа остановки, скажем, kubectl create -f all_required_assets.yaml, и все ресурсы запуска / остановки обрабатываются через один файл
Если запуск порядок важен по любой причине, тогда требуется отдельный файл, но с осторожностью следует рассмотреть один файл для большинства сценариев)
Этот тот же принцип может быть реализован и в других инструментах оркестровки / развертывания, и вы даже можете создать простой скрипт для непосредственного запуска этих команд kubectl, если предыдущая была успешной.
Const
7 Май 2018 в 21:16
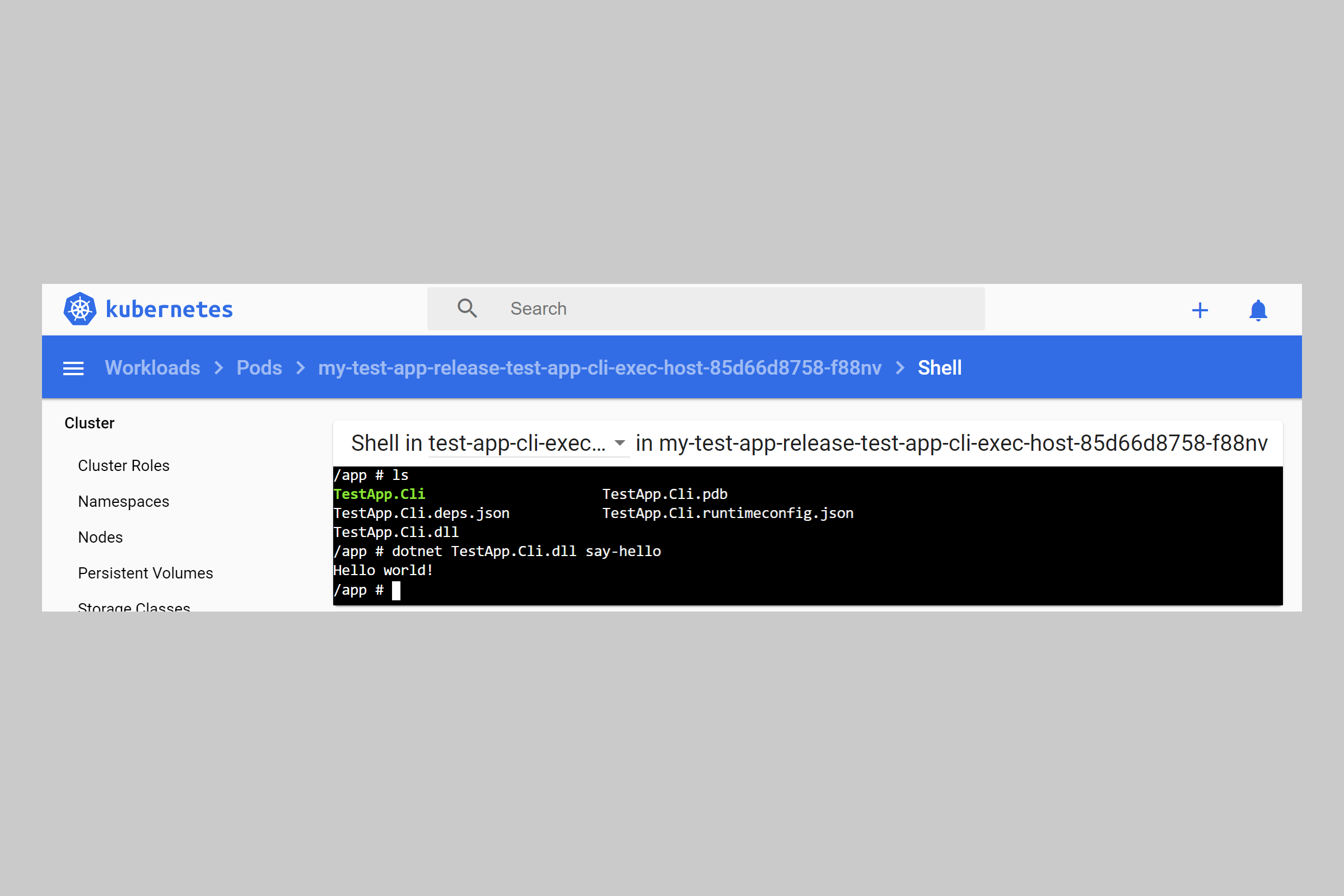
Monitor status of CronJob in Kubernetes
Job resources will be created from the resource at approximately the scheduled time. The Job then creates the pods. Once a cronjob is started, you can first use to list the available cron jobs. Now when the job is planned to be executed then you can use following command to get the LIVE runtime status:
# kubectl get jobs --watch NAME COMPLETIONS DURATION AGE pod-cronjob-1606577040 0/1 0s pod-cronjob-1606577040 0/1 0s 0s
Here as you see the first planned cronjob has started, you can get more details using following command where you can see that a new job is started with current status as :
# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx 1/1 Running 1 9h 10.44.0.1 worker-2.example.com <none> <none> nginx-lab 1/1 Running 1 9h 10.44.0.2 worker-2.example.com <none> <none> pod-add-settime-capability 1/1 Running 1 8h 10.44.0.4 worker-2.example.com <none> <none> pod-as-user-guest 1/1 Running 1 8h 10.44.0.3 worker-2.example.com <none> <none> pod-cronjob-1606577040-tnnb5 0/1 ContainerCreating 0 7s <none> worker-1.example.com <none> <none> pod-drop-chown-capability 1/1 Running 1 7h50m 10.44.0.5 worker-2.example.com <none> <none> pod-privileged 1/1 Running 1 8h 10.36.0.3 worker-1.example.com <none> <none>
In few seconds once the JOB is complete, you can see that the status of the respective job is shown as completed:
Advertisement
# kubectl get jobs --watch NAME COMPLETIONS DURATION AGE pod-cronjob-1606577040 1/1 12s 12s
Now similarly another job will start in another 2 minutes as planned in our kubernetes job scheduler:
# kubectl get jobs --watch NAME COMPLETIONS DURATION AGE pod-cronjob-1606577040 1/1 12s 109s pod-cronjob-1606577160 0/1 0s pod-cronjob-1606577160 0/1 0s 0s
In some time once the job is executed, then the status should be again shown as completed for the respective Pod:
# kubectl get pods NAME READY STATUS RESTARTS AGE nginx 1/1 Running 1 9h nginx-lab 1/1 Running 1 9h pod-add-settime-capability 1/1 Running 1 8h pod-as-user-guest 1/1 Running 1 8h pod-cronjob-1606577040-tnnb5 0/1 Completed 0 2m16s pod-cronjob-1606577160-75xbm 0/1 Completed 0 15s pod-drop-chown-capability 1/1 Running 1 7h52m
Job patterns
In a complex system, there may be multiple different sets of work items. Here we are just
considering one set of work items that the user wants to manage together — a batch job.
There are several different patterns for parallel computation, each with strengths and weaknesses.
The tradeoffs are:
- One Job object for each work item, vs. a single Job object for all work items. The latter is
better for large numbers of work items. The former creates some overhead for the user and for the
system to manage large numbers of Job objects. - Number of pods created equals number of work items, vs. each Pod can process multiple work items.
The former typically requires less modification to existing code and containers. The latter
is better for large numbers of work items, for similar reasons to the previous bullet. - Several approaches use a work queue. This requires running a queue service,
and modifications to the existing program or container to make it use the work queue.
Other approaches are easier to adapt to an existing containerised application.
The tradeoffs are summarized here, with columns 2 to 4 corresponding to the above tradeoffs.
The pattern names are also links to examples and more detailed description.
| Pattern | Single Job object | Fewer pods than work items? | Use app unmodified? |
|---|---|---|---|
| Queue with Pod Per Work Item | ✓ | sometimes | |
| Queue with Variable Pod Count | ✓ | ✓ | |
| Indexed Job with Static Work Assignment | ✓ | ✓ | |
| Job Template Expansion | ✓ |
When you specify completions with , each Pod created by the Job controller
has an identical . This means that
all pods for a task will have the same command line and the same
image, the same volumes, and (almost) the same environment variables. These patterns
are different ways to arrange for pods to work on different things.
This table shows the required settings for and for each of the patterns.
Here, is the number of work items.
| Pattern | ||
|---|---|---|
| Queue with Pod Per Work Item | W | any |
| Queue with Variable Pod Count | null | any |
| Indexed Job with Static Work Assignment | W | any |
| Job Template Expansion | 1 | should be 1 |
Проверки доступности Probes
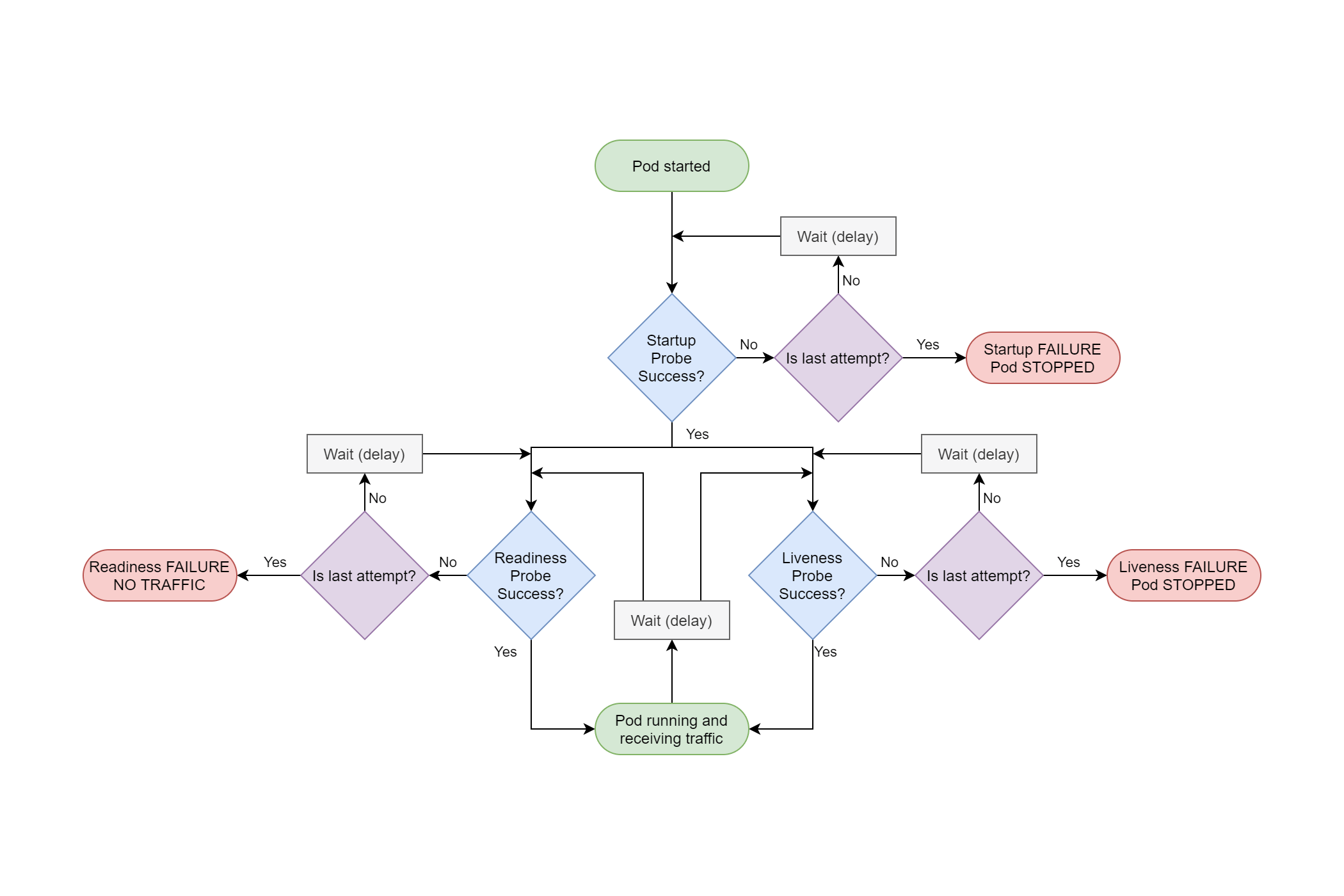
С деплоем и перезапуском подов не все так просто. Есть тяжелые приложения, которые стартуют очень долго, либо зависят от других приложений. Прежде чем погасить старую версию, нужно убедиться, что новая уже запущена и готова к работе. Для этого существует liveness и readiness проверки. Покажу на примере. Берем предыдущий deployment и добавляем туда проверки.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-nginx
spec:
replicas: 2
selector:
matchLabels:
app: my-nginx
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx:1.16
name: nginx
ports:
- containerPort: 80
readinessProbe:
failureThreshold: 5
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 2
timeoutSeconds: 3
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
initialDelaySeconds: 10
В данном примере используется проверка httpGet по корневому урлу на порт 80.
- readinessProbe проверяет способность приложения начать принимать трафик. Она делает 5 проверок (failureThreshold). Если хотя бы 2 (successThreshold) из них будут удачными, считается, что приложение готово. Метод httpGet проверяет код ответа веб сервера. Если он 200 или 3хх, то считается, что все в порядке. Эта проверка выполняется до тех пор, пока не будет выполнено заданное на успех условие — successThreshold. После этого прекращается.
- livenessProbe выполняется постоянно, следя за приложением во время его жизни. В моем примере проверка будет неудачной, если 3 (failureThreshold) проверки подряд провалились. При этом, если хотя бы одна (successThreshold) будет удачной, то счетчик неудачных сбрасывается. Параметр initialDelaySeconds задает задержку после старта пода для начала liveness проверок.
Вот еще один пример liveness проверки, но уже по наличию файла. Проверяется файл /tmp/healthy, если он существует, проверка удачна, если его нет, то ошибка.
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
Создавать этот файл может само приложение во время работы.
CronJob limitations
A cron job creates a job object about once per execution time of its schedule. We say «about» because there
are certain circumstances where two jobs might be created, or no job might be created. We attempt to make these rare,
but do not completely prevent them. Therefore, jobs should be idempotent.
If is set to a large value or left unset (the default)
and if is set to , the jobs will always run
at least once.
Caution: If is set to a value less than 10 seconds, the CronJob may not be scheduled. This is because the CronJob controller checks things every 10 seconds.
For every CronJob, the CronJob Controller checks how many schedules it missed in the duration from its last scheduled time until now. If there are more than 100 missed schedules, then it does not start the job and logs the error
It is important to note that if the field is set (not ), the controller counts how many missed jobs occurred from the value of until now rather than from the last scheduled time until now. For example, if is , the controller counts how many missed jobs occurred in the last 200 seconds.
A CronJob is counted as missed if it has failed to be created at its scheduled time. For example, If is set to and a CronJob was attempted to be scheduled when there was a previous schedule still running, then it would count as missed.
For example, suppose a CronJob is set to schedule a new Job every one minute beginning at , and its
field is not set. If the CronJob controller happens to
be down from to , the job will not start as the number of missed jobs which missed their schedule is greater than 100.

To illustrate this concept further, suppose a CronJob is set to schedule a new Job every one minute beginning at , and its
is set to 200 seconds. If the CronJob controller happens to
be down for the same period as the previous example ( to ,) the Job will still start at 10:22:00. This happens as the controller now checks how many missed schedules happened in the last 200 seconds (ie, 3 missed schedules), rather than from the last scheduled time until now.
The CronJob is only responsible for creating Jobs that match its schedule, and
the Job in turn is responsible for the management of the Pods it represents.
Clean up finished jobs automatically
Finished Jobs are usually no longer needed in the system. Keeping them around in
the system will put pressure on the API server. If the Jobs are managed directly
by a higher level controller, such as
CronJobs, the Jobs can be
cleaned up by CronJobs based on the specified capacity-based cleanup policy.
TTL mechanism for finished Jobs
FEATURE STATE:
Another way to clean up finished Jobs (either or )
automatically is to use a TTL mechanism provided by a
TTL controller for
finished resources, by specifying the field of
the Job.
When the TTL controller cleans up the Job, it will delete the Job cascadingly,
i.e. delete its dependent objects, such as Pods, together with the Job. Note
that when the Job is deleted, its lifecycle guarantees, such as finalizers, will
be honored.
For example:
The Job will be eligible to be automatically deleted,
seconds after it finishes.
If the field is set to , the Job will be eligible to be automatically deleted
immediately after it finishes. If the field is unset, this Job won’t be cleaned
up by the TTL controller after it finishes.
Note:
It is recommended to set field because unmanaged jobs
(Jobs that you created directly, and not indirectly through other workload APIs
such as CronJob) have a default deletion
policy of causing Pods created by an unmanaged Job to be left around
after that Job is fully deleted.
Even though the eventually
the Pods from a deleted Job after they either fail or complete, sometimes those
lingering pods may cause cluster performance degradation or in worst case cause the
cluster to go offline due to this degradation.
You can use LimitRanges and
ResourceQuotas to place a
cap on the amount of resources that a particular namespace can
consume.





