Введение
Для начала приведу несколько полезных ссылок на тему Yandex.Tank. Они все почему-то разрозненные и не связаны логически друг с другом. Функционал этого инструмента обширный, я же рассмотрю достаточно простой пример, поэтому точно пригодится документация.
- Документация — https://yandextank.readthedocs.io/
- Исходники — https://github.com/yandex-load/yandex-tank
- Сервис визуализации — https://overload.yandex.net/
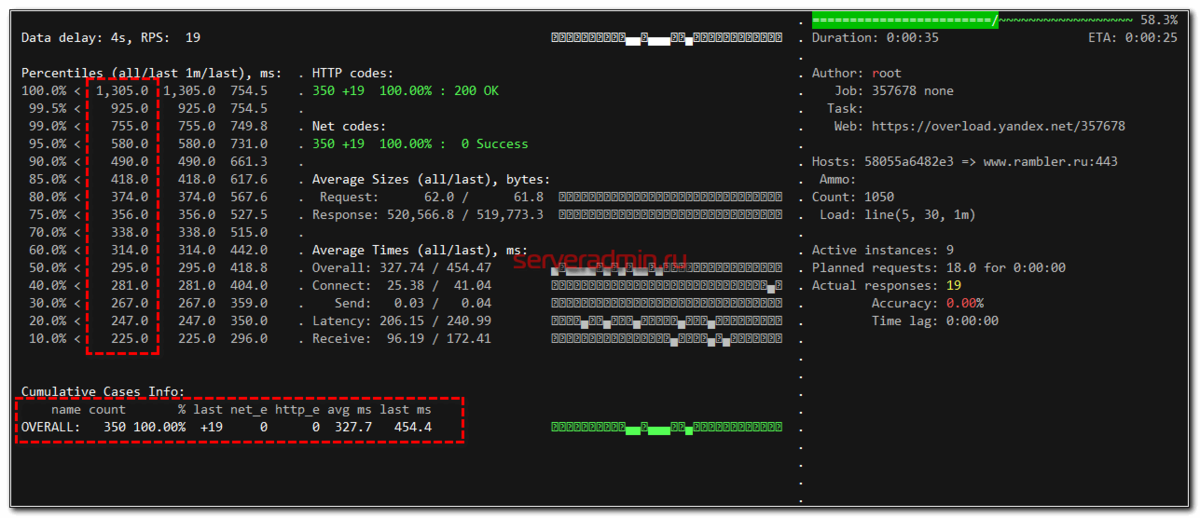
Первым делом сходите на overload.yandex.net, зарегистрируйтесь там и получите токен. Он нам нужен будет далее, чтобы в удобном виде просматривать визуализацию результатов. Это не обязательное условие для совершения тестов и можно обойтись без него. Будет простенький вывод в консоли, с помощью которого можно оценить результат нагрузочного тестирования. Но с помощью модуля overload гораздо удобнее и нагляднее интерпретировать полученные данные.
Пример использования
Выполним нагрузочное тестирование базы данных с помощью Apache JMeter. Чтобы измерить ее производительность, используем драйвер MySQL JDBC.
План тестирования базы данных
План тестирования описывает последовательность шагов, которые должен выполнить JMeter. Для его составления необходимы следующие элементы:
- Группа потоков.
- Запрос JDBC.
- Сводный отчет.
Добавление пользователей
Группа потоков предоставляет подробную информацию о количестве пользователей, частоте и количестве запросов, которые будут отправлены пользователями во время тестирования.
Чтобы создать группу потоков, выполните следующие действия:
- В левой панели кликните правой кнопкой мыши по Test Plan.
- Выберите Add→ Threads (Users) → Thread Group.
- Укажите имя группы потоков – «JDBC Users».
- Нажмите кнопку Add и измените значения свойств, используемые по умолчанию, следующим образом:
- No. of Threads (users): 10.
- Ramp-Up Period (in seconds): 100.
- Loop Count: 10.
Примечание. Ramp-Up Period указывает время, необходимое для увеличения количества потоков до максимального значения.
Мы используем 10 потоков, а период разгона составляет 100 секунд. Каждый новый поток запускается через 10 секунд после начала предыдущего. Таким образом, запрос будет выполнен 10 (потоков) * 10 (циклов) = 100 раз. Аналогично, для 10 таблиц общее количество экземпляров составляет 100.
Добавление запросов JDBC
Чтобы добавить запрос JDBC, выполните следующие действия:
- В левой панели кликните правой кнопкой мыши по Thread Group.
- Выберите Add→ Config Element → JDBC Connection Configuration.
- Настройте следующие параметры:
- Variable Name: myDatabase
Примечание. Это имя должно быть уникальным, так как оно используется JDBC Sampler для идентификации используемой конфигурации.
- Database URL:jdbc:mysql://ipOfTheServer:3306/cloud
- JDBC Driver class:mysql.jdbc.Driver.
- Username:имя пользователя базы данных.
Password: пароль.
Добавление сэмплера
Чтобы добавить сэмплер, выполните следующие действия:
- В левой панели кликните правой кнопкой мыши по Thread Group.
- Выберите Add→ Sampler → JDBC Request.
- Укажите Variable Name:
Введите запрос в поле SQL Query.
«myDatabase».
Добавление обработчика для просмотра и сохранения результатов теста
Чтобы просмотреть результаты теста, выполните следующие действия:
- В левой панели кликните правой кнопкой мыши по Thread Group.
- Выберите Add→ Listener → View Results Tree/Summary Report/Graph Results.
- Сохраните план тестирования и нажмите Run(Start или «Ctrl + R»), чтобы запустить тест.
- Все результаты теста будут сохранены в обработчике.
Просмотр результатов теста:
Результаты можно просмотреть в древовидном формате:
В табличном представлении:
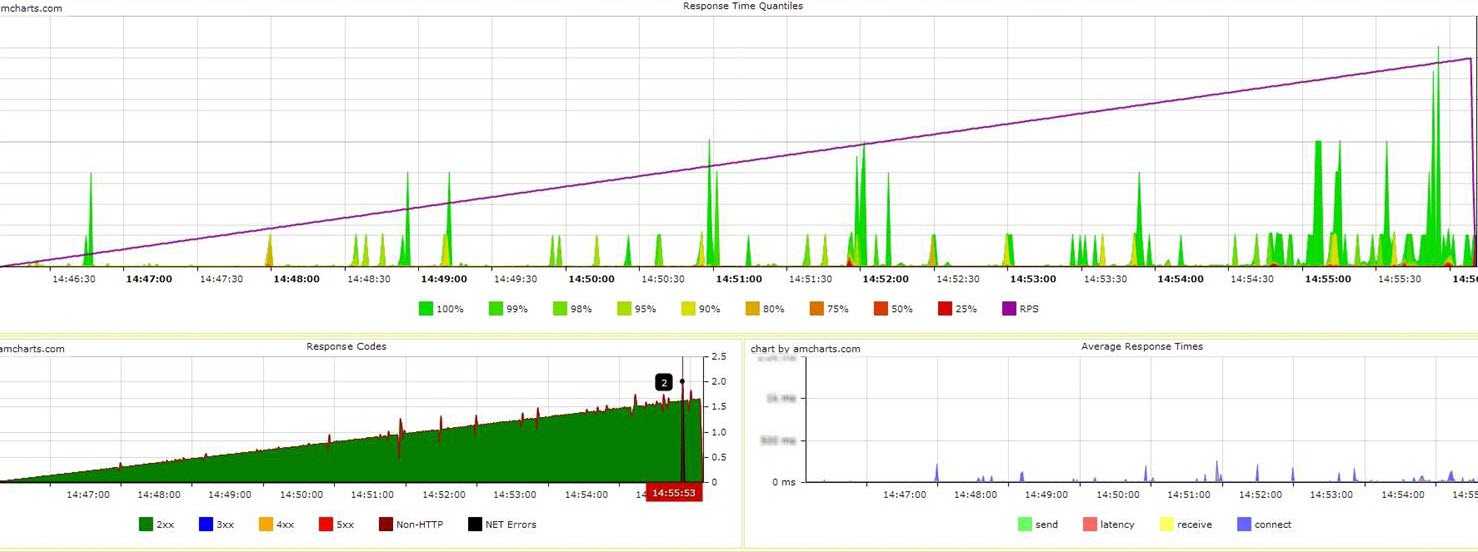
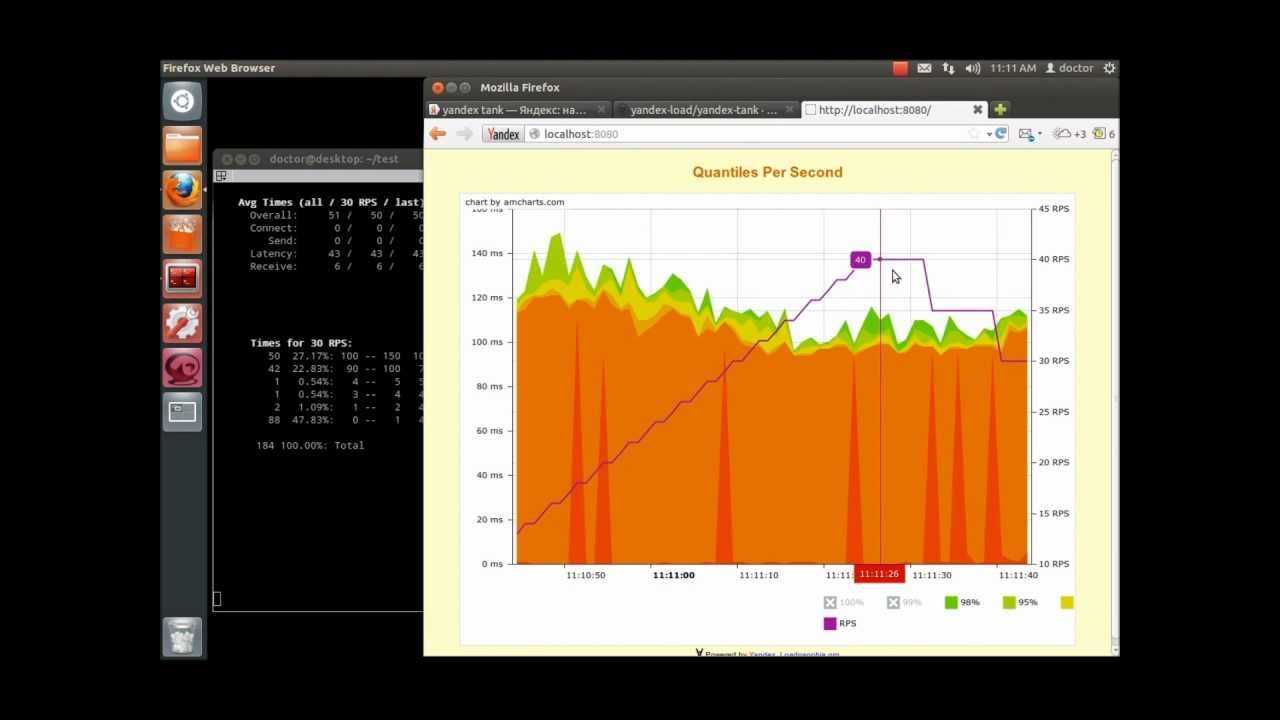
В графическом:
А также в виде диаграмм:
Основные оцениваемые метрики
Некоторые, наиболее общеупотребительные и рекомендуемые в методологии ISTQB (стр. 36, 52) метрики, приведены в таблице ниже.
|
Метрики нагрузочного агента |
Метрики целевой системы или приложения, тестируемых под нагрузкой |
|---|---|
| Количество vCPU и памяти RAM, Disk (в Mb или Gb) — «железные» характеристики нагрузочного агента. | CPU, Memory, Disk usage — динамика загрузки процессора, памяти и диска в процессе тестирования. Обычно измеряется в % от максимально доступных значений. |
| Network throughput (load agent) — пропускная способность сетевого интерфейса на сервере, где установлен нагрузочный агент. Обычно измеряется в байтах в секунду (bps). | Network throughput (target) — пропускная способность сети на целевом сервере. Обычно измеряется в байтах в секунду (bps). |
| Virtual users — количество виртуальных пользователей, реализующих сценарии нагрузки и имитирующие реальные действия пользователей. |
Virtual users status, Passed/Failed/Total — количество успешных, неуспешных статусов работы виртуальных пользователей для сценариев нагрузки, и их общее количество. Обычно ожидается, что все пользователи смогли выполнить все свои задачи, указанные в профиле нагрузки. Любая ошибка будет означать то, что и реальный пользователь не сможет решить свою задачу при работе с системой. |
|
Requests per second (minute) — количество сетевых запросов в секунду (или минуту). Важная характеристика нагрузочного агента: сколько он может генерировать запросов. Фактически, это обращения к приложению виртуальными пользователями. |
Responses per second (minute) — количество сетевых ответов в секунду (или минуту). Важная характеристика целевого сервиса: сколько было получено ответов на отправленные с нагрузочного агента запросы. |
| HTTP responses status — количество различных кодов ответа от сервера приложения. Например, 200 OK означает успешное обращение, а 404, что ресурс не обнаружен. | |
|
Latency (время отклика) — время от окончания отправки запроса (request) до начала приёма ответа (response). Обычно измеряется в миллисекундах (ms). |
|
|
Transaction response time — время одной полной транзакции: завершение цикла запрос – ответ. Это время от начала отправки запроса (request) до завершения приёма ответа (response). Время транзакции может измеряться в секундах (или минутах) несколькими способами: считают минимальное, максимальное, среднее и, например, 90-й перцентиль. Минимальные и максимальные показания показывают крайние состояния производительности системы. 90-й перцентиль используется наиболее часто, поскольку он показывает большинство пользователей, комфортно работающих на пороге производительности системы. |
|
| Transactions per second (minute) — количество полных транзакций в секунду (минуту), то есть сколько приложение смогло принять и обработать запросов и выдать ответов. Фактически, это пропускная способность системы. | |
|
Transactions status, Passed / Failed / Total — количество успешных, неуспешных и общее количество транзакций. Для реальных пользователей неуспешная транзакция фактически будет означать невозможность работы с системой под нагрузкой. |
Установка Telegraf
Выполним установку Telegraf для различных операционных систем. В зависимости от текущей версии агента, команды будут разные. Поэтому мы переходим на страницу загрузки influxdata и кликаем по последней версии telegraf:
* на момент написания инструкции это была v1.14.1.
В открывшемся окне мы увидим конкретные команды для загрузки и установки Telegraf под различные операционные системы.
Linux CentOS (Red Hat / Fedora)
Устанавливаем утилиту для загрузки файлов:
yum install wget
Согласно инструкции на сайте influxdata.com, загружаем пакет установки:
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.14.1-1.x86_64.rpm
* напоминаю, что версия может быть другой.
Устанавливаем загруженный пакет:
yum localinstall telegraf-*.rpm
Linux Ubuntu (Debian / Mint)
По инструкции на influxdata.com, скачиваем пакет установки:
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.14.1-1_amd64.deb
* обратите внимание, что версия может быть другой. Устанавливаем скачанный пакет:
Устанавливаем скачанный пакет:
dpkg -i telegraf_*.deb
Windows
- Для x32 (i386) — https://dl.influxdata.com/telegraf/releases/telegraf-1.14.1_windows_i386.zip.
- Для x64 (amd64) — https://dl.influxdata.com/telegraf/releases/telegraf-1.14.1_windows_amd64.zip.
Создаем каталог Telegraf в папке Program Files. В моем случае, получился путь C:\Program Files\Telegraf. Распаковываем в него содержимое скачанного архива — файлы telegraf.conf и telegraf.exe.
Теперь открываем командную строку от администратора и запускаем установку Telegraf в качестве службы:
«C:\Program Files\Telegraf\telegraf.exe» —service install
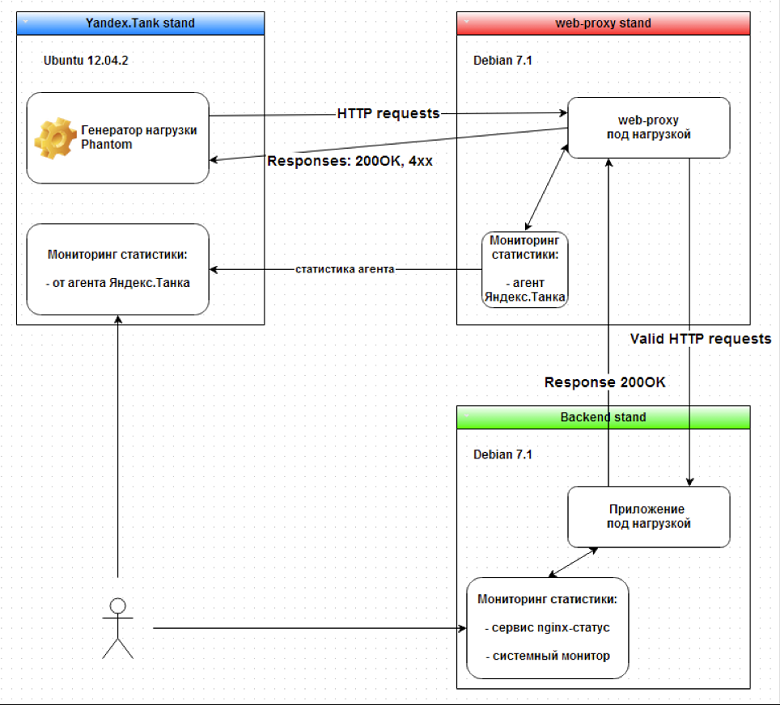
Настройка и стандартные режимы работы Яндекс.Танка
Для разворачивания нагрузочного стенда мы использовали виртуальную машину с Ubuntu 12.04.2 Server x64.
Установка Яндекс.Танка из пакета осуществляется одной простой командой:
sudo apt-get install yandex-tank-base
Настройка профилей производится в файлах с расширением *.ini, которые должны находиться в директории /etc/yandex-tank/
Запуск Яндекс.Танка осуществляется под рутом одной командой (при этом нужно находиться в директории с ini-файлами):
yandex-tank
После запуска Яндекс.Танк ищет ini-файлы с конфигурациями профилей нагрузки, а также подгружает, при указании ammo_file, так называемый патрон — специальным образом подготовленный файл с http-запросами. Простейшие GET http-запросы можно указать в файле со стандартным профилем load.ini. Из заданного патрона Яндекс.Танк предварительно готовит ленту запросов, генерируя *.stpd-файлы. Лента хранит сразу все запросы, которые будут отправлены в течение теста для определенного профиля. После смены патрона или настроек профиля она будет сгенерирована заново.
Задание профилей нагрузки через стандартный файл с настройками load.ini
address=example.com:80 ; Target's address and port rps_schedule=const(65000,2m) ; load scheme header_http = 1.1 headers = uris = /test port = 80 ; interval = 1 ; manualstop = 1 ;
Задание профиля включает в себя определение тегов с параметрами настроек:
- используемый генератор нагрузки,
- адрес нагружаемого веб-сервера и его порт,
- используемая схема нагрузки.
Далее указываются, формируя при этом патрон, используемый при нагрузке:
- хедеры http-пакета,
- путь для GET-запроса (uris).
Дополнительно могут задаваться параметры веб-интерфейса Яндекс.Танка (тег рассмотрен ниже).
Файлы с настройками чувствительны к пробелам: для задания комментария после параметра требуется указывать один пробел и точку с запятой, затем ещё один пробел.
В приведённом примере:
— используемый генератор нагрузки, можно также указать модуль JMeter, тег .
rps_schedule — схема нагрузки. В ней можно указать одну из функций: const(load,dur), line(a,b,dur), step(a,b,step,dur), либо комбинации данных функций.
Например, комбинация:
rps_schedule=const(1,30s) line(1,1000,2m) const(1000,3h)
задаёт схему нагрузки при использовании которой нагрузка в 1 http-rps будет держаться в течении 30 секунд, затем нагрузка будет линейно возрастать с 1 до 1000 http-rps в течении 2 минут, после чего будет держаться на уровне 1000 http-rps в течение 3 часов.
step(a,b,step,dur) — пошаговое увеличение нагрузки, где a и b начальное и конечное значения нагрузки в http-rps, step — шаг увеличения нагрузки, dur — время, через которое увеличивается нагрузка на указанный шаг.
line(a,b,dur) — линейная нагрузка, где a и b — начальная и конечная нагрузка, dur — время, в течение которого нагрузка линейно увеличивается от a до b.
const(load,dur) — постоянная нагрузка, где load — значение нагрузки, dur — время нагрузки.
Запросы можно размещать как в теге файла load.ini, так и в отдельном файле-патроне.
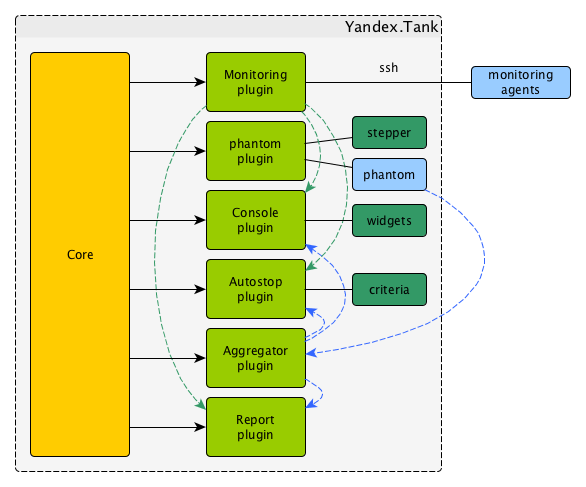
Вкратце об инструменте Яндекс.Танк
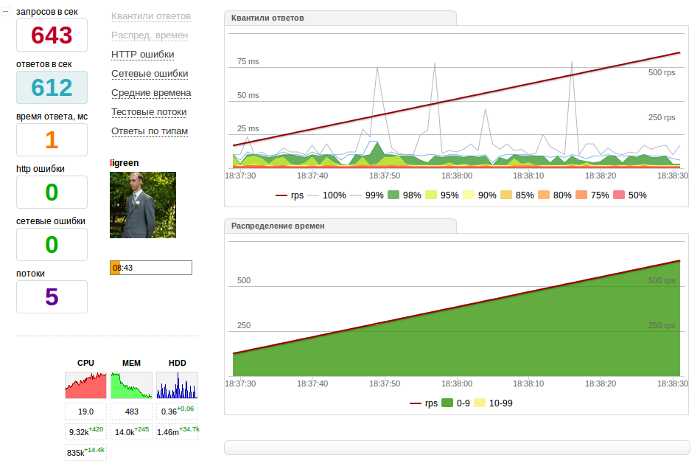
Яндекс.Танк — инструмент для проведения нагрузочного тестирования, разрабатываемый в компании Яндекс и распространяемый под лицензией LGPL.
В основе инструмента лежит высокопроизводительный асинхронный генератор нагрузки phantom, который был изначально переделан из одноимённого веб-сервера, который «научили» работать в режиме клиента. При помощи phantom возможно генерировать десятки и сотни тысяч http-запросов в секунду (далее http-rps — http-requests per second).
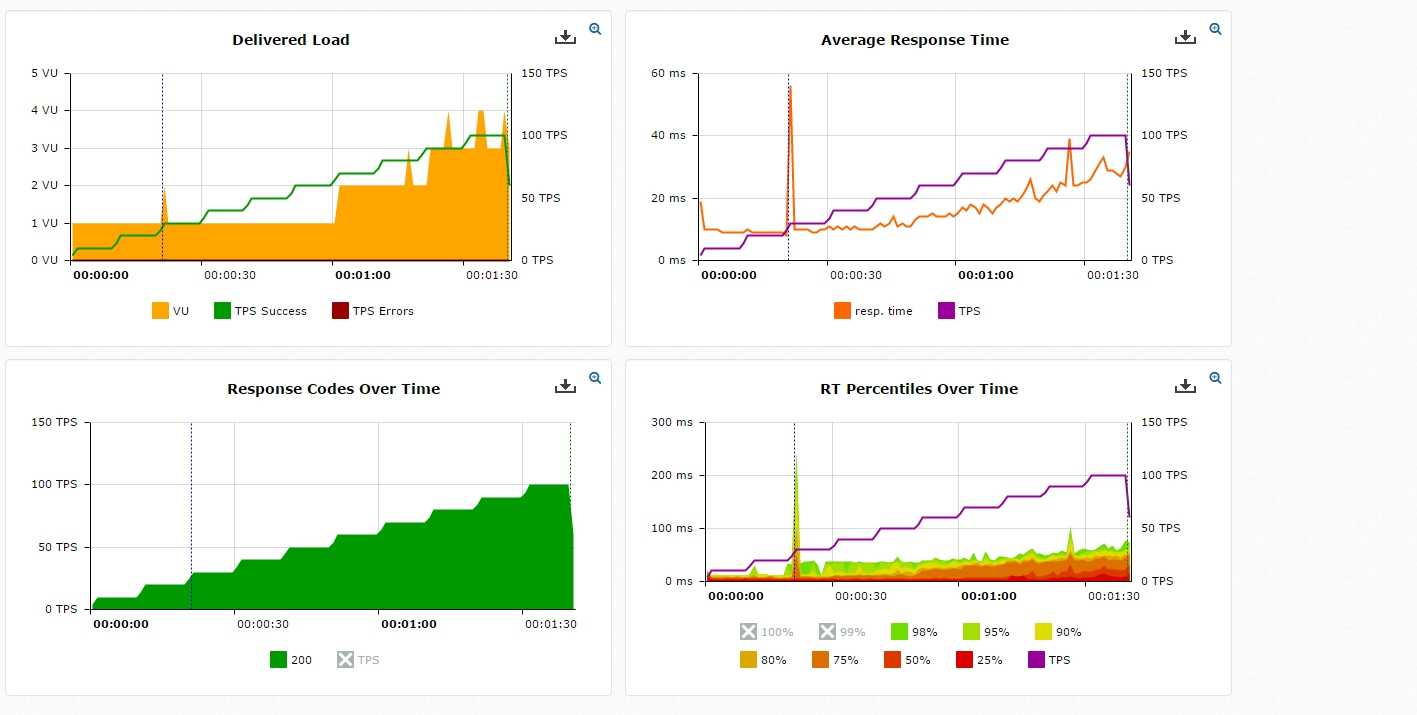
В процессе своей работы Яндекс.Танк сохраняет полученные результаты в обычных текстовых лог-файлах, сгруппированных по директориям для отдельных тестов. В течение теста специальный модуль организует вывод результатов в табличном виде в консольный интерфейс. Одновременно с этим запускается локальный веб-сервер, позволяющий видеть те же самые результаты на информативных графиках. По окончании теста возможно автоматическое сохранение результатов на сервисе Loadosophia.org. Также имеется модуль загрузки результатов в хранилище Graphite.
Некоторые полезные ссылки:
- Код проекта на GitHub:https://github.com/yandex-load/yandex-tank
- Официальная документация по настройке и использованию инструмента:http://yandextank.readthedocs.org/en/latest/
- Информация о модулях Яндекс.Танка в wiki разработчиков:https://github.com/yandex-load/yandex-tank/wiki/%D0%9C%D0%BE%D0%B4%D1%83%D0%BB%D0%B8
- Презентация, в которой рассказывается об истории возникновения инструмента:http://tech.yandex.ru/events/yasubbotnik/msk-jul-2012/talks/296/
- История возникновения сервиса нагрузочного тестирования в Яндексе и разработка Яндекс.Танка:http://habrahabr.ru/company/yandex/blog/202020/
- Яндекс-клуб, посвященный вопросам использования инструмента:http://clubs.ya.ru/yandex-tank/
Функциональные особенности Яндекс.Танка:
- возможность простого конфигурирования инструмента используя ini-файлы, либо опции командной строки;
- гибкая настройка профилей нагрузки;
- настраиваемый авто-стоп теста по различным критериям, например, если время отклика сервера превышает заданный порог или допустимое количество сетевых ошибок;
- высокая производительность (до 300k http-rps на стенде 16 vCPU, 8 GB, 10 Gb/s) при использовании генератора phantom, которая однако, может быть ограничена производительностью тестируемого веб-сервера — до ~64k http-rps, связанной с количеством одновременно открываемых соединений;
- наглядная визуализация процесса тестирования с использованием локального веб-сервера, а также наличие подробной статистической информации в консоли;
- наличие собственного агента для мониторинга ресурсов на стороне сервера с тестируемым веб-приложением по протоколу ssh;
- возможность использовать Apache Jmeter в качестве альтернативного генератора нагрузки.
TankCore¶
Core class. Represents basic steps of test execution. Simplifies plugin configuration,
configs reading, artifacts storing. Represents parent class for modules/plugins.
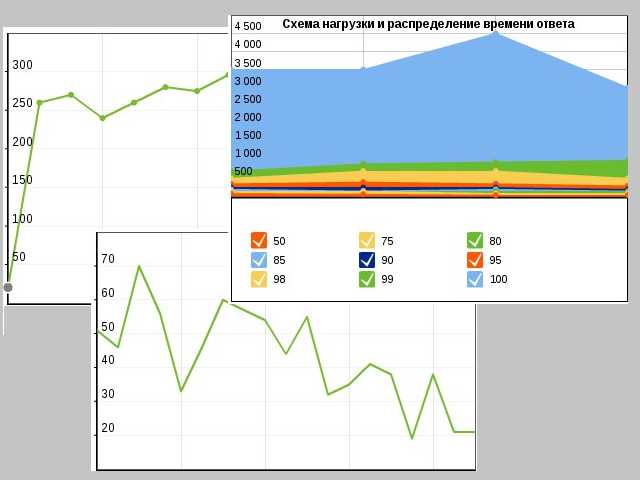
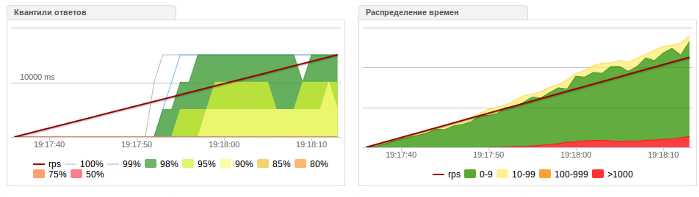
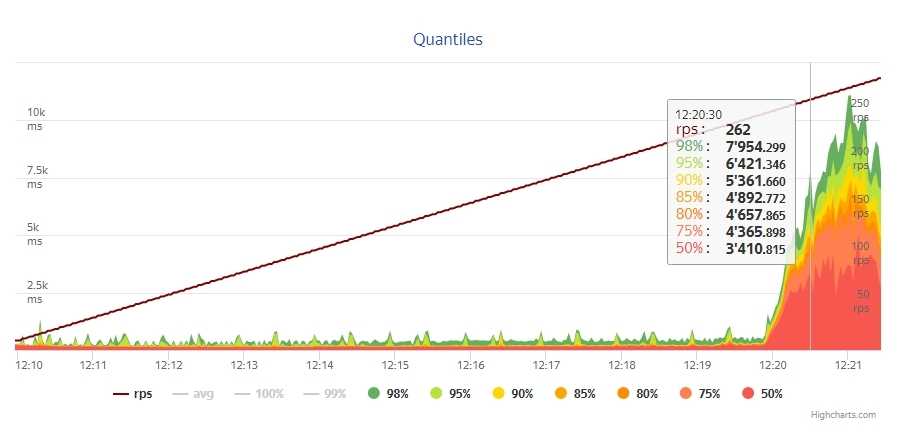

yaml file section: core
Options
Basic options:
| lock_dir: |
Directory for lockfile. Default: . |
|---|---|
| plugin_<pluginname>: | |
|
Path to plugin. Empty path interpreted as disable of plugin. |
|
| artifacts_base_dir: | |
|
Base directory for artifacts storing. Temporary artifacts files are stored here. Default: current directory. |
|
| artifacts_dir: |
Directory where to keep artifacts after test. Default: directory in named in Date/Time format. |
| flush_config_to: | |
|
Dump configuration options after each tank step |
|
| taskset_path: |
Path to taskset command. Default: taskset. |
| affinity: |
Set a yandex-tank’s (python process and load generator process) CPU affinity. Default: empty. Example: enabling first 4 cores, ‘0,1,2,16,17,18’ enabling 6 cores. |
consoleworker
Consoleworker is a cmd-line interface for Yandex.Tank.
Worker class that runs and configures TankCore accepting cmdline parameters.
Human-friendly unix-way interface for yandex-tank.
Command-line options described above.
apiworker
Worker class for python. Runs and configures TankCore accepting .
Python-frinedly interface for yandex-tank.
Example:
from yandextank.api.apiworker import ApiWorker
import logging
import traceback
import sys
logger = logging.getLogger('')
logger.setLevel(logging.DEBUG)
#not mandatory options below:
options = dict()
options'config' = '/path/to/config/load.ini'
options'manual_start' = "1"
options'user_options' =
'phantom.ammofile=/path/to/ammofile',
'phantom.rps_schedule=const(1,2m)',
log_filename = '/path/to/log/tank.log'
#======================================
apiworker = ApiWorker()
apiworker.init_logging(log_filename)
try
apiworker.configure(options)
apiworker.perform_test()
except Exception, ex
logger.error('Error trying to perform a test: %s', ex)
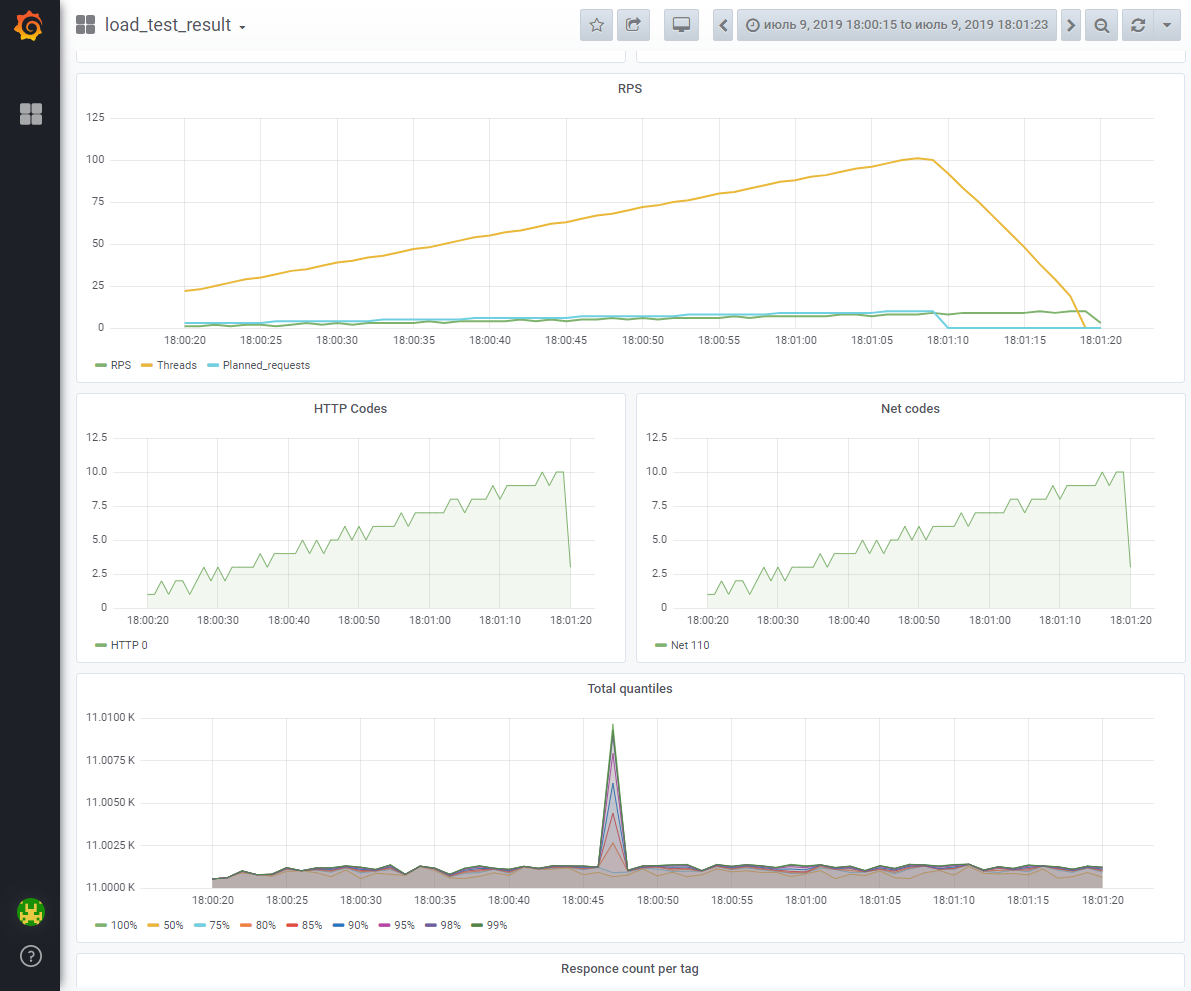
Установка и настройка Grafana
Почти готово — осталось настроить дашборд для отображения собранных метрик.
Установим и запустим Grafana:
По умолчанию grafana запустится на порту 3000. Идем браузером на http://host:3000/login, видим окно:
![]()
Авторизуемся, используя стандартные логин и пароль: admin / admin.
Если чуда не произошло и на порту 3000 искомого веб-интерфейса мы не увидели, смотрим логи в /var/log/grafana.
В интерфесе первым делом настраиваем источник данных (datasources — add datasource):
![]()
Далее создаем свой первый дашборд и следуя подсказкам интерфейса конструируем запрос, например так:
![]()
Дальнейший процесс носит скорее творческий, чем технический характер. По большому счету можно и не знать синтаксис SQL, а ориентироваться на настройки, предоставляемые интерфейсом Grafana.
Создав dashboard, мы можем его экспортировать в json-формате и в дальнейшем загрузить на другом хосте. Мы будем активно использовать эту возможность при создании ansible-скрипта.
Еще один важный момент — понимание того, что все операции, которые могут быть совершены в Grafana через интерфейс, могут быть с таким же успехом выполнены через HTTP REST API. Подробная документация по HTTP API здесь.
Artifact uploaders¶
Note
Graphite uploader and BlazeMeter Sense are not currently supported in the last Yandex.Tank version.
If you want one of them, use 1.7 branch.
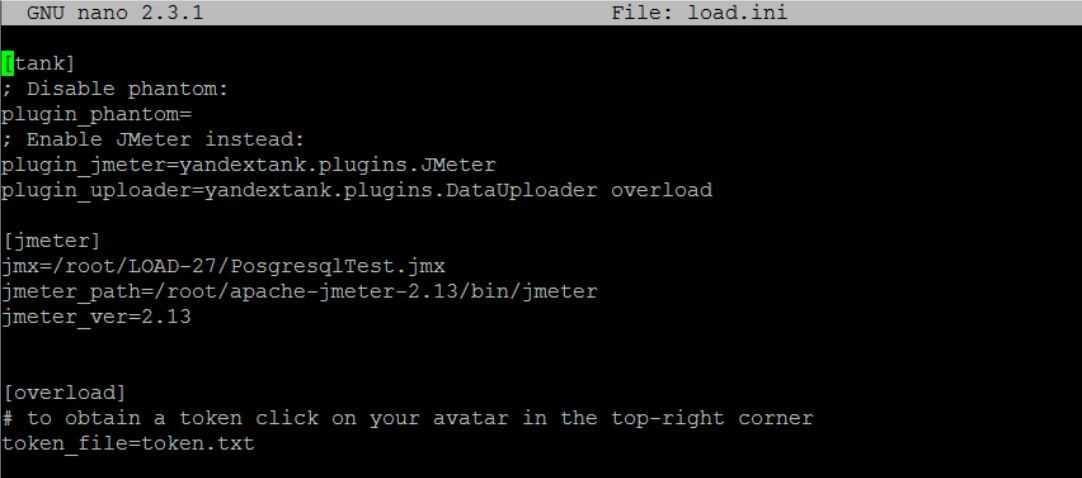
Yandex.Overload
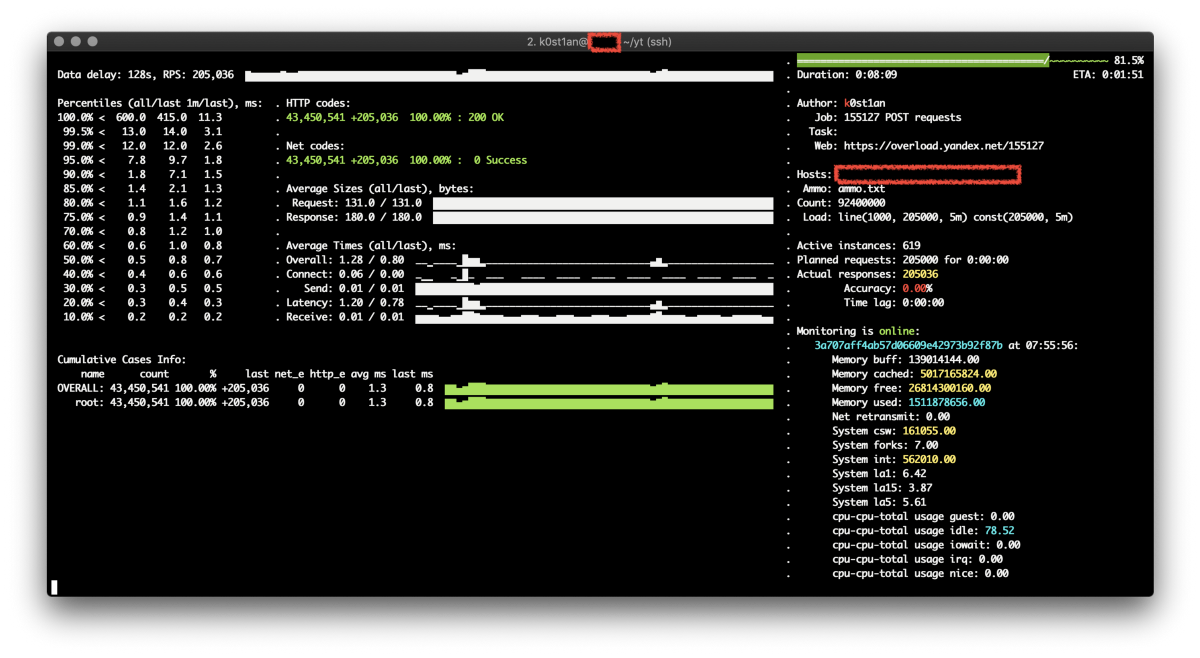
Overload 𝛃 is a service for performance analytics made by Yandex. We will store your performance experiments results and show them in graphic and tabular form. Your data will be available at https://overload.yandex.net.
![]()
yaml file section: overload
Options
| token_file: | Place your token obtained from Overload (click your profile photo) into a file and specify the path here |
|---|---|
| job_name: | (Optional) Name of a job to be displayed in Yandex.Overload |
| job_dsc: | (Optional) Description of a job to be displayed in Yandex.Overload |
Example:
overload token_file token.txt job_name test job_dsc test description
Logging
Note
Writing answers on high load leads to intensive disk i/o
usage and can affect test accuracy.**
Log format:
<metrics> <body_request> <body_answer>
Where metrics are:
(request size, answer size, response time, time to wait for response
from the server, answer network code)
Example:
user@tank:~$ head answ_*.txt 553 572 8056 8043 0 GET /create-issue HTTP/1.1 Host: target.yandex.net User-Agent: tank Accept: */* Connection: close HTTP/1.1 200 OK Content-Type: application/javascript;charset=utf-8
For like this:
phantom:
address: 203.0.113.1:80
load_profile:
load_type: rps
schedule: line(1, 10, 10m)
writelog: all
autostop:
autostop:
- time(1,10)
- http(5xx,100%,1s)
- net(xx,1,30)
Paramiko: SSHException: not a valid RSA private key file
On the first run Telegraf failed with the Paramiko error:
16:32:54 Failed to install monitoring agent to rtfm.co.uaTraceback (most recent call last):File “/usr/local/lib/python2.7/dist-packages/yandextank/plugins/Telegraf/client.py”, line 209, in install out, errors, err_code = self.ssh.execute(cmd)File “/usr/local/lib/python2.7/dist-packages/yandextank/common/util.py”, line 72, in executewith self.connect() as client:File “/usr/local/lib/python2.7/dist-packages/yandextank/common/util.py”, line 42, in connecttimeout=self.timeout, )File “/usr/local/lib/python2.7/dist-packages/paramiko/client.py”, line 437, in connectpassphrase,File “/usr/local/lib/python2.7/dist-packages/paramiko/client.py”, line 749, in _authraise saved_exceptionSSHException: not a valid RSA private key file
It’s because the RSA key on DigitalOcean is issued in the PEM/OpenSSH format:
$ file /home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11/home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11: OpenSSH private key
Convert it to the RSA:
$ ssh-keygen -p -m PEM -f /home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11
And check again:
$ file /home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11/home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11: PEM RSA private key
Run test again and Telegraf will print its configuration and metrics to be used:
$ docker run — rm -v $(pwd):/var/loadtest -v /home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11:/root/.ssh/id_rsa -it direvius/yandex-tank…16:36:38 Detected monitoring configuration: telegraf16:36:38 Preparing test…16:36:38 Telegraf Result config {‘username’: ‘root’, ‘comment’: ‘’, ‘telegraf’: ‘/usr/bin/telegraf’, ‘python’: ‘/usr/bin/env python2’, ‘host_config’: {‘Kernel’: {‘fielddrop’: ‘’, ‘name’: ‘’}, ‘Netstat’: {‘name’: ‘’}, ‘System’: {‘fielddrop’: ‘’, ‘name’: ‘’}, ‘Memory’: {‘fielddrop’: ‘’, ‘name’: ‘’}, ‘Net’: {‘interfaces’: ‘’, ‘fielddrop’: ‘’, ‘name’: ‘’}, ‘Disk’: {‘name’: ‘’, ‘devices’: ‘’}, ‘CPU’: {‘fielddrop’: ‘’, ‘name’: ‘’, ‘percpu’: ‘false’}}, ‘startup’: [], ‘host’: ‘rtfm.co.ua’, ‘telegrafraw’: [], ‘shutdown’: [], ‘port’: 22, ‘interval’: ‘1’, ‘custom’: [], ‘source’: []}16:36:38 Installing monitoring agent at root@rtfm.co.ua…16:36:38 Creating temp dir on rtfm.co.ua16:36:38 Execute on rtfm.co.ua: /usr/bin/env python2 -c “import tempfile; print tempfile.mkdtemp();”…
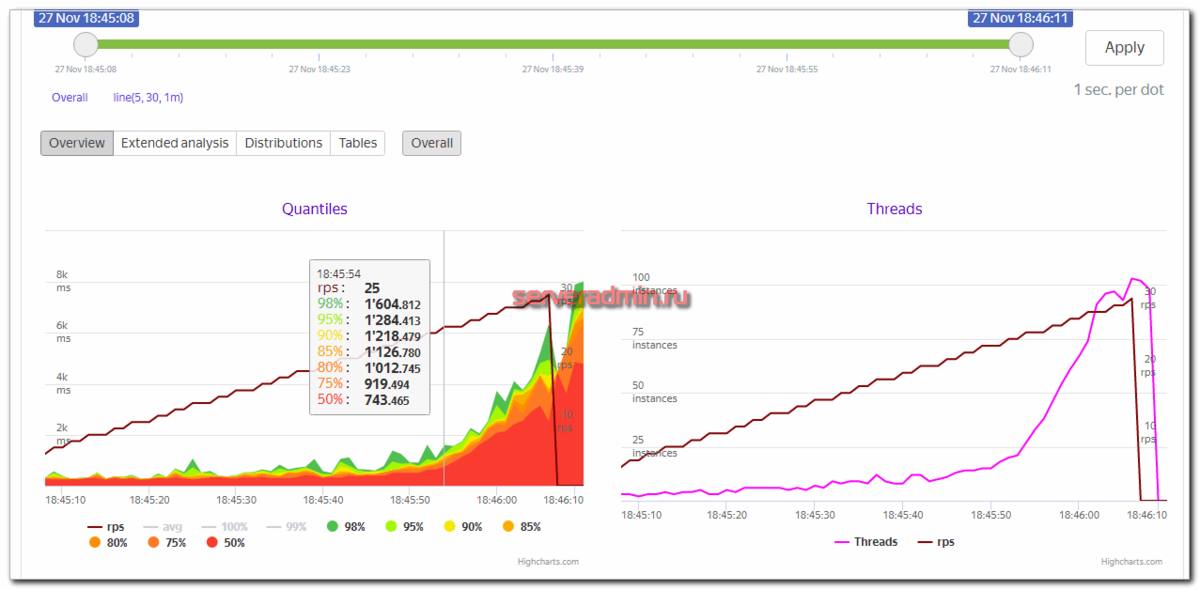
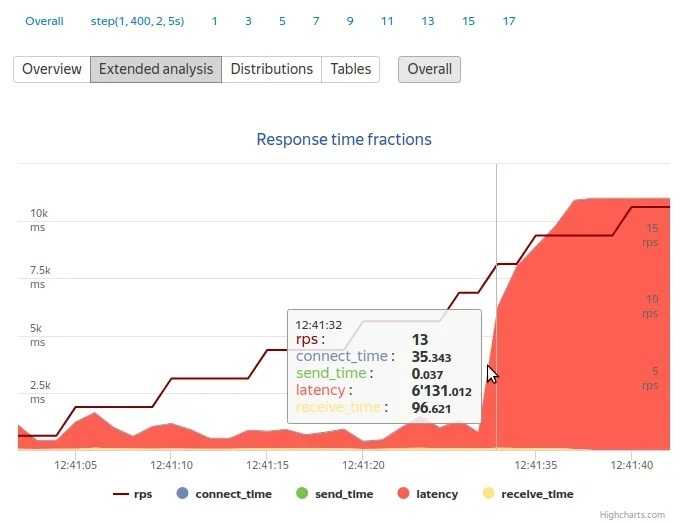
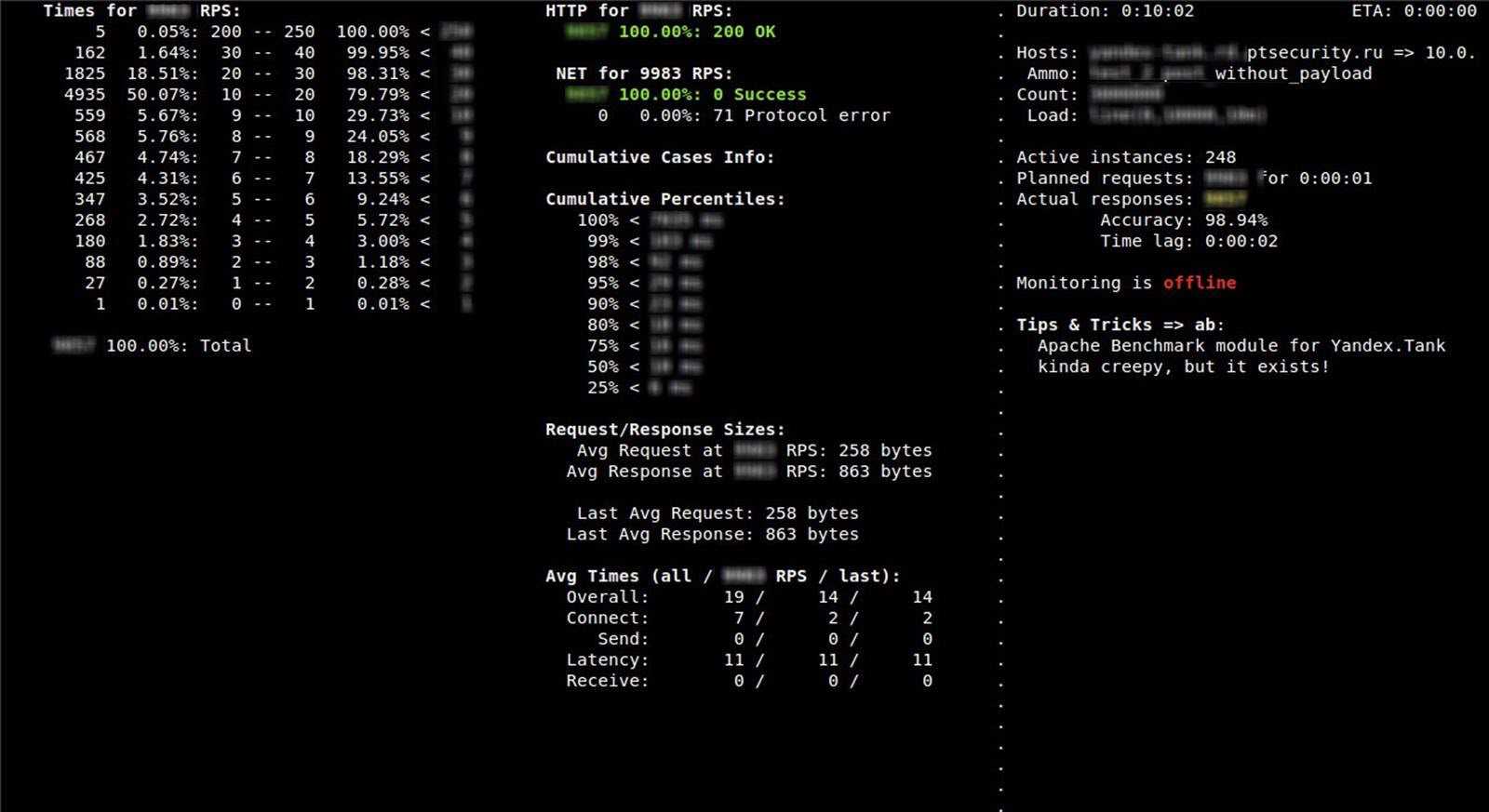
After this, the load test will be started and on the right side you’ll see the resources used on the target server:
![]()
And the agent running on the server:
$ root@rtfm-do-production-d10:~# ps aux | grep teleroot 4580 0.5 0.4 309992 9436 pts/1 Ssl+ 15:38 0:00 python2 /tmp/tmpZez6yJ/agent.py — telegraf /tmp/telegraf — host rtfm.co.uaroot 4582 7.1 1.5 851256 31896 ? Ssl 15:38 0:01 /tmp/telegraf -config /tmp/tmpZez6yJ/agent.cfg
Autostop
The Autostop module is used to terminate tests if something went wrong.
For example, you can configure it to stop the tests if 5[[ response rate will be higher than 10%, or if the response time will be greater than a specified value.
Add the following to check it:
...autostop: autostop: - http(2xx,100%,1s)
Here for example tests will be stopped once will get the 2xx response over 1 second.
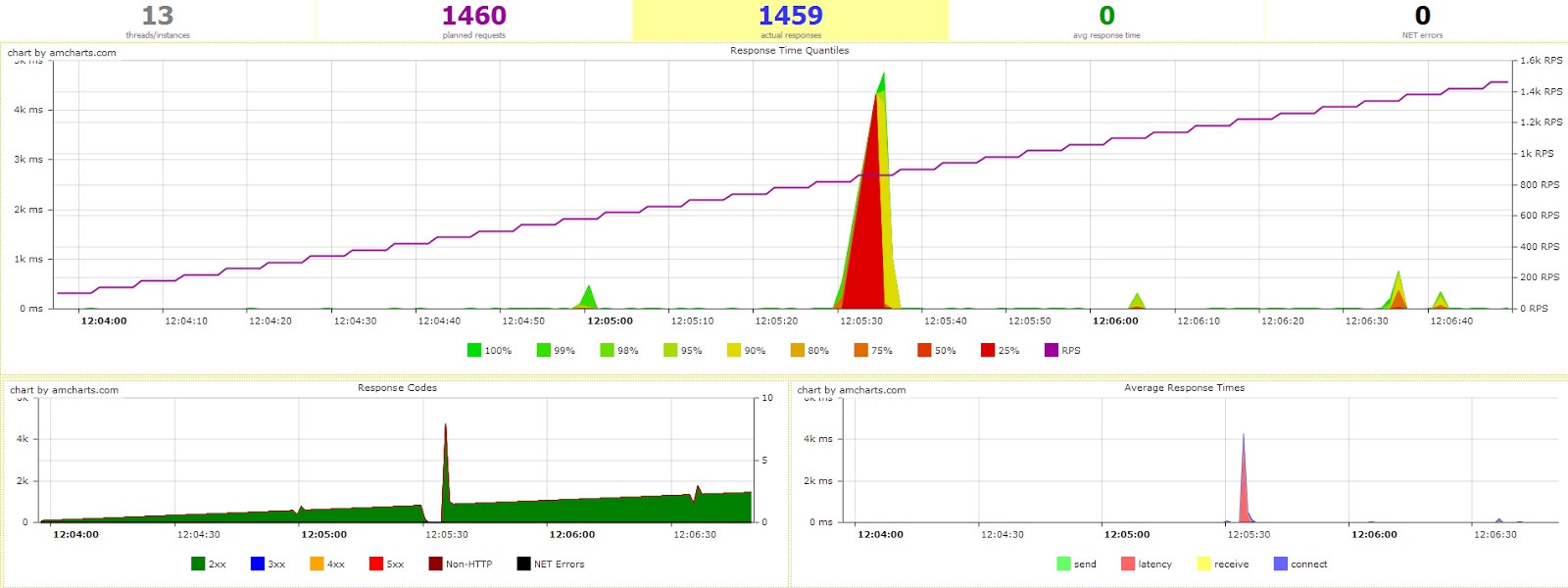
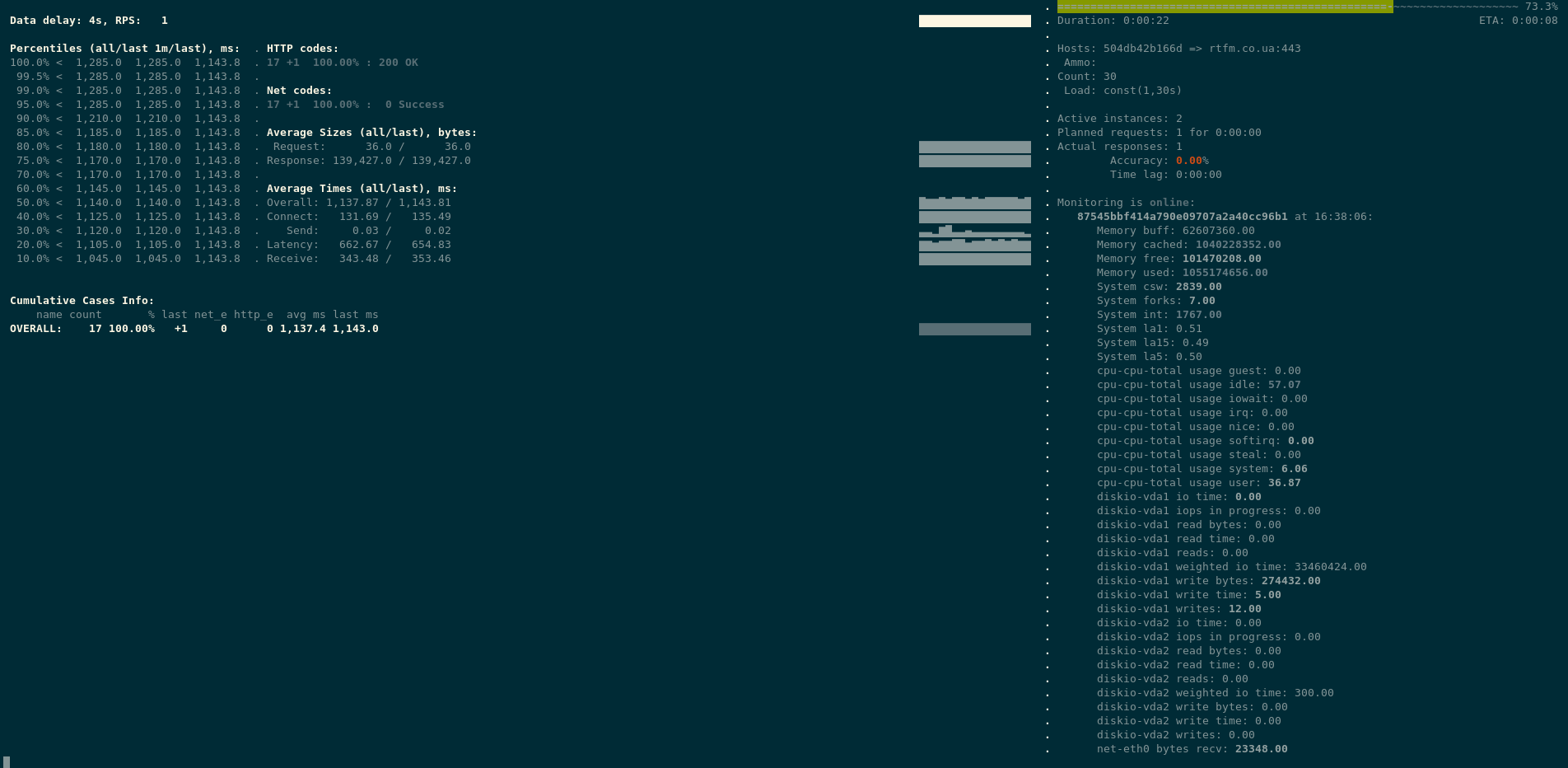
Run the tests, and:
$ docker run — rm -v $(pwd):/var/loadtest -v /home/setevoy/.ssh/setevoy-do-nextcloud-production-d10–03–11:/root/.ssh/id_rsa -it direvius/yandex-tank…16:56:24 Monitoring received first data.16:56:24 Autostop criterion requested test stop: http(2xx,100%,1s)16:56:24 Autostop criterion requested test stop: 2xx codes count higher than 100.0% for 1s, since 161288978016:56:24 Finishing test…16:56:24 Stopping load generator and aggregator…
It was immediately stopped.
See more option in the .
The whole now is:
phantom: address: rtfm.co.ua:443 header_http: "1.1" headers: - "" uris: - / load_profile: load_type: rps schedule: const(1,30s) ssl: trueconsole: enabled: truetelegraf: enabled: true package: yandextank.plugins.Telegraf config: monitoring.xmlautostop: autostop: - http(2xx,100%,1s)
Useful links
All in Russian, unfortunately.
- Автоматизация нагрузочного тестирования при помощи инструмента Яндекс.Танк
- Нагрузочное тестирование c Yandex.Tank и JMeter
- Нагрузочное тестирование http-сервера (nginx), 205k+ RPS
- Тестирование в Яндексе: строим свой Лунапарк
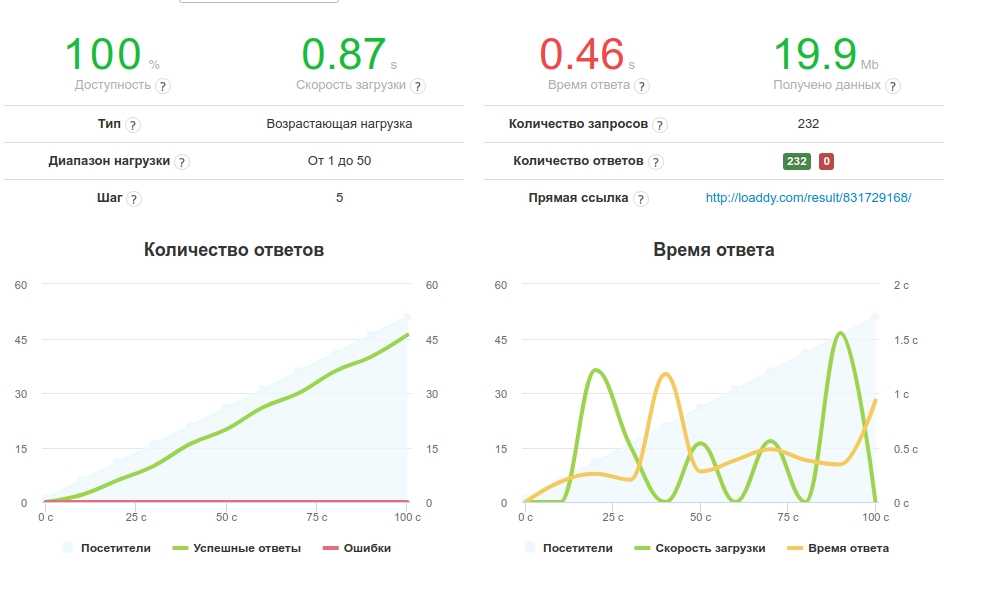
- Пример нагрузочного тестирования сайта с Yandex.Tank
Autostop
Autostop is an ability to automatically halt test execution
if some conditions are reached.
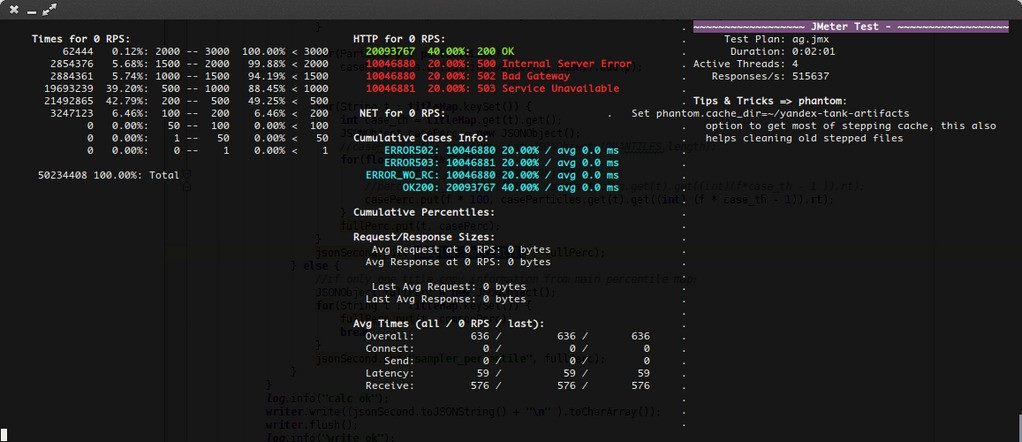
HTTP and Net codes conditions
There is an option to define specific codes (404,503,100) as well as code
groups (3xx, 5xx, xx). Also you can define relative threshold (percent
from the whole amount of answer per second) or absolute (amount of
answers with specified code per second).

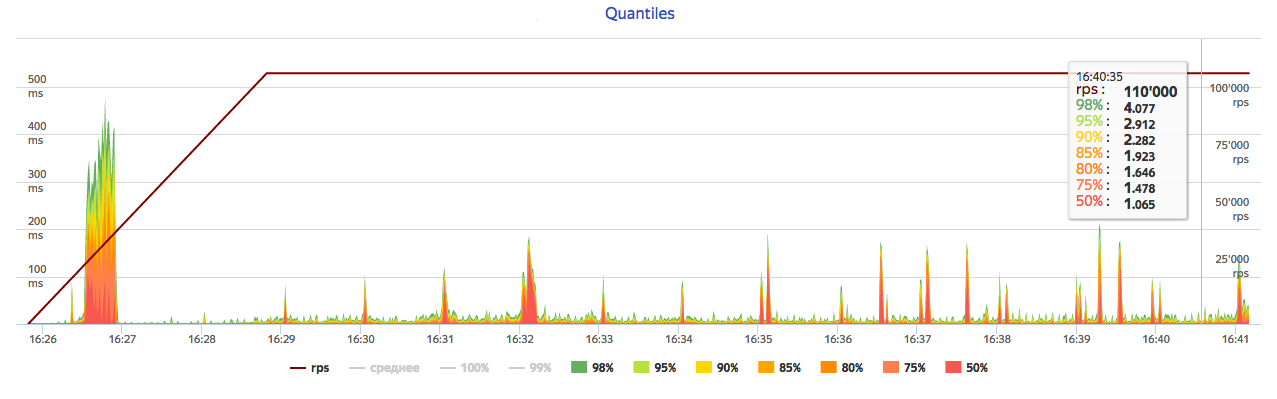
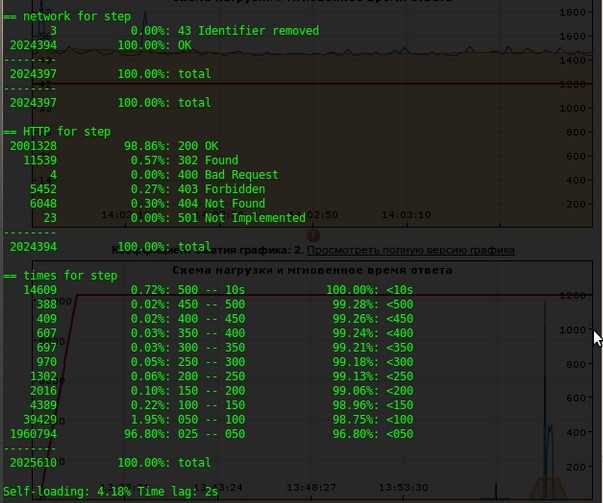
Examples:
Average time conditions
- Example:
- – stops test, if average answer time exceeds 1500ms.
So, if we want to stop test when all answers in 1 second period are 5xx plus some network and timing factors — add autostop line to load.yaml:
phantom:
address: 203.0.113.1:80
load_profile:
load_type: rps
schedule: line(1, 10, 10m)
autostop:
autostop:
- time(1s,10s)
- http(5xx,100%,1s)
- net(xx,1,30)
JMeter
Он более сложен в настройке, чем дефолтный генератор – phantom, но в тоже время более гибок. Мы будем использовать его для нетривиальных сценариев запросов – например, для эмуляции пользовательских сессий, когда запросы от одного пользователя должны выполнятся последовательно.
Установка
В контейнере должна быть установлена Java. Можно подготовить собственный образ либо установить пакет вручную.
apt-get update apt-get install openjdk-8-jre
Теперь нужно скачать архив с бинарниками и распаковать его.
wget http://www-us.apache.org/dist/jmeter/binaries/apache-jmeter-3.3.tgz tar xzvf apache-jmeter-3.3.tgz
Также может потребоваться установить дополнительные плагины. Для этого откройте JMeter локально, через графический интерфейс установите плагин plugin-manager и откройте тестовый сценарий. Вам будет предложено установить недостающие плагины. После установки папку можно будет перенести в контейнер.
Конфигурация
Конфигурация JMeter разнесена между тестовым сценарием и конфигом танка .
Секция JMeter может выглядеть так.
jmeter:
enabled: true
package: yandextank.plugins.JMeter
jmx: ammo.jmx
jmeter_path: /var/loadtest/apache-jmeter-3.3/bin/jmeter
buffered_seconds:
ext_log: none
variables:
protocol: http
host: 127.0.0.1
port: 8080
path: /path/to/endpoint
thread_rpm: 300
loops: 20
texts: scenarios.csv
– пользовательские переменные (аналог переменных окружения), которые будут проброшены в тестовый сценарий.
Описание принципов создания тестового сценария выходит за рамки данной статьи.
Установка и настройка InfluxDB
Если у нас уже есть сервер баз данных, совместимый с telegraf, можно пропустить данный раздел. В противном случае, рассмотрим процесс подготовки сервера и установки InfluxDB. В данной инструкции мы будем разворачивать сервер баз данных на Linux, но при необходимости, InfluxDB может быть установлен на Windows.
Подготовка сервера
1. Время
Для любой базы хранения временных рядов важно своевременно обновлять время на сервере. Задаем временную зону:
Задаем временную зону:
\cp /usr/share/zoneinfo/Europe/Moscow /etc/localtime
* в данном примере задаем московское время. В каталоге /usr/share/zoneinfo список всех возможных вариантов.
Устанавливаем и запускаем сервис для автоматической синхронизации времени.
а) в CentOS / Red Hat / Fedora:
yum install chrony
systemctl enable chronyd —now
б) в Ubuntu / Debian:
apt-get install chrony
systemctl enable chrony
2. Брандмауэр
Если мы используем фаервол, то необходимо открыть порт 8086, на котором по умолчанию запускается данный сервер баз данных. В зависимости от используемой утилиты управления, команды будут отличаться.
а) Firewalld
По умолчанию, используется в системах на базе RPM. Для открытия нужного нам порта вводим команды:
firewall-cmd —permanent —add-port=8086/tcp
firewall-cmd —reload
б) Iptables
Чаще всего, используется в системах на базе DEB или в ранних версиях RPM. Вводим команду:
iptables -I INPUT 1 -p tcp —dport 8086 -j ACCEPT
… и сохраняем правила:
netfilter-persistent save
* если система вернет ошибку, что программа не установлена, выполним инсталляцию командой apt-get install netfilter-persistent.
3. SELinux
По умолчанию, пакет безопасности SELinux установлен на системах RPM. Чаще всего, его выключают командами:
setenforce 0
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
* но если мы хотим настроить SELinux, принцип конфигурирования можно прочитать в инструкции Настройка SELinux в CentOS.
Установка InfluxDB
Мы выполним установку базы данных на примере двух различных систем — CentOS и Ubuntu.
а) Установка InfluxDB на CentOS
Создаем файл с настройками репозитория:
vi /etc/yum.repos.d/influxdb.repo
name = InfluxDB Repository — RHEL $releasever
baseurl = https://repos.influxdata.com/rhel/$releasever/$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
Можно устанавливать InfluxDB:
yum install influxdb
Разрешаем автоматический запуск сервиса и стартуем его:
systemctl enable influxdb —now
б) Установка InfluxDB на Ubuntu
Устанавливаем ключ для репозитория:
wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add —
Вводим команду для создания переменных в системном окружении, в которых будут храниться данные о версии дистрибутива:
source /etc/lsb-release
Следующей командой мы создадим файл с настройкой репозитория:
echo «deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable» | sudo tee /etc/apt/sources.list.d/influxdb.list
Обновляем список пакетов:
apt-get update
Теперь установим InfluxDB:
apt-get install influxdb
Разрешаем автоматический запуск сервиса и стартуем его:
systemctl enable influxdb
systemctl start influxdb
Core¶
(dict)
— (no description).
| (string): | |
|---|---|
| — specify cpu core(s) to bind tank process to, http://linuxhowtos.org/manpages/1/taskset.htm. Default: | |
| (string): | |
| — tankapi job id, also used as test’s directory name — determined by tank. | |
| (string): | |
| — base directory to store tests’ artifacts directories. Default: | |
| (string): | |
| — directory inside base directory to store test’s artifacts, defaults to api_jobno if null. | |
| (string): | |
| — (no description). | |
| (boolean): | |
| — (no description). Default: | |
| (integer): | |
| — (no description). | |
| (string): | |
| — path to store config. | |
| (boolean): | |
| — if tank is locked ( *.lock file(s) presented in lock_dir), shoot nevertheless. Default: | |
| (string): | |
| — directory to store *.lock files. Default: | |
| (string): | |
| — (no description). | |
| (string): | |
| — your username. | |
| (integer): | — (no description). |
| (string): | |
| — (no description). Default: | |
| (string): | — (no description). |
| allow_unknown: | False |
Ansible-playbook для быстрого деплоя
Ansible — популярный инструмент для управления конфигурациями. В случае, когда надо выполнить описанные выше действия на большом количестве виртуалок, часть из которых периодически умирают и появляются новые, ansible может очень сильно облегчить жизнь.




Ниже привожу код playbook-а, выполняющего описанные в статье действия. Сразу оговорюсь — playbook приведен для примера и не является образцом аккуратности и правильности с т.з. лучших практик ansible. На практик, конечно, лучше выделить отдельные роли и вызывать их и т.д.
На первом шаге плейбука мы добавляем нужные репозитории и устанавливаем telegraf, influxdb, grafana. Далее на втором шаге конфигурируем telegraf, используя шаблон jinja2, затем запускаем все сервисы и создаем источник данных/импортируем дашборд в grafana, используя REST API.
На этом, наверное, можно закончить. Дочитавшим — котика ![]()
![]()
Logging¶
Looking into target’s answers is quite useful in debugging. For doing
that use parameter , e.g. add to to log all messages.
Note
Writing answers on high load leads to intensive disk i/o
usage and can affect test accuracy.**
Log format:
<metrics> <body_request> <body_answer>
Where metrics are:
(request size, answer size, response time, time to wait for response
from the server, answer network code)
Example:
user@tank:~$ head answ_*.txt 553 572 8056 8043 0 GET /create-issue HTTP/1.1 Host: target.yandex.net User-Agent: tank Accept: */* Connection: close HTTP/1.1 200 OK Content-Type: application/javascript;charset=utf-8
For like this:
Заключение
С помощью Yandex.Tank вы без проблем можете положить неподготовленный сайт. Главное найти в нем самые медленные и нагруженные места (например поиск или большой каталог) А потом одновременно запустите тест из разных мест. А если еще и хорошенько автоматизируете это с помощью terraform и ansible, то совсем хорошо получится. Или плохо для владельца сайта. Правда это дороговато может стоить, есть способы подешевле. Но сейчас не будем об этом.
От такого рода «тестирования» достаточно просто защититься и стоит это делать всегда. Примеры защиты я подробно описывал в своих статьях — защита от ddos, защита от dos атак. В общем случае достаточно будет стандартных возможностей nginx, iptables и fail2ban. Удивительно, но очень много кто этого не делает. Я ради любопытства иногда клал очень неожиданные сайты. Но только в академических целях и на очень короткий период времени. Помним о карме и не вредим другим людям! Используем инструменты только во благо.
Онлайн курс по Linux
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «Administrator Linux. Professional» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и установке Linux на виртуалку. Обучение длится 5 месяцев, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
Что даст вам этот курс:
- Знание архитектуры Linux.
- Освоение современных методов и инструментов анализа и обработки данных.
- Умение подбирать конфигурацию под необходимые задачи, управлять процессами и обеспечивать безопасность системы.
- Владение основными рабочими инструментами системного администратора.
- Понимание особенностей развертывания, настройки и обслуживания сетей, построенных на базе Linux.
- Способность быстро решать возникающие проблемы и обеспечивать стабильную и бесперебойную работу системы.
Проверьте себя на вступительном тесте и смотрите подробнее программу по .
Выводы
Инструмент Яндекс.Танк может помочь всюду, где требуется быстро провести нагрузочное тестирование веб-приложений без их сложной подготовки и при этом получить множество полезных статистических данных для анализа производительности.
Также данный инструмент хорошо внедряется в имеющиеся системы автоматизации. Например, для упрощения работы со стендом Яндекс.Танка: его управлением, запуском, подготовки патронов для лент, контролем за процессом тестирования и сбором результатов, мной, без особых усилий, был написан класс-обвязка на Python, который подключается к стенду по ssh и выполняет все перечисленные действия. Затем он был встроен в нашу существующую систему авто-тестирования.
Дополнительно вы можете посмотреть, как подключить и использовать высокопроизводительную систему Graphit для анализа большого числа графиков, о которой рассказывалось в одной из презентаций на конференции YAC-2013. Её также можно приспособить для нужд нагрузочного тестирования с использованием Яндекс.Танка.





