Во-первых, введение
Инструмент NMON может помочь отобразить все важные данные оптимизации производительности на экране и динамически обновлять его. Этот эффективный инструмент может работать в любом тупом экране, сеансе Telnet и даже наберите линии. Кроме того, он не потребляет большое количество циклов ЦП, обычно менее 20%. На обновленном компьютере его использование ЦП будет менее одного процента. Используйте тупой экран для отображения данных на экране и обновите его каждые две секунды. Однако вы можете легко изменить этот интервал времени до более длительного или более короткого периода времени. Если вы протягиваете окно и отображаете эти данные в X Windows, VNC, PUTTY или аналогичном окне, инструмент NMON может одновременно выводить много информации. Инструмент NMON также отражает те же данные в текстовом файле, который легко проанализировать и рисовать графику в отчете, а выходной файл используется в формате электронной таблицы.
Инструменты NMON могут предоставлять мониторинг и анализ данных о производительности для экспертов по производительности AIX и Linux, в том числе:
- использование процессора
- Использование памяти
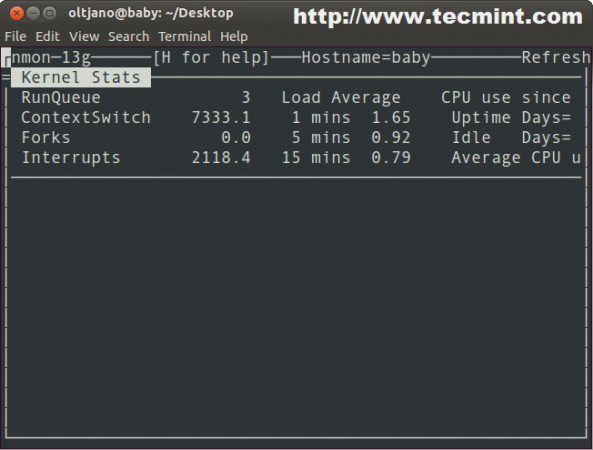
- Основная статистика и информация о работе очереди
- Дисковая система ввода / вывода, передача и соотношение чтения / записи
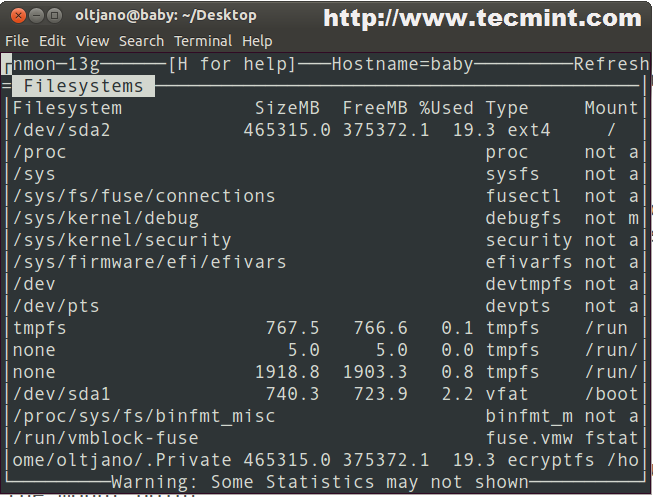
- Доступное пространство в файловой системе
- Дисковой адаптер
- Сеть ввода-вывода скорость, передача и соотношение чтения / записи
- Пространство страницы и скорость страницы
- Спецификация CPU и AIX
- Заданный процесс
- IBM HTTP Web Cache
- Пользовательская дисковая группа
- Компьютерные детали и ресурсы
- Асинхронный ввод / вывод, доступный только для AIX
- Диспетчер рабочей нагрузки (WLM), доступный только для AIX
- IBM TotalStorage? Enterprise Storage Server? (ESS) Диск, доступный только для AIX
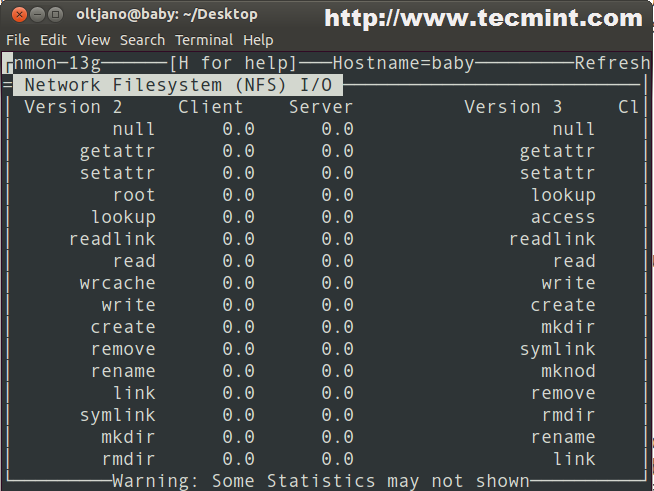
- Сетевая файловая система (NFS)
- Изменения Dynamic LPAR (DLPAPAR) применяются только к AIX или Linux PSeries P5 и OpenPower также включают новый инструмент для генерации графики от NMON для генерации графики и создать новый инструмент, который можно отобразить на веб-сайте.
Если вас окружили демоны — логируйте их немедленно!
Один из самых простых и банальных способов проверить, что происходит в системе, — это посмотреть системные логи. Вот тут можно почитать о том, какие секреты скрываются в каталоге
/var/log и откуда они там берутся. До недавнего времени основным механизмом записи логов был syslog, точнее, его относительно современная реализация rsyslog. Она до сих пор активно используется.
А что в авангарде? В современных дистрибутивах Linux на основе systemd используется свой механизм логирования, которым можно управлять через утилиту journalctl. Там есть крайне удобная фильтрация по разным параметрам и прочие плюшки.
Сам же systemd до сих пор остается довольно жарким топиком для обсуждения, поскольку «подминает» под себя многие устоявшиеся инструменты и предоставляет альтернативы к существующим решениям. Например, как запускать какой-то процесс регулярно? Crontab? Вовсе не обязательно, теперь у нас есть systemd timers. А как насчет настройки реакций на системные и «железные» события? В systemd есть поддержка watchdog. А что там со сменой корня — старый добрый chroot? Необязательно, теперь есть новенький systemd-nspawn.
Файлы, которых нет
Если говорить совсем откровенно, в Linux основным источником информации как о процессах, так и о железе служит именно файловая виртуальная файловая система
procfs(/proc), а также
sysfs(/sys). И у них довольно богатая и интересная история.
Дело в том, что одно из официальных положений идеологии UNIX гласит: «Всё есть файл», то есть взаимодействие с любым системным компонентом теоретически должно вестись через реальный или виртуальный файл, доступный через обычное дерево каталогов. Эту идею до абсолюта довели в наследнике UNIX под названием Plan 9, где все процессы превратились в каталоги и взаимодействовать с ними можно было даже посредством команд
cat и
ls, поскольку они были текстовыми. Именно так появилась файловая система procfs, которая позже перекочевала в Linux и BSD.
Но, как и в случае с load average, конкретно в Linux есть свои тонкости (это я так политкорректно называю адскую кашу-малашу). Например, линуксовый
/proc, вопреки названию, с самого начала был универсальным интерфейсом получения информации от ядра в целом, а не только от процессов. Более того, именно взаимодействовать с процессами через эту систему практически не получается, только извлекать информацию по их PID’ам.
С течением времени в
/proc появлялось все больше и больше файлов, содержащих информацию о самых разных подсистемах ядра, железе и многом другом. В конечном итоге он превратился в помойку, и разработчики решили вынести информацию хотя бы о железе в отдельную файловую систему, которую к тому же можно было бы использовать для формирования каталога
/dev. Так и появилась
/sys со своей странной структурой каталогов — ее трудно разгребать вручную, но она очень удобна для автоматического анализа другими приложениями (такими как udev, который и формирует содержимое каталога
/dev на основе информации из
/sys).
В итоге куча информации до сих пор дублируется в
/proc и
/sys просто потому, что, если выкинуть файлы из
/proc, можно сломать некоторые фундаментальные системные компоненты (легаси!), которые до сих пор не переписаны.
Ну а еще есть
/run, конечно же. Это файловая система, которая монтируется одной из первых и служит перевалочным пунктом для данных рантайма основных системных демонов, в частности udev и systemd (о нем поговорим отдельно чуть позже). Кстати, сам проект udev в 2012 году влился в systemd и дальше развивается как его часть.
В общем, как писал Льюис Кэрролл, «все чудесатее и чудесатее».
Но вернемся к нашим замерам. Для того чтобы смотреть, какие PID присвоены процессам, есть команды
pidstat и
htop (из одноименного пакета, более продвинутая версия top, заодно показывает чертову прорву всего, аналог графического диспетчера задач).
Кроме того, команда time позволяет запустить процесс, попутно измерив время его выполнения, точнее, целых три времени:
|
1 |
$time python3-c»import time; time.sleep(1)» python3-c»import time; time.sleep(1)»0.04suser0.01ssystem4%cpu1.053total |
Как выше я уже проговорился, любая программа может проводить разное время в kernel space и user space, то есть выполняя вызовы в ядро или свой собственный код. Поэтому при базовом взгляде на эти цифры можно в некоторых случаях уже сделать вывод об узком месте в программе: если первый показатель сильно выше, то, вполне возможно, затык в I/O, а если второй — то, возможно, в коде есть неэффективно написанные куски, которые стоит запрофилировать подробнее.
А вот третье время, total time, оно же wall clock time или real time, — это время, которое реально заняло выполнение программы с момента запуска до момента возврата управления. Кстати, user time может быть сильно больше real time, потому что оно рассчитывается как сумма по всем ядрам CPU. Если такое происходит — значит, программа неплохо параллелится.
Ну и напоследок, чтобы посмотреть загрузку для каждого ядра в отдельности, можно использовать вот такую команду:
| 1 | $mpstat-PALL1 |
Если будут сильные перекосы в загрузке ядер — значит, какая-то из программ, напротив, параллелится крайне плохо. А единичка значит «обновляй-ка раз в секунду».
Работа с утилитой TuxClocker для видеокарт amd/nvidia в Ubuntu
Для работы с видеокартами nvidia в ubuntu утилите Tuxclocker требуется наличие установленных пакетов nvidia-smi, nvidia-settings, libxnvctrl и headers qt5base, x11extras. Для видеокарт amd требуется наличие библиотек libdrm и headers. Обычно все эти пакеты уже стоят в системе с запущенным майнингом.
Для компиляции и установки утилиты Tuxclocker для мониторинга состояния видеокарт nvidia, в терминале по очереди выполняют команды:
git clone https://github.com/Lurkki14/tuxclocker cd tuxclocker qmake rojekti.pro (возможно, нужно будет установить пакет qtchooser командой sudo apt install qtchooser) make sudo make install
Программа Tuxclocker установится в папку /opt/tuxclocker/bin.
При появлении ошибок вида:
qmake: could not find a Qt installation of '',
а также:
Project ERROR: Unknown module(s) in QT: x11extras
нужно установить пакеты qt5 и libqt5x11extras5-dev командой:
sudo apt-get install qt5-default libqt5x11extras5-dev
Для видеокарт AMD в терминале последовательно выполняют команды:
git clone https://github.com/Lurkki14/tuxclocker cd tuxclocker git checkout pstatetest qmake rojekti.pro make sudo make install (программа установится в папку /opt/tuxclocker/bin)
Для полноценного использования, утилиту tuxclocker нужно запускать от имени root командой:
sudo /opt/tuxclocker/bin/tuxclocker
Окна работающей утилиты tuxclocker:
![]()
Для полноценной работы с видеокартами АМД нужно включить в драйвере утилиту Radeon OverDrive. Это делается путем добавления в загрузчик ядра (не ниже версии 4.17) опции amdgpu.ppfeaturemask=0xffffffff (или amdgpu.ppfeaturemask=0xfffd7fff).
Для этого корректируют файл /etc/default/grub, а именно:
строку GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
нужно привести к виду:
GRUB_CMDLINE_LINUX_DEFAULT="quiet amdgpu.vm_fragment_size=9 radeon.si_support=0 amdgpu.si_support=1 amdgpu.dpm=1 amdgpu.ppfeaturemask=0xffffffff"
Для корректировки /etc/default/grub используют:
sudo nano /etc/default/grub
изменяют содержимое файла /etc/default/grub и обновляют grub командой:
sudo update-grub
Для справки:
В данном случае при корректировке опций загрузки ubuntu используются следующие параметры работы ядра (kernel), отвечающие за видеорежим:
- amdgpu.vm_fragment_size=9 — включение поддержки больших страниц памяти (аналог compute mode);
- nomodeset — настройка видеокарт происходит в ядре ,а не драйверах. Драйвера видеокарт не запускаются до полного запуска системы. Для майнинга этот режим применять нет смысла;
- quiet — при загрузке не отображаются сообщения об активации драйверов и прочей служебной информации. Для более полного контроля над компьютером и изучения процесса загрузки можно вообще отключать эту опцию;
- splash — режим, при котором запускается экран загрузки «глаз» и основные компоненты системы загружаются в фоновом режиме.
- quiet splash — тихое отображение заставки.
Параметры radeon.si_support=0 amdgpu.si_support=1 включают поддержку драйвера amdgpu для видеокарт amd вместо устаревшего драйвера radeon.
Параметр amdgpu.dpm=1 добавляет поддержку режима DPM (dynamic power management) для видеокарт AMD.
Параметр amdgpu.ppfeaturemask=0xffffffff» используется для видеокарт AMD Polaris и Vega для включения OverDrive и разблокирования возможности полноценной работы с вольтажом, частотой ядра и памяти таких видеокарт. Для Gpu Navi (RX5700) можно попробовать использовать параметр amdgpu.ppfeaturemask=0xfffd7fff.
Для проверки корректности параметров загрузки применяют команду:
printf "0x%08x\n" $(cat /sys/module/amdgpu/parameters/ppfeaturemask)
Должно отображаться значение 0xffffffff.
Рассмотрим подробнее работу с утилитой WattmanGTK, которая лучше всего работает с видеокартами AMD.
Бонус: дополнительные инструменты
Еще немного инструментов:
- nmap – сканирует сервер на наличие открытых портов.
- lsof – список открытых файлов, сетевых подключений и многое другое.
- ntop — веб-инструмент для наблюдения за использованием сети, программное обеспечение для мониторинга сетевого трафика. Вы можете видеть состояние сети, распределение трафика по протоколам для UDP, TCP, DNS, HTTP и других протоколов.
- Conky – еще один классный инструмент мониторинга для системы X Window. Он легко настраивается и способен отслеживать многие системные переменные, включая состояние процессора, памяти, места подкачки, дискового пространства, температуры, процессов, сетевых интерфейсов, заряда батареи, системных сообщений, почтовых ящиков и т. д.
- GKrellM – этот инструмент можно использовать для мониторинга состояния процессоров, основной памяти, жестких дисков, сетевых интерфейсов, локальных и удаленных почтовых ящиков и многого другого.
- mtr – mtr объединяет функциональность программ traceroute и ping в одном инструменте диагностики сети.
- vtop – графический монитор активности терминала в Linux.
- gtop – панель мониторинга системы для терминала Linux/macOS Unix.
Оригинал статьи — https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html.
Каждую неделю мы в live режиме решаем кейсы на наших открытых онлайн-практикумах, присоединяйтесь к нашему каналу в Телеграм, вся информация там.
13Веб-стресс-тест-Httperf
Httperf более мощный, чем ab, и может тестировать максимальное количество сервисов, которые может нести веб-сервис, и находить потенциальные проблемы, такие как использование памяти и стабильность. Самое большое преимущество: вы можете указать правила для стресс-тестирования и смоделировать реальную среду.
Скачать: http://code.google.com/p/httperf/downloads/list
Описание параметра:
—hog: разрешить httperf генерировать как можно больше соединений, httperf будет регулярно генерировать соединения для доступа в соответствии с конфигурацией оборудования.
—num-conns: количество подключений, всего было инициировано 10000 запросов
—wsess: моделирование времени, когда пользователь открывает веб-страницу, первые 10 означают 10 сеансовых соединений, вторые 10 означают 10 запросов на одно сеансовое соединение, 0,1 означает интервал времени между каждым запросом на сеансное соединение / с
Эта статья из блога «Нет простого способа узнать, нет быстрого пути к обучению!»
Лидируют бесплатные курсы по облачным вычислениям, а 5-дневный курс по эксплуатации и техническому обслуживанию можно прослушать бесплатно.Щелкните в конце статьи»Прочтите оригинал»Бесплатные уроки!Конечно, есть и другие бесплатные ИТ-курсы (Java, интерфейс, большие данные, Python, дизайн, C ++, встраиваемые, онлайн-маркетинг),Фоновый ответ«Имя + контактная информация + место + название курса»Вы также можете подать заявку на другие бесплатные курсы, чтобы продвинуться вперед~~~~
PS: Не забудьте проверить бесплатную подарочную упаковку, отправленную вам редактором ~
▼ Нажмите 【Прочтите оригинал】,свободныйПослушайте 5-дневный курс обмена сухими товарами Linux по эксплуатации и обслуживанию,Разговор идет полным ходом, приходите и хватайте!
Сборка из агента, базы данных и веб-интерфейса
Если вас не устраивает ни одна из существующих систем мониторинга, вы можете собрать свою на основе отдельных компонентов. Использовать агент для сбора данных из одной системы, базу данных для хранения собранного, а также удобный веб интерфейс.
В качестве агента сбора данных можно использовать один из перечисленных выше от систем мониторинга или же отдельный, например, Collectd, Telegraf или другие. В качестве базы данных часто используют InfluxDB, написанную на Go, а в качестве веб-интерфейса очень популярна Grafana. Это очень простой и красивый инструмент для рисования графиков на основе меняющихся со временем данных.
1. Zabbix
![]()
Это одна из самых популярных промышленных систем мониторинга для Linux. Zabbix поддерживает сбор информации с нескольких серверов, мониторинг таких часто используемых служб, как Apache, Nginx, PHP-FPM, MySQL, PostgreSQL, Tomcat и многих других, а также обнаруживает и сообщает об различных типичных ошибках. Есть возможность отправки уведомления на электронную почту при возникновении определённого события. Это позволяет реагировать очень быстро на любые ошибки. Все настройки выполняются с помощью удобного веб-интерфейса и хранятся в базе данных MySQL. Вы также можете посмотреть текущие значения различных метрик сервера в разделе Monitoring -> Last data. Доступны графики для основных отслеживаемых параметров.
Работа с программой GreenWithEnvy для видеокарт nvidia
Работа с программой GreenWithEnvy проста и интуитивно понятна. Для ее установки инсталлируют библиотеки:
sudo apt install git meson python3-pip python3-setuptools libcairo2-dev libgirepository1.0-dev libglib2.0-dev libdazzle-1.0-dev gir1.2-gtksource-3.0 gir1.2-appindicator3-0.1 python3-gi-cairo appstream-util
а потом выполняют команды:
flatpak --user remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo flatpak --user install flathub com.leinardi.gwe flatpak update
Запуск GreenWithEnvy производится командой:
flatpak run com.leinardi.gwe
или просто:
gwe
Скриншот утилиты GreenWithEnvy:
Пакеты брать будете?
Что еще из операций ввода-вывода у нас осталось? Правильно, сетевое взаимодействие. Здесь царит та еще чехарда — «официальные» утилиты меняются от релиза к релизу, что, с одной стороны, круто, потому что удобств становится больше, с другой — надо переучиваться каждый раз.
Скажем, какой утилитой смотреть существующие в системе интерфейсы? Кто сказал
ifconfig? На современных системах ifconfig, как правило, уже вообще отсутствует, ибо есть
| 1 | $ipa |
Вроде выглядит немного по-другому, а вроде то же самое. Кстати, для управления сетевыми мостами из консоли часто необходимо ставить пакет bridge-utils. Тогда в консольке появится утилита
brctl, с помощью которой можно будет их просматривать (
brctl show), ну и менять. Но иногда бывает по-другому. Мне встречался случай, когда бриджи были, а brctl их не показывал. Оказалось, что для их создания использовался Open vSwitch и кастомный модуль ядра, для настройки которого надо использовать другую утилиту —
ovs-vsctl. Если вдруг у тебя окружение на OpenStack, где эта штука активно используется, — может быть полезно.
Дальше — как насчет таблиц маршрутизации? Как, говоришь,
route-n? Нет, мимо. Сейчас чаще используются
netstat-nr и
ip route show. Ну и самое банальное — как посмотреть открытые порты и процессы, которые их запросили? Например, вот так:
| 1 | $sudo netstat-tnlp |
Но думаю, ты уже понял, что банальщиной мы ограничиваться не будем. Давай посмотрим теперь в реальном времени, как пакеты бегают по интерфейсам.
| 1 | $sar-nDEV1 |
Да, sar — это еще одна отличная утилита для мониторинга. Умеет показывать не только сетевые операции, но и диски и активность процессора. Почитать о ней можешь, например, в статье «Простой мониторинг системы с помощью SAR».
Также sar позволяет мониторить открытие/закрытие соединений и ретрансмиты (это повторные отправки тех же данных, когда сетевое оборудование сбоит или коннект крайне нестабильный, очень помогает траблшутить) в реальном времени.
| 1 | $sar-1TCP,ETCP1 |
Ну и последнее — конечно, по порядку, а не по значению — это просмотр самого сетевого трафика. Чаще всего для этого используют две утилиты: tcpdump и wireshark. Первая — консольная, ей можно, к примеру, запустить прослушивание на всех интерфейсах и записать трафик в дамп-файл в формате pcap:
| 1 | $tcpdump-wtest.dump |
Вторая же — графическая. Из нее можно точно так же запустить прослушивание, а можно просто открыть в ней готовый файл дампа, слитый с удаленного сервера. И наслаждаться красотой слоев модели OSI (точнее, TCP/IP).
Wireshark
Обзор популярных утилит для мониторинга железа в Linux
В интернете можно найти множество бесплатных программ для мониторинга датчиков компьютера под linux, среди которых:
- HTOP — одно из лучших консольных приложений, мониторит и позволяет закрывать процессы нажатием кнопки F9 или k (kill), показывает загрузку CPU, RAM, виртуальную память. Не показывает информации о сети, GPU и температуре CPU;
- Glances — программа работает удаленно через SSH, позволяет отслеживать запущенные процессы, загрузку CPU, RAM, виртуальную память, работу сети, операции I/O. Из-за того, что Glances написана на Python, потребляет слишком много ресурсов процессора, нет информации о GPU и температуре CPU;
- Conky — красивая оболочка с инфо о CPU (в том числе загрузке и температуре), RAM, SWAP, HDD. Нет данных о видеокартах;
- Stacer — утилита для мониторинга и очистки системы, работы с меню автозагрузки и службами. Нет информации о GPU;
Меню автоматической очистки системы в Stacer:
![]()
- netdata — мониторинг через браузер состояния CPU, RAM, SWAP, HDD. Нет SSH, данных о видеокартах;
- KsysGuard — мониторинг и работа с процессами, вывод инфо о состоянии CPU, RAM, загрузке системы;
- GNOME System Monitor — мониторинг CPU, RAM, SWAP, HDD, сети. Нет SSH, данных о видеокартах;
- GkrellM — виджет с информацией о CPU, его напряжении и вентиляторах, HDD. Нет данных о видеокартах;
- CoreFreq — очень подробная информация только о процессоре;
- nmon — мониторинг CPU, RAM, SWAP, HDD, сети. Нет SSH, данных о видеокартах;
- vtop — урезанная копия htop;
- atop — мониторинг процессов, CPU, RAM, SWAP, HDD, сети. Нет данных о GPU;
- lm-sensors — позволяет отслеживать загрузку и температуру процессора, скорость вентилятора кулера CPU. В дополнение к ней желательно использовать hddtemp и psensor;
- Psensor — утилита, отображающая информацию о температуре материнской платы и процессора (и его загрузке), старых видеокарт AMD (в которых используется ATI драйвер Catalyst), HDD, вентиляторах;
- Hardinfo — хорошая утилита для мониторинга железа под Linux, но безнадежно устаревшая (последний релиз — от 2009 года);
- Open Hardware Monitor — утилита, предоставляющая информацию о материнской плате, напряжении на процессоре, его температуре, вентиляторах, HDD, а также о видеокартах AMD, Nvidia. Программа изначально предназначена для Windows, для работы в Linux требуется Mono with WinForms и танцы с бубном. Последняя версия выпущена в ноябре 2016 года, поэтому на новом железе работоспособность не гарантируется.
Наиболее оптимальные из них для мониторинга, это: lm-sensors, Psensor, Hardinfo.
Среди этих программ нет утилит, предоставляющих данные о состоянии графической подсистемы компьютера.
Для видеокарт можно использовать следующие утилиты:
- Nvidia-SMI — входит в комплект драйверов Nvidia. Команда watch nvidia-sm позволяет отслеживать загрузку, температуру, состояние памяти, потребление, скорость вращения вентиляторов видеокарт производства компании Nvidia;
- TuxClocker — overclocking-утилита с графическим интерфейсом для разгона видеокарт Nvidia (от 600-й серии) и AMD при работе с драйверами amdgpu (все AMD карты до Radeon VII исключительно). Использует возможности Nvidia-SMI и nvidia-settings;
- GreenWithEnvy — Nvidia;
- WattmanGTK — AMD;
- Rocm-smi (утилита из пакета драйверов Rocm) — AMD;
- Radeon-profile — AMD.
Рассмотрим подробнее порядок установки и использования для майнинга лучших из этих приложений на рабочей станции под управлением операционной системы xubuntu 16.04.
Сам себе Большой Брат
Что вообще такое «мониторинг»? Поскольку я в свое время оканчивал химический университет, у меня это понятие четко ассоциируется с системами управления технологическими производствами. По сути, у нас есть ряд параметров сложной системы, которые мы отслеживаем, а по результатам можем, если необходимо, выполнить управляющее воздействие. Например, понизить давление в реакторе. Кроме того мы можем отправить уведомление оператору, который уже независимо примет то или иное управляющее решение.
У тех, кто далек от химии, но близок к IT, ассоциация немного другая, но в целом похожая — обычно это экран с кучей графиков, на которых творится какая-то магия, как в голливудских сериалах. Для многих администраторов так оно и выглядит — Graphite/Icinga/Zabbix/Prometheus/Netdata (нужное подчеркнуть) как раз рисуют красивый интерфейс, в который можно задумчиво глядеть, почесывая бороду и гладя свитер.
Большинство этих систем работают одинаково: на конечные ноды, за которыми мы хотим наблюдать, устанавливаются так называемые агенты, или коллекторы, а дальше все происходит по методике push или pull. То есть либо мы указываем этому агенту мастер-ноду, и он начинает периодически отсылать туда отчеты и heartbeat, либо же, наоборот, мы добавляем ноду в список для мониторинга на мастере, а тот уже, в свою очередь, сам ходит и опрашивает агенты о текущей ситуации.
Нет, я не буду рассказывать в подробностях, как настраивать подобные системы. Вместо этого мы голыми руками докопаемся до того, что вообще происходит в системе.
Формат команды inxi
inxi inxi inxi
где опции команды:
- -h меню справки
- -help То же, что -h
- -A Показать аудио/звуковую информацию карты.
- -b Показывает основную информацию
- -c Доступные цветовые схемы. Требуется номер схемы. Поддерживаемые цветовые схемы от 0-32
- -с цвет селектора, запустить опцию выбора цвета до начала inxi запуска , который позволяет установить значение конфигурационного файла для выбора.
- -C Показать полную мощность процессора, в том числе тактовую частоту процессора и маск. скорость процессора (если таковая имеется).
- -d Отображает данные накопителей на оптических дисках.
- -D Показывает полную информацию о жестком диске, а не только о модели, то есть:/dev/sda model: Hitachi_HDS72105 size: 500.1GB.
- -f Может показать все флаги центрального процессора, используются не только короткий список.
- -F Показать полный выход для inxi. Включает в себя все буквы в верхнем регистре, плюс строки -s и -n.
- -G Показать графическую информацию карты. Информация о карте(ах), Display Server (поставщика и номер версии), например: Display Server: X.Org 1.18.4, разрешение экрана, и т.д.
- -i Показывает Wan IP-адрес, и показывает локальные интерфейсы (требуется Ifconfig сетевой инструмент).
- -I Показать информацию: процессы, время бесперебойной работы, память, Irc клиент
- -l Показать метки разделов. По умолчанию: короткий раздел -P. Для полного -p вывода, используйте: -pl (или -plu).
- -m память (RAM) данных. Не показывать с -b или -F , если вы используете -m в явном виде.
- -n Показать Advanced Network информационная карта. То же -nn. Показывает интерфейс, скорость, состояние и т.д.
- -N Показать сетевую информационную карту.
- -o Показать несмонтированную информацию о разделе (включая UUID и маркировки если таковые имеются). Показывает тип файловой системы
- -p Показать полную информацию о разделах (-P плюс все другие обнаруженные разделы).
- -S Информация о системе: имя хоста, ядро, окружение рабочего стола (если в X), дистрибутив.
- -u Показывает разделы UUID. По умолчанию: короткий раздел -P. Для полного -p вывода, используйте: -Pu (или -plu).
Несколько примеров использования inxi:
- inxi -m — сведения о памяти
- inxi -s — температура CPU
- inxi -d — жесткие диски
- inxi -v4 -c6 OR inxi -bDc 6 — информация о системе, материнской плате, процессоре, графическом адаптере, сетевой карте и жестких дисках.
- inxi -v5 -c29 OR inxi -aSu 19 — информация о системе, материнской плате, процессоре, памяти, графическом адаптере, звуковой и сетевой карте, жестких дисках / флешках которые подключены, RAID, температура процессора и краткая информация о процессоре.
Где хранить коллекцию лютневой музыки
Если ты хоть раз размечал диск руками (например, при установке Arch Linux), то наверняка знаешь о существовании утилиты
fdisk. С ее помощью проще всего посмотреть разделы на этом самом диске:
| 1 | $sudo fdisk-l |
Есть ее более развесистая версия с псевдографическим интерфейсом, называется cfdisk, а также еще пара утилит, которые, на первый взгляд, делают весьма похожие вещи — позволяют управлять разделами на дисках. Это parted (к которому, кстати, есть неплохой GUI на GTK в лице gparted) и gdisk. Наличие такого зоопарка связано с тем, что существует несколько вариантов структурирования разделов на диске, и исторически для разных вариантов использовались разные программы. Наверняка ты уже встречал такие аббревиатуры, как MBR и GPT. Я не буду подробно останавливаться на различиях, но почитать можно, например, в статье «Сравнение структур разделов GPT и MBR». Там оно обсуждается с позиции настройки Windows, но суть от этого не меняется. И да, в современном же мире fdisk уже умеет работать с обоими вариантами, как и parted, поэтому выбирать можно исключительно из личных предпочтений.
Но вернемся к сбору информации. Мы знаем, какие у нас разделы, а теперь давай взглянем на дерево файловой системы, точнее, что куда смонтировано:
| 1 | $df-h |
Как и раньше,
-h тут отвечает за «человеческий» вывод размеров. Ну и как ты помнишь, размеры файлов у нас можно посмотреть командой
du:
| 1 | $du-h/path/to/folder |
Наверняка часть читателей сейчас подумала: «Ну что за банальщина, это даже школьники знают, давай чего посвежее». Ладно, давай привнесем реалтайма, как уже делали с оперативкой:
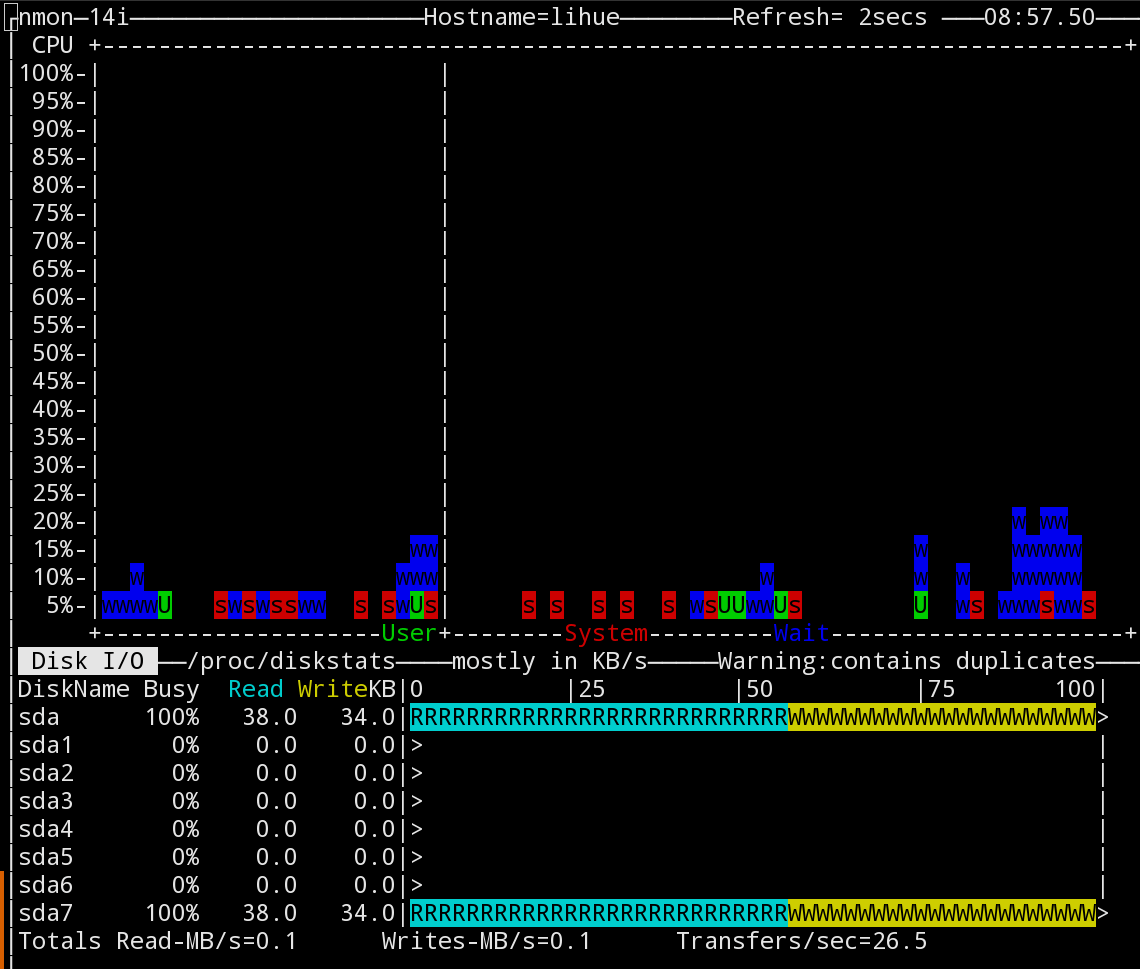
| 1 | $iostat-xz1 |
Эта команда выводит средние значения количества операций чтения-записи для всех блочных устройств в системе, обновляя информацию раз в секунду. Это больше «железные» параметры, поэтому есть еще одна команда для просмотра статистики I/O попроцессно, и она, по аналогии, называется iotop.
| 1 | $sudo iotop |
При попытке запуска без прав root она начнет очень мило оправдываться, что, мол, есть один такой баг CVE-2011-2494, который может приводить к утечке потенциально важных данных от одних пользователей другим, «поэтому настрой-ка ты, дружочек, sudo». Оно и верно.
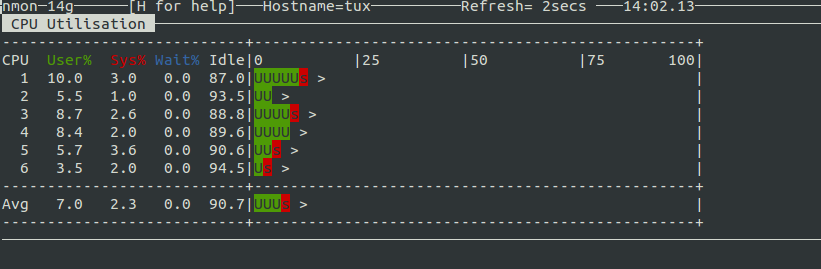
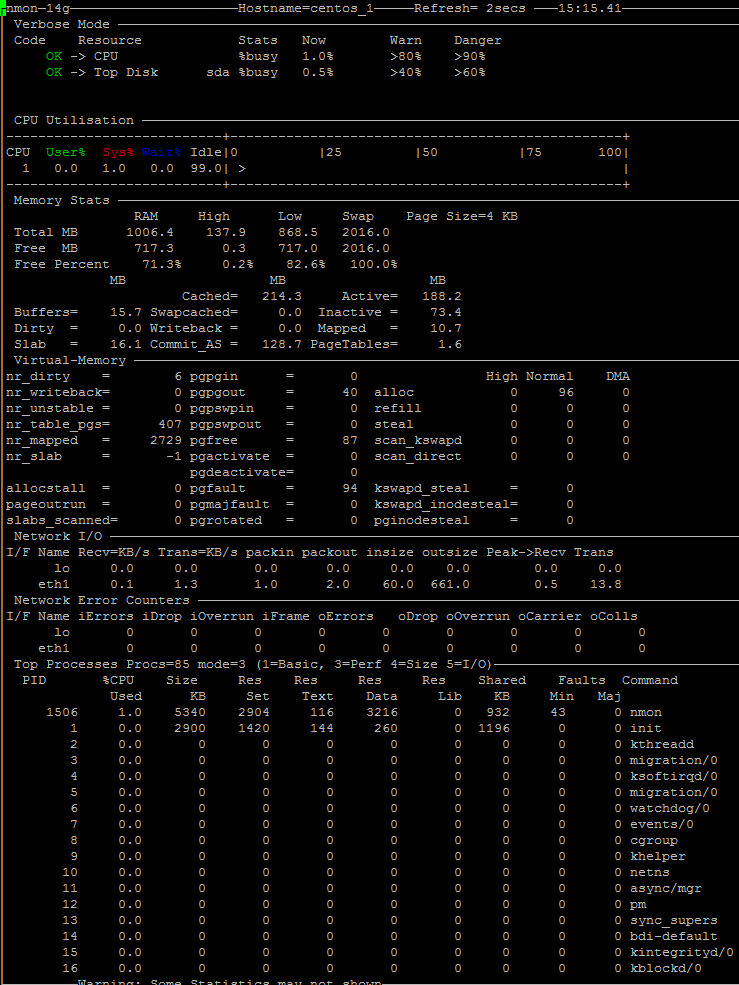
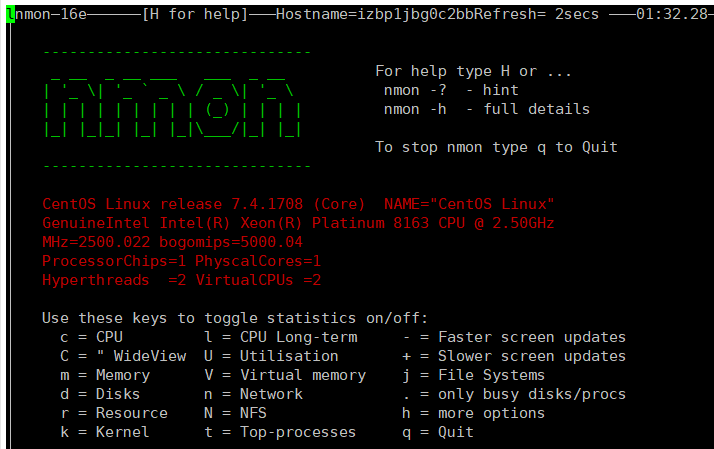
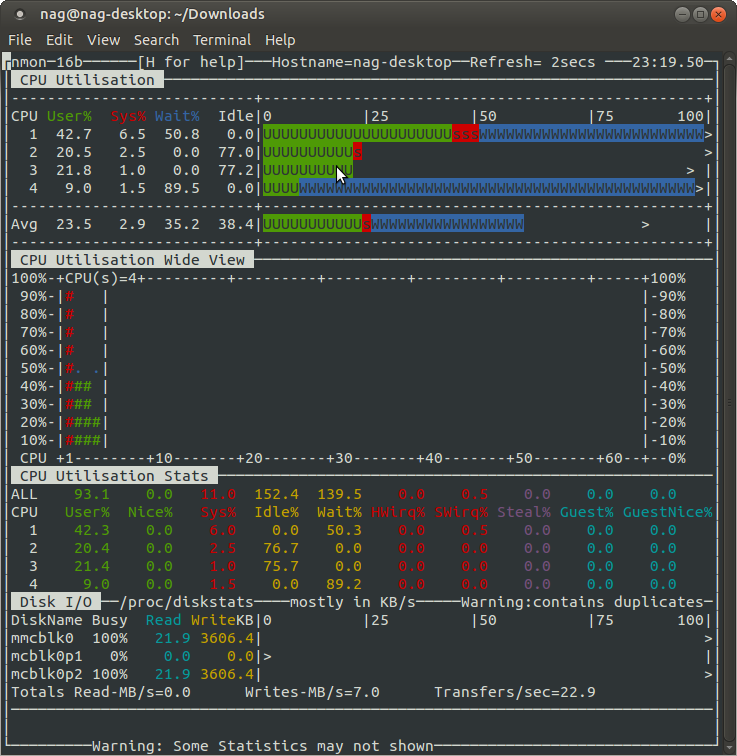
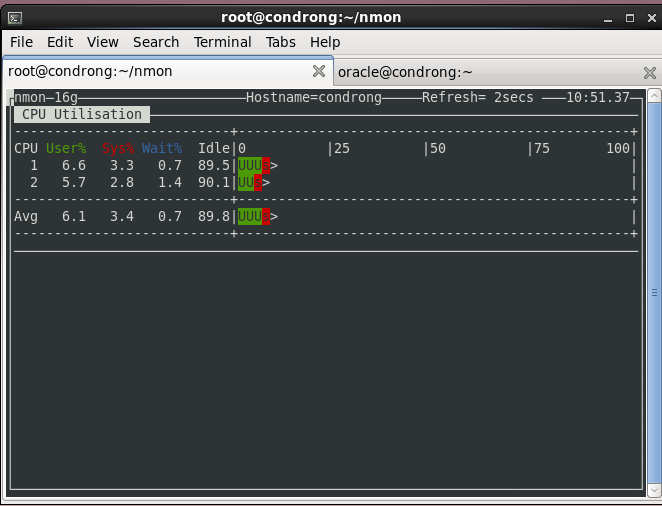
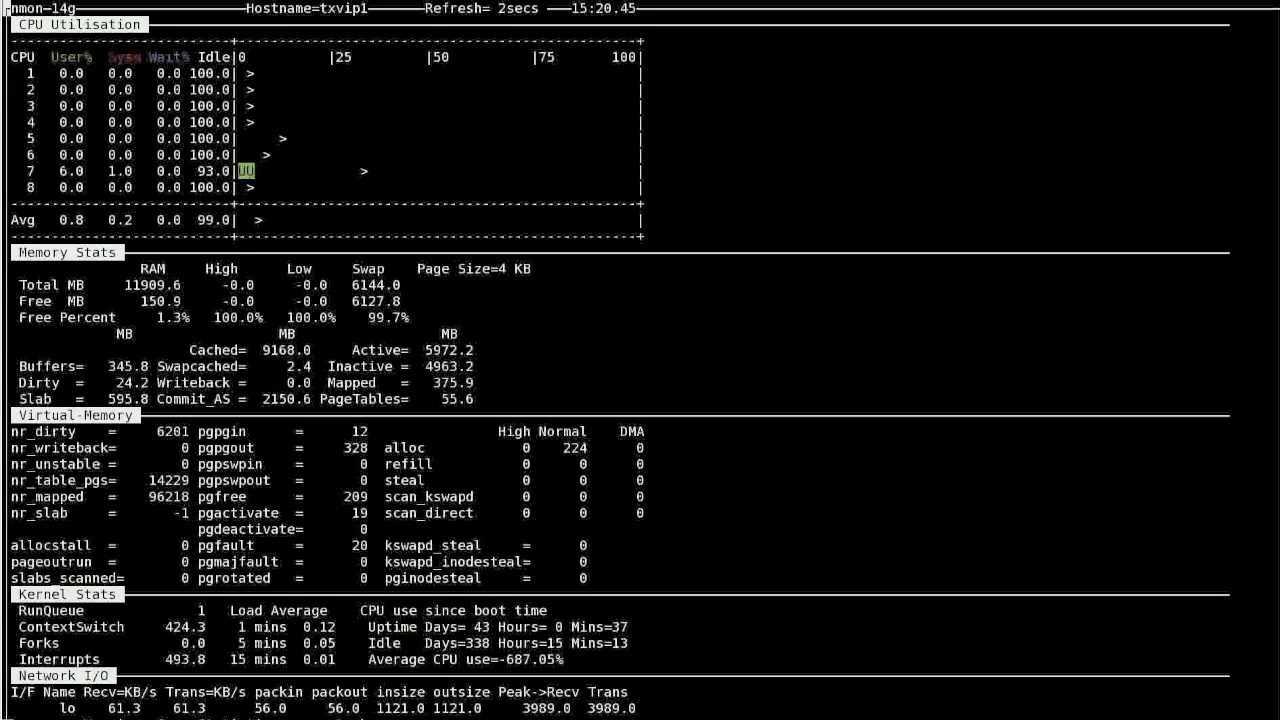
Работа с nmon
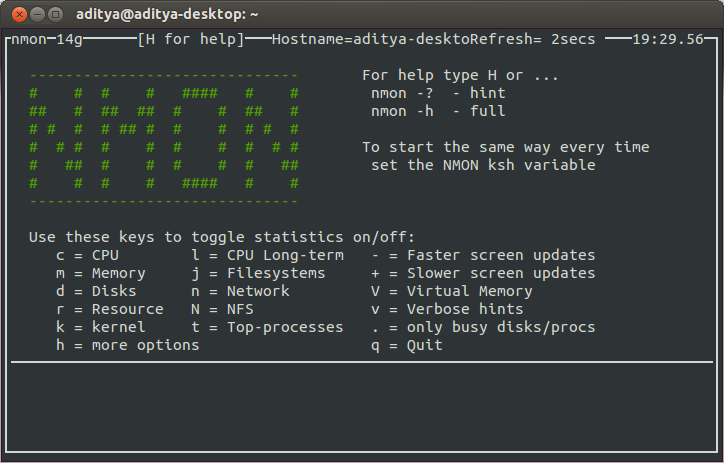
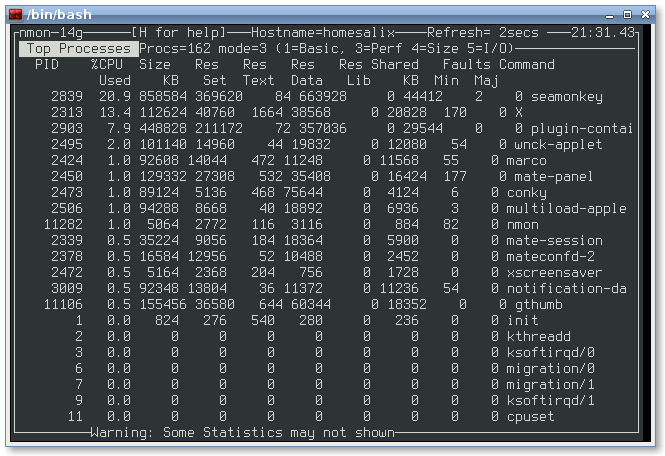
Итак, nmon установлен, теперь можно его запустить, выполнив команду . В окне утилиты, показанном на рисунке ниже, надо указать, какие именно сведения вас интересуют, включая и отключая соответствующие информационные разделы.
![]() Главное окно nmon содержит подсказки по включению и отключению различных разделов сведений о системе
Главное окно nmon содержит подсказки по включению и отключению различных разделов сведений о системе
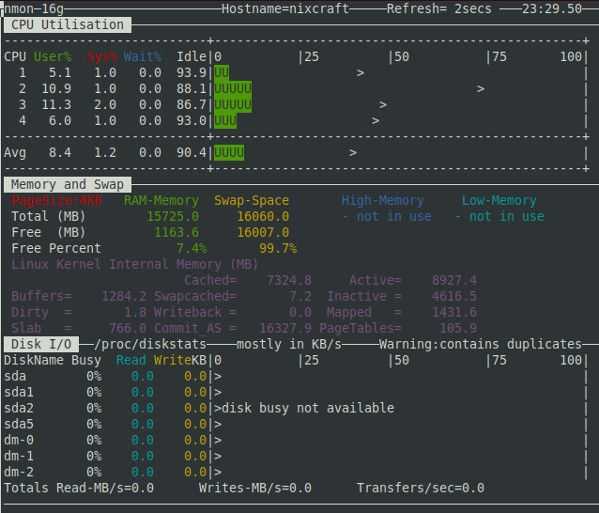
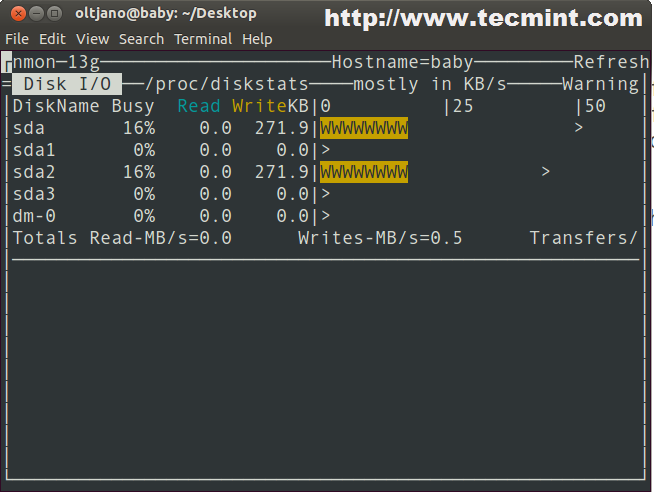
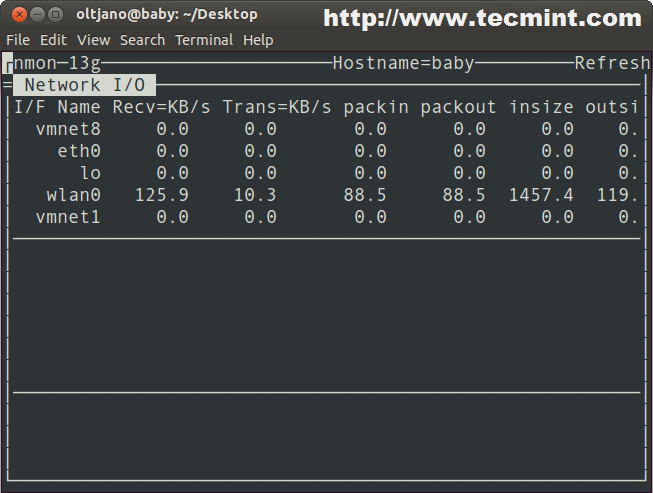
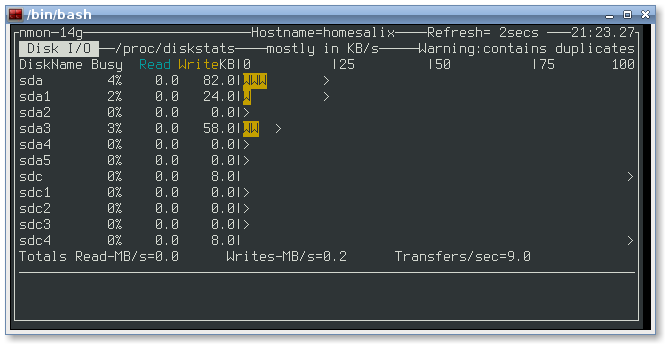
Скажем, вас интересуют дисковые накопители. Если нажать клавишу на клавиатуре, nmon выведет данные обо всех подключённых к серверу дисках.
![]() Средство мониторинга nmon выводит данные о дисках
Средство мониторинга nmon выводит данные о дисках
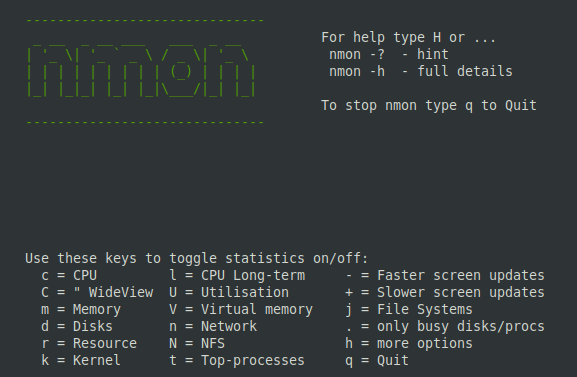
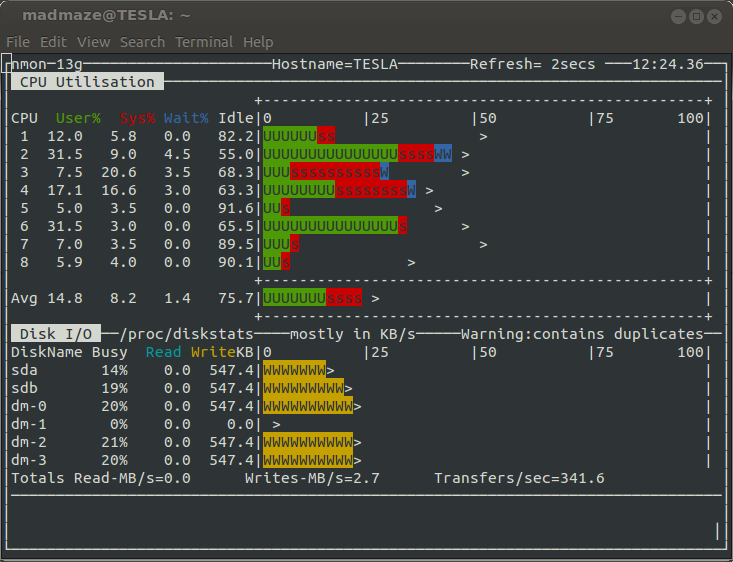
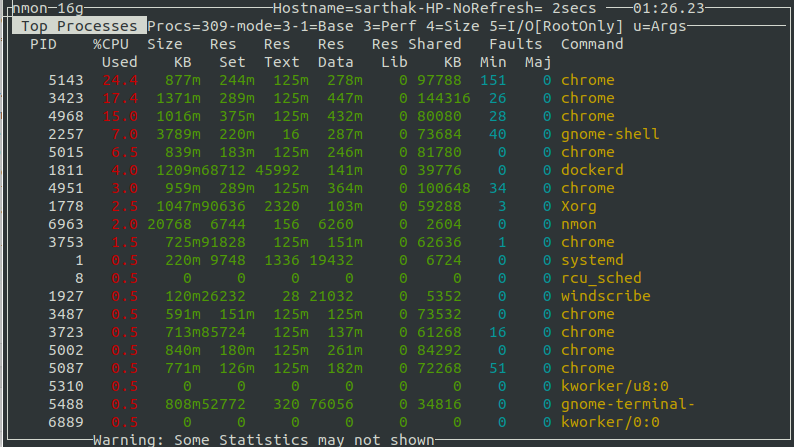
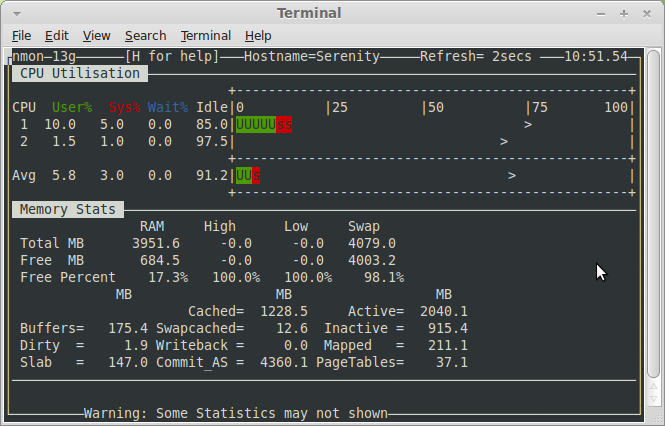
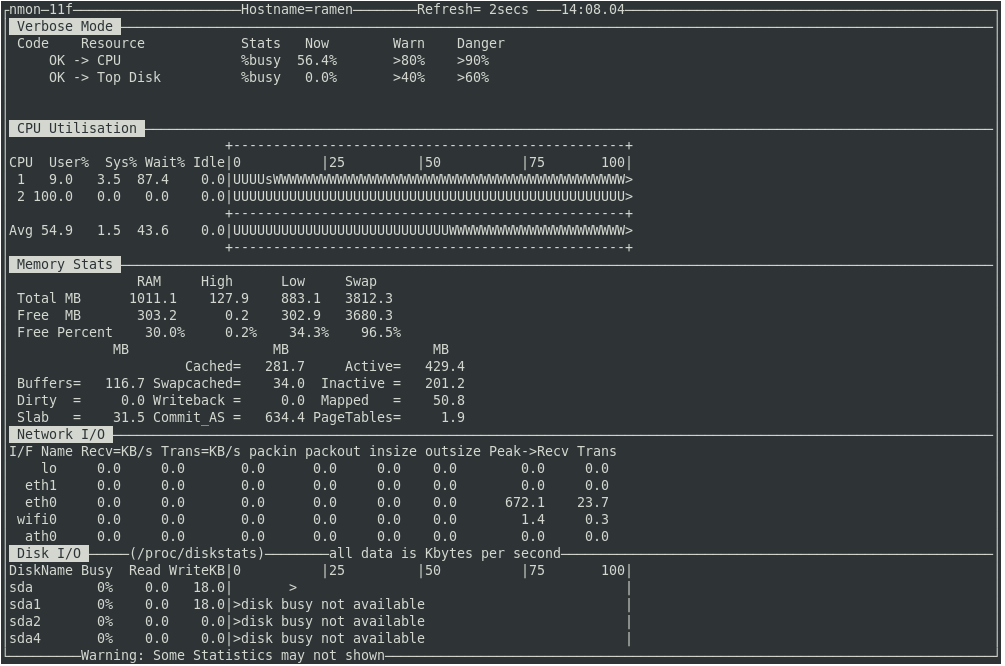
Далее, добавим информационные разделы со сведениями о сети и памяти, нажав клавиши и . В итоге, набор данные о системе будет дополнен интересующими нас показателями.
![]() Добавление в окно мониторинга сведений о сетевой подсистеме и памяти
Добавление в окно мониторинга сведений о сетевой подсистеме и памяти
Выключить отображение тех или иных разделов можно с помощью тех же клавиш, которые использовались для их вывода на экран. Кроме того, nmon поддерживает возможность менять скорость обновления данных. Делается это с помощью клавиш «» и «» на клавиатуре. Первая, соответственно, уменьшает скорость обновления показателей, вторая — увеличивает.
Для того, чтобы выйти из nmon, нажмите клавишу , это возвратит вас к обычному приглашению bash.
Системный монитор Gnome Linux
Приложение System Monitor позволяет отображать основную системную информацию и отслеживать системные процессы, использование системных ресурсов и файловых систем. Его также можно использовать для изменения поведения вашей системы. Хотя он и не такой мощный, как KDE System Guard, но зато он предоставляет основную информацию, которая может быть полезна для новых пользователей:
- Отображение основной информации об аппаратном и программном обеспечении компьютера.
- Версия ядра Linux
- Версия GNOME
- Аппаратные средства
- Встроенная память
- Процессоры и скорость работы
- Состояние системы
- Доступное дисковое пространство
- Процессы
- Память
- Использование сети
- Файловые системы
- Список всех файловых систем с основной информацией о каждой.
сбор информации
1. Сбор данных
Чтобы отслеживать использование системы в течение определенного периода времени и записывать результаты в режиме реального времени, вы можете выполнить следующие команды:
Параметры поясняются следующим образом:
- -f: выводить файлы в стандартном формате: <имя хоста> _YYYYMMDD_HHMM.nmon
- -t: включить в вывод процессы с более высокой степенью занятости.
- -s 30: сбор данных каждые 30 секунд
- -c 180: собрать всего 180 раз
- -m Каталог хранения сгенерированного файла данных
Сгенерированный файл .nmon выглядит следующим образом:
2. Завершите процесс nmon.
При выполнении приведенного выше кода, если процесс nmon не остановлен, процесс сбора данных продолжится. Используйте следующую команду, чтобы просмотреть номер процесса nmon и завершить процесс.
После завершения процесса вы можете скопировать сгенерированный файл .nmon в систему Windows и использовать инструмент nmon analyser.xls для графического сбора данных. См. Следующий раздел.





