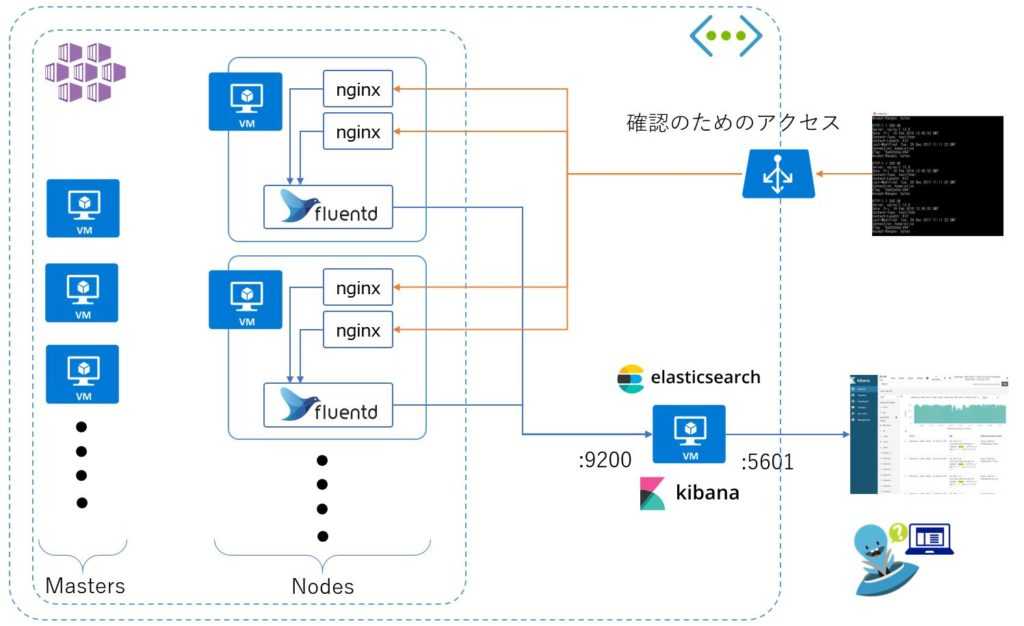
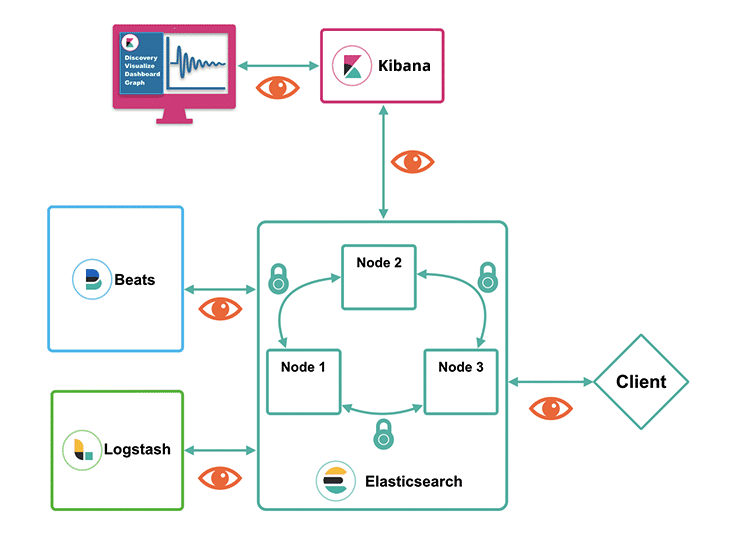
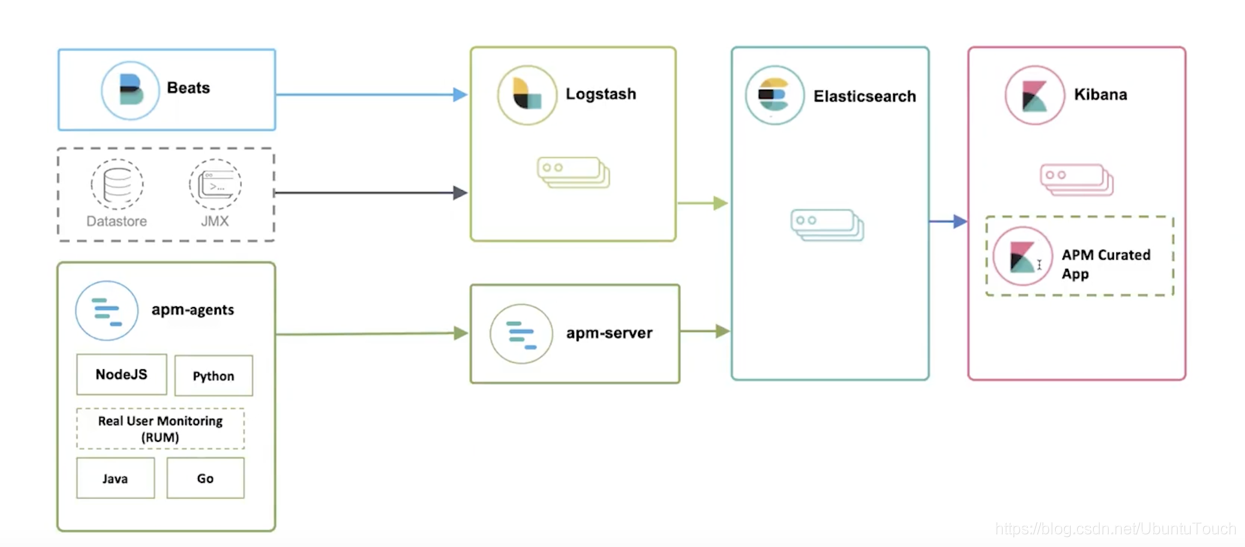
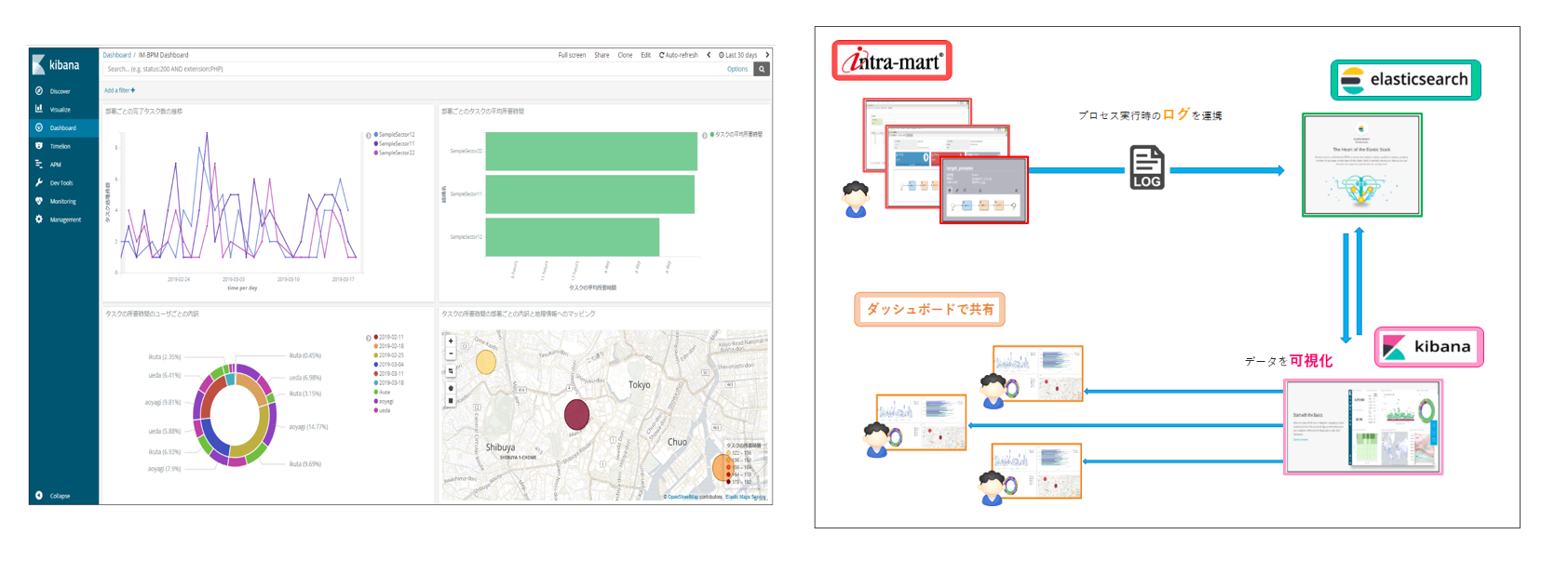
5: Дашборды Kibana
Теперь давайте посмотрим, как работает Kibana.
В браузере откройте FQDN или внешний IP сервера Elastic. Введите свои учетные данные из раздела 2, и вы попадете на домашнюю страницу Kibana.
Нажмите Discover в левой панели навигации. На странице Discover выберите предопределенный шаблон индекса filebeat-*, чтобы увидеть данные Filebeat. По умолчанию будут показаны все данные лога за последние 15 минут. Вы увидите гистограмму с событиями и некоторыми сообщениями лога.
Здесь вы можете искать и просматривать логи, а также настраивать дашборды. На данный момент, однако, там не будет много данных, потому что сейчас отображаются только системные логи сервера Elastic Stack.
Используйте левую панель, чтобы перейти на страницу Dashboard и выполнить поиск по Filebeat System. Оказавшись там, вы можете искать примеры дашбордов, которые поставляются с модулем system.
Например, вы можете просмотреть подробную статистику на основе ваших сообщений системного лога или узнать, какие пользователи и когда использовали команду sudo.
У Kibana есть много других функций, таких как построение графиков и фильтров. Исследуйте их самостоятельно.
Документация Django
Django (Джанго) — свободный фреймворк для веб-приложений на языке Python, использующий шаблон проектирования MVC. Проект поддерживается организацией Django Software Foundation.
Сайт на Django строится из одного или нескольких приложений, которые рекомендуется делать отчуждаемыми и подключаемыми. Это одно из существенных архитектурных отличий этого фреймворка от некоторых других (например, Ruby on Rails). Один из основных принципов фреймворка — DRY (англ. Don’t repeat yourself).
Также, в отличие от других фреймворков, обработчики URL в Django конфигурируются явно при помощи регулярных выражений.
Для работы с базой данных Django использует собственный ORM, в котором модель данных описывается классами Python, и по ней генерируется схема базы данных.
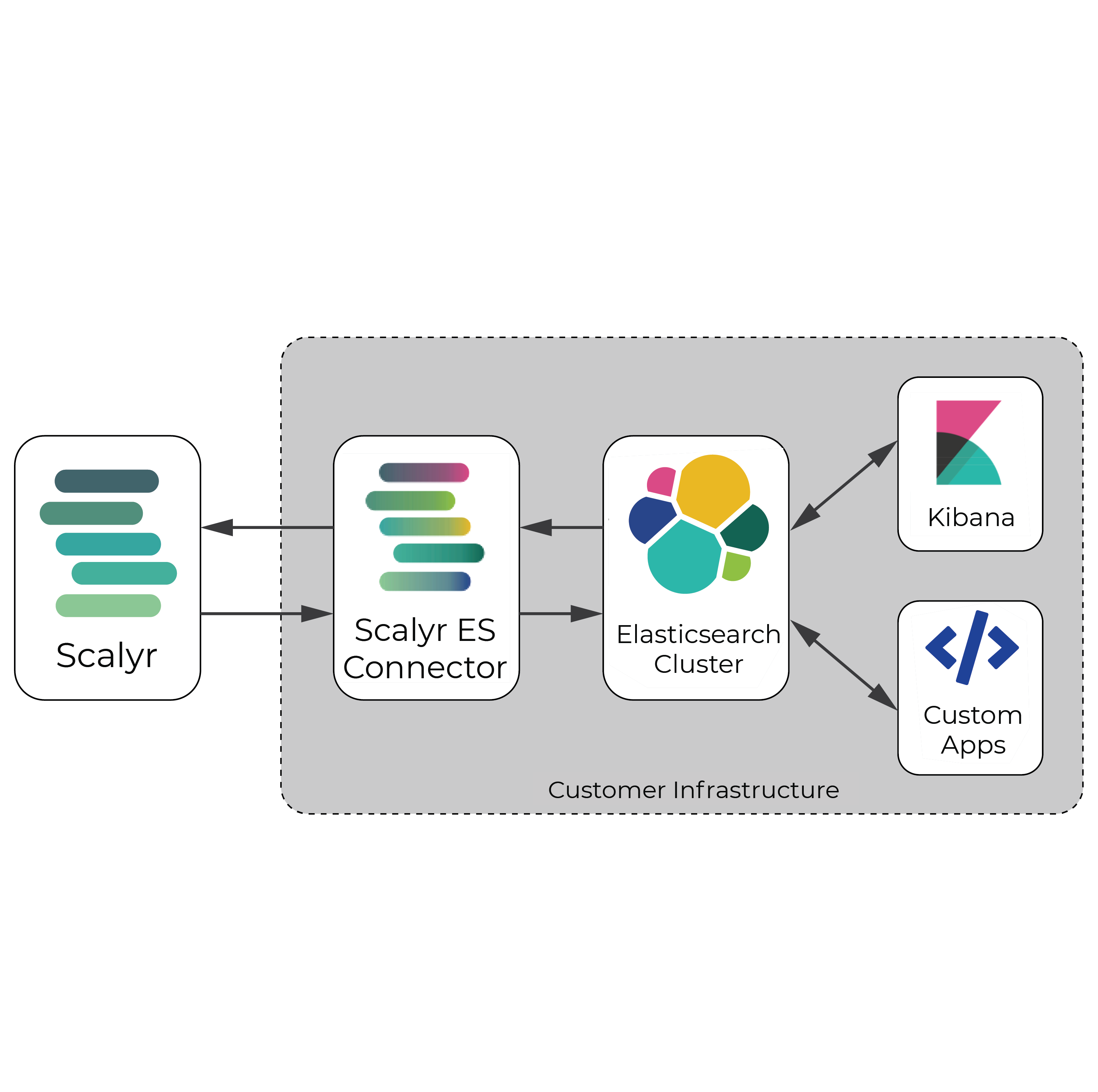
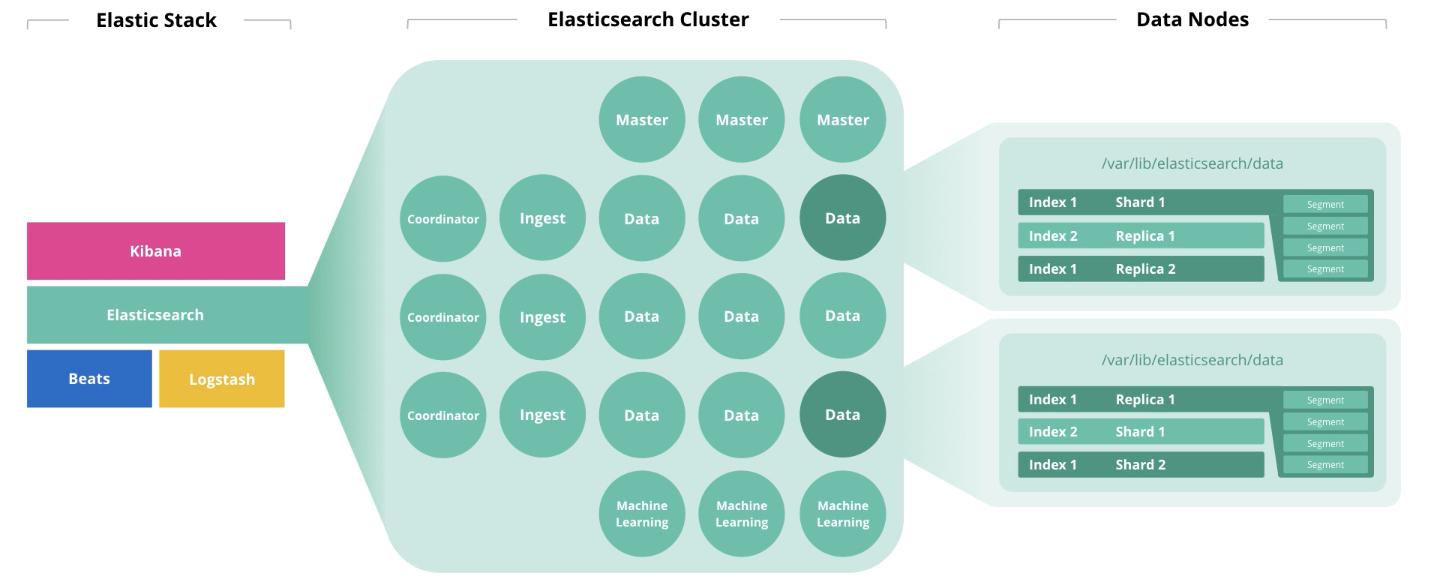
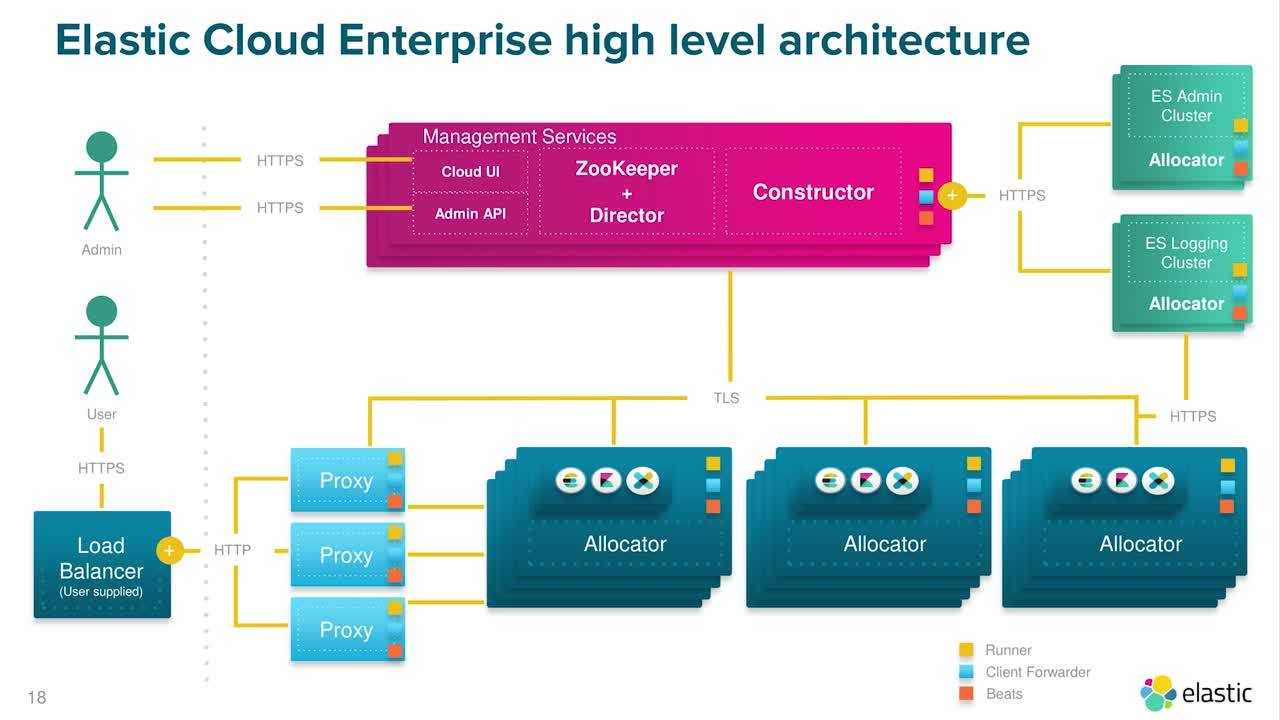
Такие разные эластики: чем Elastic Cloud Enterprise отличается от Amazon Elasticsearch Service и при чем здесь Amazon EC2 и Open Distro
Как и большинство современных Big Data решений, сегодня ELK Stack активно используется в облачной модели под названием ECE (Elastic Cloud Enterprise). Этот продукт позволяет удаленно работать с Elasticsearch (ES) и Kibana в любом объеме и на любой инфраструктуре, обеспечивая масштабирование, безопасность, обновление и резервное копирование всех компонентов с централизованной консоли. Таким образом, развертывать Elasticsearch и Kibana можно как на локальных физических серверах физическое оборудование, так и в виртуальных средах, частных и общественных облаках, таких как Google, Microsoft Azure, Amazon Web Services (AWS), Яндекс.Облако, Mail.ru Cloud Solutions и пр. [1.
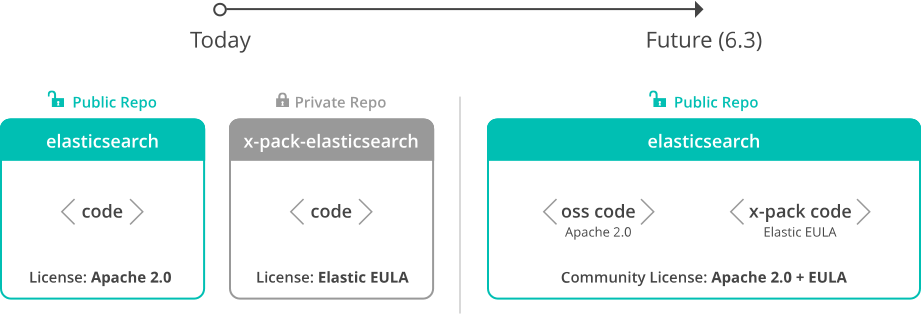
Отметим, что при схожести названий, сервис Amazon Elasticsearch не связан с компанией Elastic, которая не является партнером или участником Amazon Elasticsearch Service, а также не занимается поддержкой этого продукта. Например, ECE включает компонент X-Pack, который обеспечивает информационную безопасность, графовую аналитику и машинное обучение, о чем мы рассказывали здесь. Также ECE поддерживает локализацию Kibana под восточные языки (китайский, японский), кросс-кластерный и асинхронный поиск, нативный SQL и множество других возможностей .
В свою очередь, Amazon Elasticsearch Service позиционируется как управляемый сервис, который упрощает развертывание и эксплуатацию кластеров ES в облаке AWS, позволяя on-demand использовать эту Big Data систему в любом масштабе, включая API с открытым исходным кодом, Kibana, интеграцию с Logstash и другими сервисами AWS, оповещения и SQL-подобные запросы . Не стоит путать этот сервис с платформой Amazon Elastic Compute Cloud (Amazon EC2), которая через веб-интерфейс предоставляет безопасные масштабируемые вычислительные ресурсы в облаке. Amazon EC2 предоставляет доступ к вычислительным ресурсам с целью их настройки и использования в различных бизнес-приложениях, в т.ч. включая компоненты Apache Hadoop, Kafka, Spark и прочие Big Data фреймворки. Elasticsearch с Kibana также могут быть развернуты на облачной платформе Amazon EC2 .
Наконец, стоит отметить, что Amazon Elasticsearch Service работает на Open Distro for Elasticsearch – open-source проекте, представленном в марте 2019 года . Историю появления этого продукта мы описывали здесь. Он включает полезные функциональные возможности для Elasticsearch и Kibana :
- обеспечение информационной безопасности – аутентификацию через Active Directory, Kerberos, SAML и OpenID, реализацию единой точки входа (SSO), шифрование трафика, RBAC-модель избирательного разграничения доступа, детальное логирование для аудита и средства соблюдения требований (compliance);
- мониторинг за состоянием кластера и данных, генерация предупреждений с автоматической отправкой уведомления при срабатывании определённых проверок в случае внештатных ситуаций, сбоев и событий нарушения безопасности.
- поддержка более 40 функций SQL, в т.ч. экспорт в CSV и JSON, операции слияния (JOIN). SQL-запросы транслируются в JSON-запросы к ES, а интеграция со сторонними приложениями доступна через JDBC- драйвер;
- диагностика и анализ производительности кластера – отслеживание внутренних метрик ES и системных параметров (RAM, CPU, жесткие диски) через REST API и CLI-интерфейс PerfTop.
Основа:
Аутентификация(authentication, от греч. αὐθεντικός – реальный, подлинный; от αὐθέντης – автор) — это процесс проверки учётных данных пользователя (логин/пароль). Проверка подлинности пользователя путём сравнения введённого им логина/пароля с данными сохранёнными в базе данных.
Авторизация(authorization — разрешение, уполномочивание) — это проверка прав пользователя на доступ к определенным ресурсам.
Например, после аутентификации юзер sasha получает право обращаться и получать от ресурса «super.com/vip» некие данные. Во время обращения юзера sasha к ресурсу vip система авторизации проверит имеет ли право юзер обращаться к этому ресурсу (проще говоря переходить по неким разрешенным ссылкам)
- Юзер c емайлом sasha_gmail.com успешно прошел аутентификацию
- Сервер посмотрел в БД какая роль у юзера
- Сервер сгенерил юзеру токен с указанной ролью
- Юзер заходит на некий ресурс используя полученный токен
- Сервер смотрит на права(роль) юзера в токене и соответственно пропускает или отсекает запрос
Собственно п.5 и есть процесс авторизации.
Дабы не путаться с понятиями Authentication/Authorization можно использовать псевдонимы checkPassword/checkAccess(я так сделал в своей API)
JSON Web Token (JWT) — содержит три блока, разделенных точками: заголовок(header), набор полей (payload) и сигнатуру. Первые два блока представлены в JSON-формате и дополнительно закодированы в формат base64. Набор полей содержит произвольные пары имя/значения, притом стандарт JWT определяет несколько зарезервированных имен (iss, aud, exp и другие). Сигнатура может генерироваться при помощи и симметричных алгоритмов шифрования, и асимметричных. Кроме того, существует отдельный стандарт, отписывающий формат зашифрованного JWT-токена.
Пример подписанного JWT токена (после декодирования 1 и 2 блоков):
Токены предоставляют собой средство авторизации для каждого запроса от клиента к серверу. Токены(и соответственно сигнатура токена) генерируются на сервере основываясь на секретном ключе(который хранится на сервере) и payload’e. Токен в итоге хранится на клиенте и используется при необходимости авторизации какого-либо запроса. Такое решение отлично подходит при разработке SPA.
При попытке хакером подменить данные в header’ре или payload’е, токен станет не валидным, поскольку сигнатура не будет соответствовать изначальным значениям. А возможность сгенерировать новую сигнатуру у хакера отсутствует, поскольку секретный ключ для зашифровки лежит на сервере.
access token — используется для авторизации запросов и хранения дополнительной информации о пользователе (аля user_id, user_role или еще что либо, эту информацию также называет payload). Все поля в payload это свободный набор полей необходимый для реализации вашей частной бизнес логики. То бишь user_id и user_role не являются требованием и представляют собой исключительно частный случай. Сам токен храним не в localStorage как это обычно делают, а в памяти клиентского приложения.
refresh token — выдается сервером по результам успешной аутентификации и используется для получения новой пары access/refresh токенов. Храним исключительно в httpOnly куке.
Каждый токен имеет свой срок жизни, например access: 30 мин, refresh: 60 дней
Поскольку токены(а данном случае access) это не зашифрованная информация крайне не рекомендуется хранить в них какую либо (passwords, payment credentials, etc…)
Роль рефреш токенов и зачем их хранить в БД. Рефреш на сервере хранится для учета доступа и инвалидации краденых токенов. Таким образом сервер наверняка знает о клиентах которым стоит доверять(кому позволено авторизоваться). Если не хранить рефреш токен в БД то велика вероятность того что токены будут бесконтрольно гулять по рукам злоумышленников. Для отслеживания которых нам придется заводить черный список и периодически чистить его от просроченных. В место этого мы храним лимитированный список белых токенов для каждого юзера отдельно и в случае кражи у нас уже есть механизм противодействия(описано ниже).
Сервер ресурсов
На сервер ресурсов будем обращаться на /messages за данными:
@RestController
public class MessagesController {
@GetMapping("/messages")
public String[] getMessages() {
return new String[] {"Message 1", "Message 2", "Message 3"};
}
}
То, что /messages — защищенный url, указываем в конфигурации:
@EnableWebSecurity
public class ResourceServerConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.mvcMatcher("/messages/**")
.authorizeRequests()
.mvcMatchers("/messages/**").access("hasAuthority('SCOPE_message.read')")
.and()
.oauth2ResourceServer()
.jwt();
}
}
В вышеприведенном коде мы сказали, что авторизация осуществляется через OAuth 2, то есть для доступа необходимо иметь в запросе заголовок Authorization с JWT-токеном (он же access token).
Но как сервер ресурсов поймет, корректен ли пришедший в заголовке JWT-токен? Для этого в настройках application.yml указываем, куда сервер ресурсов должен обращаться за проверкой корректности:
spring:
security:
oauth2:
resourceserver:
jwt:
jwk-set-uri: http://auth-server:9000/oauth2/jwks
То есть обращаться он должен на сервер авторизации http://auth-server:9000/oauth2/jwks. Сервер авторизации выдавал токен, он его и проверит.
Конечно, в POM-файле сервера ресурсов необходима зависимость:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-oauth2-resource-server</artifactId>
</dependency>
Теперь можно обращаться на сервер ресурсов с полученным выше токеном и получить данные.
Запрос на сервер ресурсов и ответ
Составим запрос с полученным токеном. Токен необходимо помещать в заголовок Authorization с префиксом Bearer:
GET /messages HTTP/1.1 Host: localhost:8090 Authorization: Bearer eyJraWQiOiI5ZGM3MDA3Mi0xMDk2LTRkYjctOTRkYi1kY2RmMzE0OTJjZjIiLCJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJzdWIiOiJtZXNzYWdpbmctY2xpZW50IiwiYXVkIjoibWVzc2FnaW5nLWNsaWVudCIsIm5iZiI6MTYwMzcwOTg4NSwic2NvcGUiOlsibWVzc2FnZS5yZWFkIiwibWVzc2FnZS53cml0ZSJdLCJpc3MiOiJodHRwczpcL1wvb2F1dGgyLnByb3ZpZGVyLmNvbSIsImV4cCI6MTYwMzcxMzQ4NSwiaWF0IjoxNjAzNzA5ODg1LCJqdGkiOiI1N2RmY2UxNi1lOGRiLTRlY2MtYTdhOC0zZjc5MjRmOTJjMmUifQ.RBSysR0WVSQBXsFPfFg_u2QNxlE7HANdWnUuROxxzJbvTfapQ3T8WB0QS8V46f4yGaWymNzLAz8e_rdBsY3AKXMlZv7H0bDwifqJBQde2bpYPUIdLdzO3lJkWqMkUGY32tM1hN9ZOOrk9sQ9fW5PuKgZGXZpsKMc8DLZrzuhavc7lM94ft5EJOuEBwlOcBUOTx0qOrL6BkLGm1dcmVmTP983vgd7A9pSwY9ZHlKLfdVjQK3iFyrGA0WF7NEQQ8soWqW_otHapUQ08XVRW4vcsUSyH1QAHqonGk2R7T6dv18Vk_9nGjUfbmS4pGswgLRE0JnhSXZoTWsKHh7i-ixXpA
Этот же запрос в Postman с ответом:
![]()
Если же токен не прикладывать, вернется 401 с заголовком:
WWW-Authenticate: Bearer
Однако, в реальности при запросе ресурса выполняется не один запрос, а два — есть еще дополнительный запрос от сервера ресурсов к серверу авторизации для проверки токена. И это можно увидеть в консоли в IntelliJ IDEA.
Проверка access токена
В консоли запущенного сервера ресурсов мы увидим, что он обращается на сервер авторизации по адресу
http://auth-server:9000/oauth2/jwks
для проверки access токена:
2020-10-26 13:32:37.387 DEBUG 13124 --- o.s.web.client.RestTemplate : HTTP GET http://auth-server:9000/oauth2/jwks 2020-10-26 13:32:37.390 DEBUG 13124 --- o.s.web.client.RestTemplate : Accept=[text/plain, application/json, application/*+json, */*] 2020-10-26 13:32:37.408 DEBUG 13124 --- o.s.web.client.RestTemplate : Response 200 OK
Мы для этого просто указали в настройках сервера ресурсов конечную точку для проверки.
Давайте теперь настроим и запустим последнюю часть примера — клиент, который будет действовать за нас вместо POSTMAN.
Истоки OAuth 2
В 2000-ых годах стали появляться сайты, которые хотят воспользоваться вашими ресурсами, находящимися на другом сайте. Например, сервис печати фотографий хочет получить доступ к вашим фото на Google. Или сайт Yelp (это сайт с рейтингами услуг) хочет получить список ваших контактов в Google, чтобы выслать им приглашение. Все бы ничего, но эти «желающие» требовали дать их сервису ваш пароль от Google, MSN и т.п., чтобы осуществить свои услуги.
А иначе они не могли, потому что протокола OAuth2 не было. Вот доказательство:
![]() Какой-то стартап Yelp хотел пароль от вашего Google
Какой-то стартап Yelp хотел пароль от вашего Google
Какое-то время это безобразие существовало, но люди придумывали, как его прекратить.
А именно: как сохранить возможность доступа одного сайта-клиента (нашего борзого Yelp или сервиса печати фотографий) к ресурсам пользователя на другом сайте (на Google), чтобы при этом пользователь не передавал малоизвестному Yelp имя и пароль от Google.
В итоге появился протокол — сначала OAuth 1, а в 2012 — современный OAuth 2.
2: Установка и настройка Kibana
Согласно официальной документации, устанавливать Kibana следует только после Elasticsearch. Такой порядок гарантирует, что все зависимые друг от друга программы будут установлены правильно.
Поскольку вы уже добавили исходный список Elastic, сейчас вы можете просто установить остальные компоненты стека с помощью apt:
Чтобы включить сервис Kibana, введите:
Поскольку Kibana прослушивает только локальный хост, нужно настроить обратный прокси-сервер, чтобы разрешить внешний доступ к сервису. Для этой цели мы будем использовать Nginx, который уже должен быть установлен на вашем сервере (согласно требованиям к мануалу).
Сначала используйте команду openssl, чтобы создать администратора Kibana, которого вы будете использовать для доступа к веб-интерфейсу. В качестве примера назовем эту учетную запись kibanaadmin, но для большей безопасности рекомендуется выбрать нестандартное имя, которое будет сложно угадать.
Следующая команда создаст администратора и пароль Kibana и сохранит их в файле htpasswd.users. Nginx будет запрашивать это имя и пароль в этом файле (скоро мы настроим это).
Введите и подтвердите пароль в командной строке. Запомните эти данные, так как они понадобятся вам для доступа к веб-интерфейсу Kibana.
Далее нужно создать файл блока server Nginx. Мы используем условный домен your_domain, но вы можете выбрать более описательное имя. Например, если у сервера есть FQDN и DNS-записи, вы можете назвать этот файл своим доменным именем:
Добавьте следующий блок кода в файл, обязательно заменив your_domain доменом или IP-адресом вашего сервера. Благодаря этому Nginx будет направлять HTTP-трафик сервера в приложение Kibana, которое прослушивает localhost:5601. Кроме того, Nginx теперь будет читать файл htpasswd.users и требовать базовой аутентификации.
Обратите внимание: если вы до конца выполнили мануал по Nginx (из требований), вероятно, вы уже создали такой файл и заполнили его некоторым кодом. В этом случае удалите все существующее содержимое в файле, а потом добавьте такой код
Сохраните и закройте файл.
Включите новую конфигурацию, добавив симлинк в каталог sites-enabled. Если вы создали файл блока server с таким же именем ранее, вам не нужно делать этого.
Проверьте ошибки в файле:
Если в выводе команда сообщает об ошибках, вернитесь в файл и проверьте код, который вы поместили в файл конфигурации. Исправив ошибки, снова запустите команду (в выводе должно быть syntax is ok ) и перезапустите Nginx:
Если вы следовали мануалу по начальной настройке сервера, у вас должен быть включен брандмауэр UFW. Чтобы разрешить подключения к Nginx, нужно настроить брандмауэр, набрав:
Примечание: Если вы следовали мануалу по установке Nginx, вероятно, ранее вы создали правило UFW, разрешающее профиль HTTP Nginx. Поскольку профиль Nginx Full поддерживает трафик HTTP и HTTPS, вы можете просто удалить это правило с помощью следующей команды:
Сервис Kibana теперь доступен по вашему домену или внешнему IP-адресу сервера Elastic Stack. Вы можете проверить страницу состояния сервера Kibana, перейдя по следующему адресу и введя свои учетные данные:
На странице вы увидите информацию об использовании ресурсов и установленных плагинах.
Примечание: В требованиях упоминалось, что сервер нужно защитить с помощью сертификата SSL/TLS. Сейчас самое время сделать это. Инструкции можно найти здесь.
1: Установка и настройка Elasticsearch
Компонентов стека Elastic нет в стандартных репозиториях Ubuntu. Но их можно установить с помощью APT, если добавить исходный список Elastic.
Все пакеты Elastic Stack подписаны с помощью ключа Elasticsearch, чтобы защитить систему от подделки пакетов. Пакеты, прошедшие проверку подлинности с использованием ключа, будут считаться вашим менеджером пакетов доверенными. На этом этапе мы импортируем открытый ключ GPG Elasticsearch и добавим исходный список пакета Elastic для установки Elasticsearch.
Чтобы импортировать ключ GPG, введите команду:
Затем добавьте список Elastic в каталог sources.list.d, где менеджер apt будет искать новые пакеты.
Обновите индекс пакетов:
Теперь просто установите Elasticsearch.
После завершения установки Elasticsearch используйте текстовый редактор, чтобы отредактировать основной конфигурационный файл Elasticsearch, elasticsearch.yml. Здесь мы будем использовать nano:
Примечание: Конфигурационный файл Elasticsearch представлен в формате YAML, а это означает, что отступы очень важны. Убедитесь, что при редактировании этого файла не появились лишние пробелы.
Elasticsearch прослушивает трафик через порт 9200. Нужно ограничить внешний доступ к экземпляру Elasticsearch, чтобы запретить посторонним читать ваши данные или не дать остановить работу кластера Elasticsearch через REST API. Найдите строку network.host, раскомментируйте ее и замените ее значение на localhost, чтобы она выглядела следующим образом:
Сохраните и закройте файл.
Теперь запустите сервис Elasticsearch:
Затем выполните следующую команду, чтобы Elasticsearch запускался при каждой загрузке вашего сервера:
Убедитесь, что сервис Elasticsearch работает, отправив HTTP-запрос:
Вы увидите основную информацию о вашем локальном хосте:
Доступ на уровне записей в типовых конфигурациях. Настройка доступа пользователей с разделением по подразделениям/складам – практический пример
Многим известно, что в современных конфигурациях, разработанных с использованием БСП, имеются широкие возможности для настройки прав доступа. В частности, реализован функционал разделения доступа на уровне записей (RLS). Однако администратор(разработчик) при планировании схемы доступа в организации неминуемо столкнется со сложностями, если временами путается в понятиях: Группы пользователей/Группы доступа/Профили групп доступа.
В статье представлен принцип решения типичной задачи – ограничения прав пользователя на просмотр/изменение информации «чужих» складов и подразделений в конфигурации 1С: Управление торговлей 11.4.
Integration Examples
For each authentication provider, the top portion of your REST API settings.py file should look like this:
INSTALLED_APPS = (
...
# OAuth
'oauth2_provider',
'social_django',
'drf_social_oauth2',
)
TEMPLATES =
{
...
'OPTIONS' {
'context_processors'
...
# OAuth
'social_django.context_processors.backends',
'social_django.context_processors.login_redirect',
],
},
}
REST_FRAMEWORK = {
...
'DEFAULT_AUTHENTICATION_CLASSES' (
...
# OAuth
# 'oauth2_provider.ext.rest_framework.OAuth2Authentication', # django-oauth-toolkit < 1.0.0
'oauth2_provider.contrib.rest_framework.OAuth2Authentication', # django-oauth-toolkit >= 1.0.0
'drf_social_oauth2.authentication.SocialAuthentication',
)
}
Listed below are a few examples of supported backends that can be used for social authentication.
Facebook Example
To use Facebook as the authorization backend of your REST API, your settings.py file should look like this:
AUTHENTICATION_BACKENDS = (
# Others auth providers (e.g. Google, OpenId, etc)
...
# Facebook OAuth2
,
,
# drf_social_oauth2
'drf_social_oauth2.backends.DjangoOAuth2',
# Django
'django.contrib.auth.backends.ModelBackend',
)
# Facebook configuration
= '<your app id goes here>'
= '<your app secret goes here>'
# Define SOCIAL_AUTH_FACEBOOK_SCOPE to get extra permissions from Facebook.
# Email is not sent by default, to get it, you must request the email permission.
= 'email'
= {
'fields' 'id, name, email'
}
Remember to add this new Application in your Django admin (see section “Setting up Application”).
You can test these settings by running the following command:
curl -X POST -d "grant_type=convert_token&client_id=<client_id>&client_secret=<client_secret>&backend=facebook&token=<facebook_token>" http://localhost:8000/auth/convert-token
This request returns the “access_token” that you should use with every HTTP request to your REST API. What is happening
here is that we are converting a third-party access token (<user_access_token>) to an access token to use with your
API and its clients (“access_token”). You should use this token on each and further communications between your
system/application and your api to authenticate each request and avoid authenticating with Facebook every time.
Варианты решения
1. OpenID, https://v8.1c.ru/platforma/openid-autentifikatsiya/, в качестве сервиса аутентификации выделяется отдельная база 1С. настройка сводится к дополнению публикации базы по HTTP, описана в //infostart.ru/1c/articles/1170720/ и настройкой HTTPS для базы с ролью «провайдер OpenID». Устарел, переиспользовать для других сервисов проблематично, на замену ему пришел OpenID connect.
2. OpenID connect https://openid.net/connect/, «is a simple identity layer on top of the OAuth 2.0 protocol» (является простым уровнем идентификации поверх протокола OAuth 2.0). Настраивается на уровне HTTP публикации клиента.
Описание настроек со стороны публикации 1С https://its.1c.ru/db/v8313doc#bookmark:adm:TI000000845, тоже самое на английском (немного урезано) https://support.1ci.com/hc/en-us/sections/360005970179-3-18-9-openidconnect-
Общее описание взаимодействия (в разделе фреш, но думаю подход к локальной платформе схож) https://its.1c.ru/db/fresh#content:19956766:1:issogl1_h1e1l9ae
Общее описание на англ https://1c-dn.com/anticrisis/tips-and-guidelines/how-do-i-configure-openid-connect-authentication/description_OpenID_Connect_authentication/
В разделе ИТС есть примеры настройки для использования с Google, Azure и ЕСИА, https://its.1c.ru/db/metod8dev/content/5972/hdoc .
Статья по использованию сервиса Okta в качестве сервера идентификации //infostart.ru/1c/articles/1435248/.
Все решения используют публичные сервисы, мне интересно запустить в локальном контуре. В качестве сервера идентификации использовал Keykloack https://www.keycloak.org/, потому что по нему есть базовая информация на русском языке, например обзор использования от X5, в том числе по использованию в связке с gatekeeper (тема следующей статьи). По ORY Hydra https://www.ory.sh/hydra/ только на англ. Так же следует отметить что все эти сервисы заточены под «cloud native», использование в средах VM и bare metal вызывает трудности.
Схема
![]()
Управление VM и подобие service discovery описал в статье //infostart.ru/1c/articles/1531329/
Шаг 2. Генерация ссылки для аутентификации
Для генерации ссылки нам потребуется адрес аутентификации и специальные параметры:
$url = 'https://accounts.google.com/o/oauth2/auth';
$params = array(
'redirect_uri' => $redirect_uri,
'response_type' => 'code',
'client_id' => $client_id,
'scope' => 'https://www.googleapis.com/auth/userinfo.email https://www.googleapis.com/auth/userinfo.profile'
);
С помощью функции http_build_query, передав туда массив параметров, получим чередование ключей и значений, как в url адресе. Итак, генерируем ссылку и выводим на экран:
echo $link = '<p><a href="' . $url . '?' . urldecode(http_build_query($params)) . '">Аутентификация через Google</a></p>'; // https://accounts.google.com/o/oauth2/auth?redirect_uri=http://localhost/google-auth&response_type=code&client_id=333937315318-fhpi4i6cp36vp43b7tvipaha7qb48j3r.apps.googleusercontent.com&scope=https://www.googleapis.com/auth/userinfo.email https://www.googleapis.com/auth/userinfo.profile
// Пример. В вашем случае код будет другой http://localhost/google-auth/?code=4/UTIIYyKbcYV8ruGsLsLqeg-tA3hp.Ys3PTfXQxhUYOl05ti8ZT3b110wOewI
Установка схемы аутентификации
Схемы аутентификации по умолчанию могут быть установлены глобально, используя настройку . Например:
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES':
}
Вы также можете установить схему аутентификации для каждого представления или набора представлений, используя представления на основе классов .
from rest_framework.authentication import SessionAuthentication, BasicAuthentication
from rest_framework.permissions import IsAuthenticated
from rest_framework.response import Response
from rest_framework.views import APIView
class ExampleView(APIView):
authentication_classes =
permission_classes =
def get(self, request, format=None):
content = {
'user': unicode(request.user), # `django.contrib.auth.User` instance.
'auth': unicode(request.auth), # None
}
return Response(content)
Или, если вы используете декоратор с представлениями на основе функций.
@api_view()
@authentication_classes()
@permission_classes()
def example_view(request, format=None):
content = {
'user': unicode(request.user), # `django.contrib.auth.User` instance.
'auth': unicode(request.auth), # None
}
return Response(content)
Protecting Docker Services with Traefik’s Basic Auth
Adding the basic authentication that Traefik provides is the simplest way to protect your docker services (Traefik 2).
In our we walked through how to use .htpasswd login credentials and for adding basic authentication using labels (Traefik 2):
For a single service, this can be useful, but I found it quickly became inconvenient and tedious once I had to sign-in to multiple services and for every browser session.
After implementing Traefik forward authentication, I now only need to sign-in once, and by implementing Google OAuth with Traefik I can add 2-factor authentication (2FA), making this method much more secure and convenient than using basic auth.
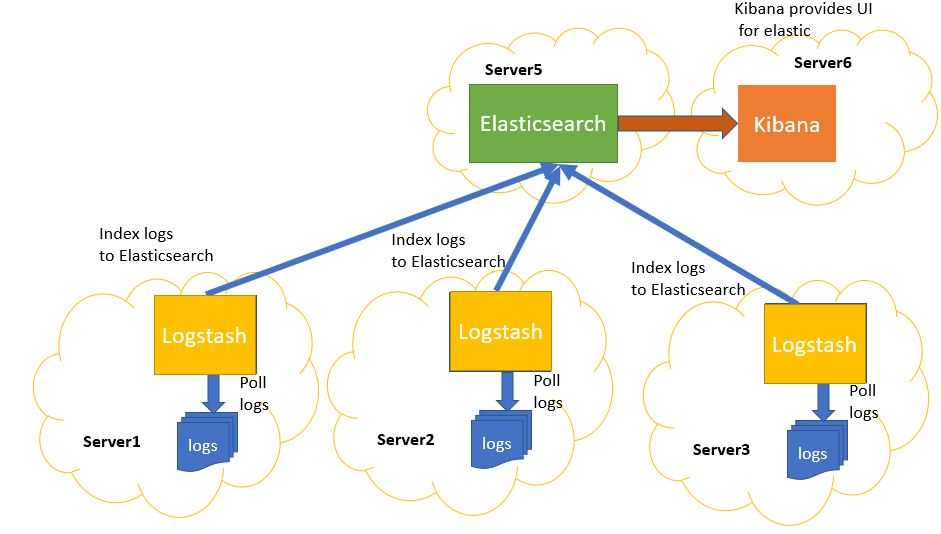
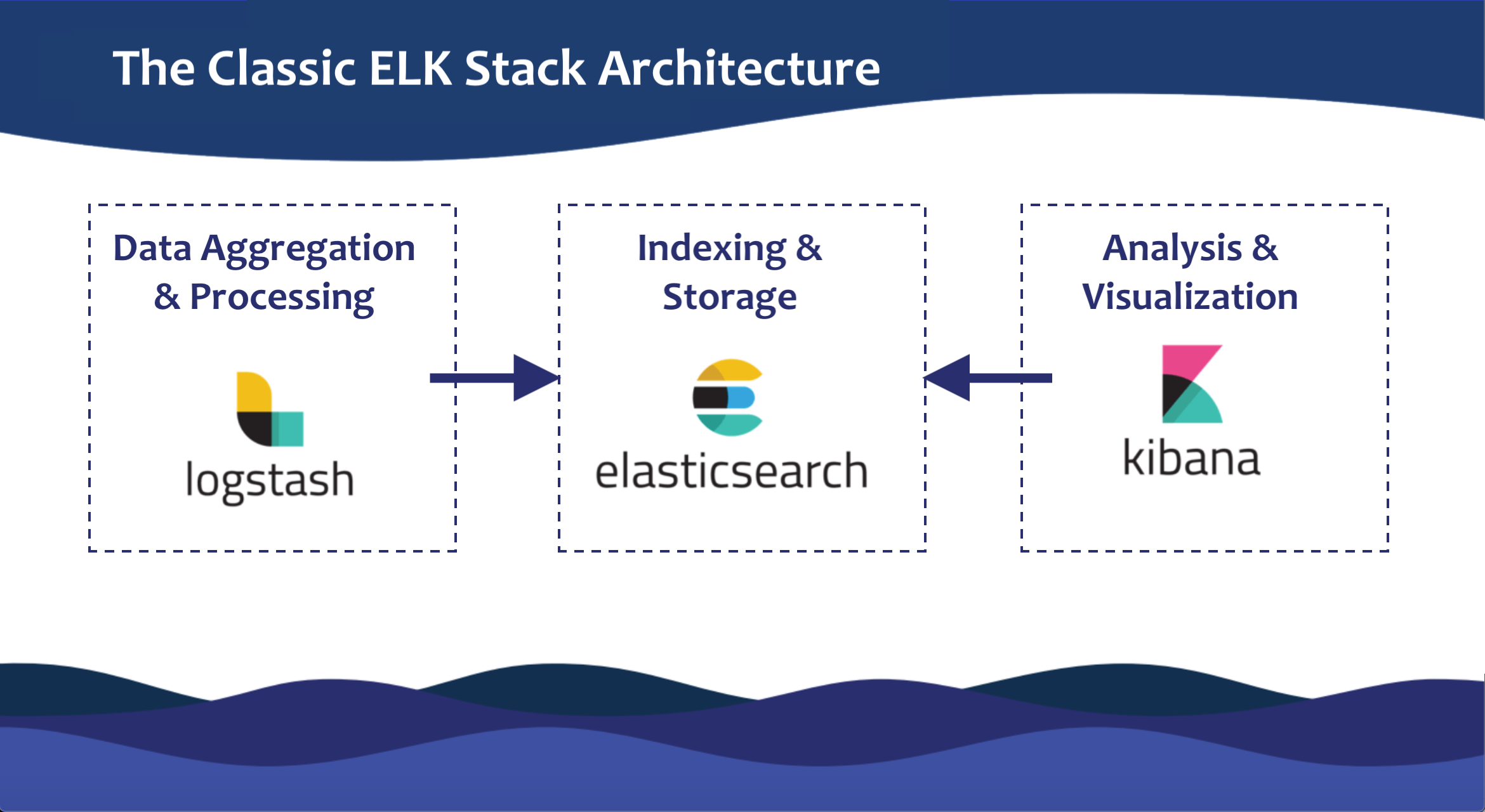
Чем хороши Elasticsearch с Logsatsh и Kibana в Big Data: 5 главных преимуществ
Основными достоинствами ELK-стека считаются следующие :
- Масштабируемость – кластер Elasticsearch (ES) расширяется «на лету» добавлением новых серверов. При этом распределение нагрузки по узлам происходит автоматически.
- Отказоустойчивость — в случае сбоя кластерных узлов данные не потеряются, а будут перераспределены, и поисковая система сама продолжит работу. Операционная стабильность достигается ведением логов на каждое изменение данных в хранилище сразу на нескольких узлах кластера.
- Гибкость поисковых фильтров, включая нечеткий поиск, возможности работы с восточными языками (китайский, японский, корейский) и мультиарендность, когда в рамках одного объекта ES можно динамически организовать несколько различных поисковых систем. Благодаря наличию встроенных анализаторов текста Elasticsearch автоматически выполняет токенизацию, лемматизацию, стемминг и прочие преобразования текста для решения NLP-задач, связанных с поиском данных.
- Управляемость ES по HTTP с помощью JSON-запросов за счет REST API и визуального веб-интерфейса Kibana.
- Универсальность – Logsatsh в потоковом режиме работает одновременно со множеством разных источников данных (СУБД, файлы, системные логи, веб-приложения и пр.), фильтруя и преобразуя их для отправки в хранилище ES. А NoSQL-природа Elasticsearch (отсутствие схемы) позволяет загружать в него JSON-объекты, которые автоматически индексируются и добавляются в базу поиска. Это позволяет ускорить прототипирование поисковых Big Data решений.
5: Дашборды Kibana
Теперь давайте посмотрим, как работает Kibana.
В браузере откройте FQDN или внешний IP сервера Elastic. Введите свои учетные данные из раздела 2, и вы попадете на домашнюю страницу Kibana.
Нажмите Discover в левой панели навигации. На странице Discover выберите предопределенный шаблон индекса filebeat-*, чтобы увидеть данные Filebeat. По умолчанию будут показаны все данные лога за последние 15 минут. Вы увидите гистограмму с событиями и некоторыми сообщениями лога.
Здесь вы можете искать и просматривать логи, а также настраивать дашборды. На данный момент, однако, там не будет много данных, потому что сейчас отображаются только системные логи сервера Elastic Stack.
Используйте левую панель, чтобы перейти на страницу Dashboard и выполнить поиск по Filebeat System. Оказавшись там, вы можете искать примеры дашбордов, которые поставляются с модулем system.
Например, вы можете просмотреть подробную статистику на основе ваших сообщений системного лога или узнать, какие пользователи и когда использовали команду sudo.
У Kibana есть много других функций, таких как построение графиков и фильтров. Исследуйте их самостоятельно.
Добавляем репозиторий Elastic в Ubuntu
Репозиторий Elastic обеспечивает доступ ко всем программам из стека ELK.
Импортируем ключ GPG:
wget -qO — https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add —
| 1 | wget-qO-https//artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add — |
Далее установим пакет apt-transport-https:
sudo apt install apt-transport-https
| 1 | sudo apt install apt-transport-https |
echo «deb https://artifacts.elastic.co/packages/7.x/apt stable main» | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
| 1 | echo»deb https://artifacts.elastic.co/packages/7.x/apt stable main»|sudo teeetcaptsources.list.delastic-7.x.list |
Аутентификация пользователя из разных социальных сетей
Также может встать проблема определения пользователя, если он входит в аккаунт на сайте, используя разные социальные сети, например сегодня он зашёл через ВКонтакте, а завтра воспользуется Google+.
Тогда, чтобы не появлялось несколько аккаунтов одного пользователя, необходимо проверять информацию о пользователе, который аутентифицируется с помощью социальной сети, и если уже он раннее заходил на сайт с помощью другой социальной сети, то связать его аутентификацию с раннее созданным аккаунтом.
Данная проверка включается в Python Social Auth Django одной настройкой.
SOCIAL_AUTH_PIPELINE = (
'social_core.pipeline.social_auth.associate_by_email',
)
Testing the Setup
Now that the installation is done, let’s try out the various functionality.
We will assume for the following examples that the REST API is reachable on .
Retrieve a token for a user using curl:
curl -X POST -d «client_id=&client_secret=&grant_type=password&username=&password=» http://localhost:8000/auth/token
and are the keys generated automatically. you can find in the model Application you created.
-
Refresh token:
curl -X POST -d "grant_type=refresh_token&client_id=<client_id>&client_secret=<client_secret>&refresh_token=<your_refresh_token>" http://localhost:8000/auth/token
-
Exchange an external token for a token linked to your app:
curl -X POST -d "grant_type=convert_token&client_id=<client_id>&client_secret=<client_secret>&backend=<backend>&token=<backend_token>" http://localhost:8000/auth/convert-token
here needs to be replaced by the name of an enabled backend (e.g. «Facebook»). Note that
is a valid backend name, but there is no use to do that here.
is for the token you got from the service utilizing an iOS app for example.
Revoke tokens:
Revoke a single token:
curl -X POST -d «client_id=&client_secret=&token=» http://localhost:8000/auth/revoke-token
Revoke all tokens for a user:
curl -H «Authorization: Bearer » -X POST -d «client_id=» http://localhost:8000/auth/invalidate-sessions
Установка платформы 1С 8.3.20.1363 и более старших версий на RHEL8 и любые другие rpm-based linux. Решение проблемы установки меньших версий 1С8.3 (webkitgtk3) на RHEL 8 / CentOS 8 / Fedora Linux
Начиная с версии платформы 1С 8.3.20.1363 реализована программа установки компонентов системы «1С:Предприятие» для ОС Linux. Теперь любой пользователь Линукс может без проблем установить 1С на свою любимую систему. Попытка установки 1С:Предприятия 8.3 меньших версий, чем 1С 8.3.20.1363 на RedHat Enterprise Linux 8 / CentOS 8 / Fedora не увенчается успехом, произойдет ошибка: Неудовлетворенные зависимости: libwebkitgtk-3.0.so.0()(64bit) нужен для 1c-enterprise-8.3.18.1128-training-8.3.18-1128.x86_64. Конфликт заключается в том, что 1С требует устаревшую версию пакета libwebkitgtk-3.0.so.0()(64bit), запрещенную из-за проблем безопасности, и не может работать с актуальной версией пакета webkit2gtk3. Гуглить в интернете можно долго, хочу поделиться с Вами уже найденным рабочим решением в конце данной статьи.
Выводы
В этом посте мы увидели, как библиотека social-app-django позволяет простым способом реализовать аутентификацию OAuth в наших проектах django. В примере приложения блога мы использовали библиотеку для добавления поддержки использования учетных записей Google для аутентификации пользователей приложения. Точно так же мы могли бы использовать другие бэкэнды для добавления аутентификации с помощью твиттера, github, facebook и т. Д.
Наконец, я хотел бы подчеркнуть, что эта библиотека также работает с различными средами Python, что позволяет нам осуществлять аутентификацию так же легко, как мы это делали с django.





