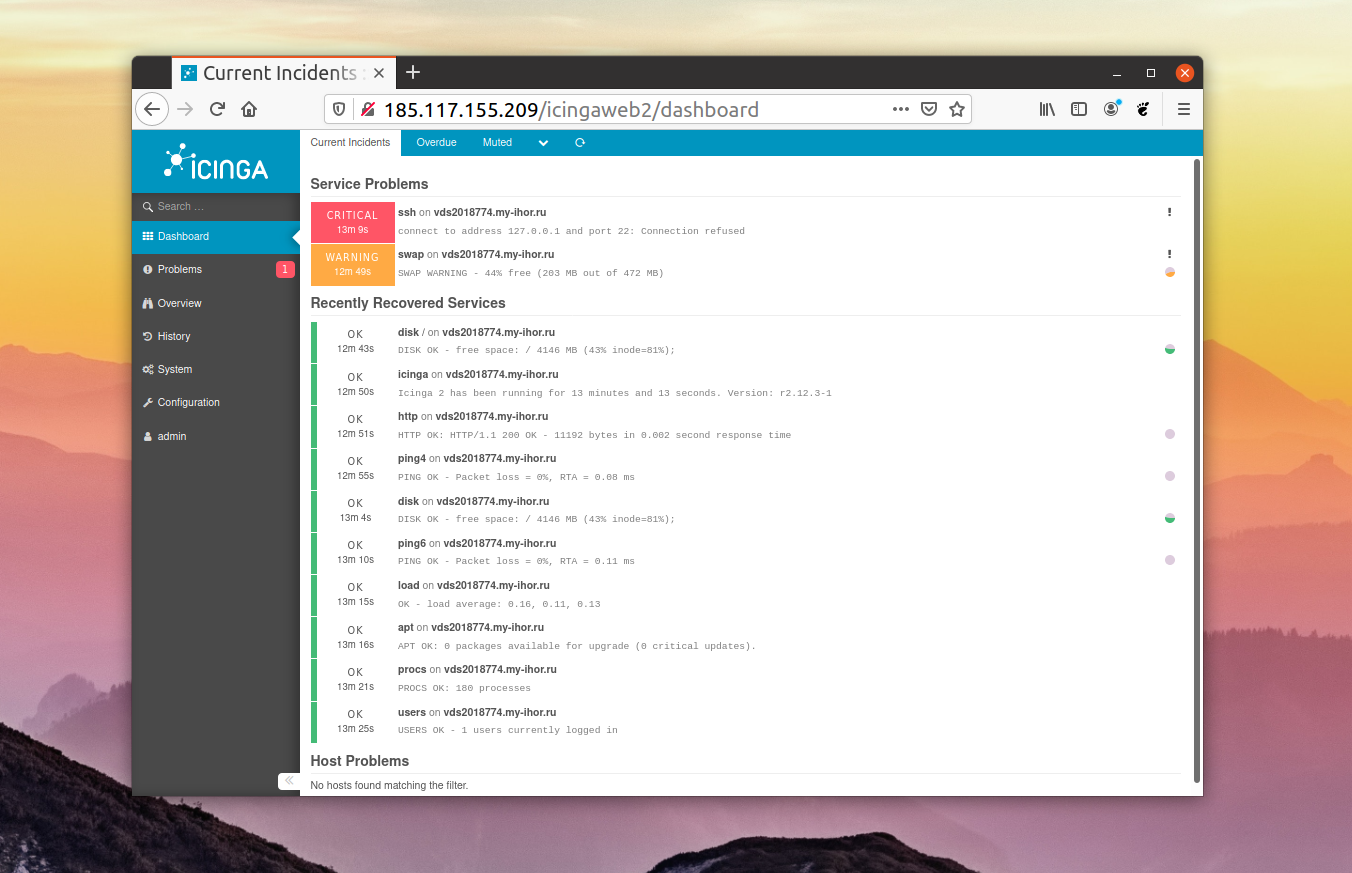
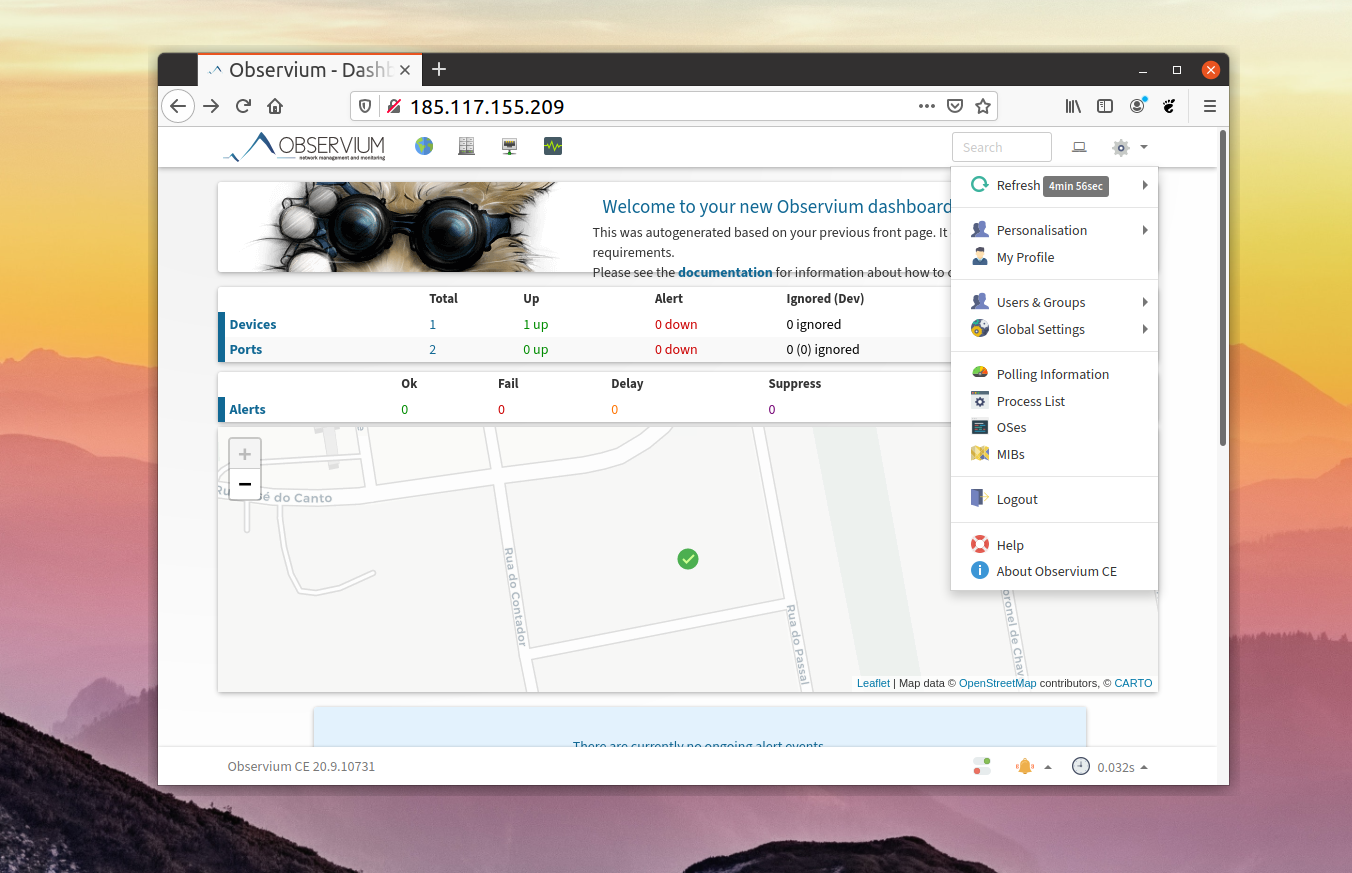
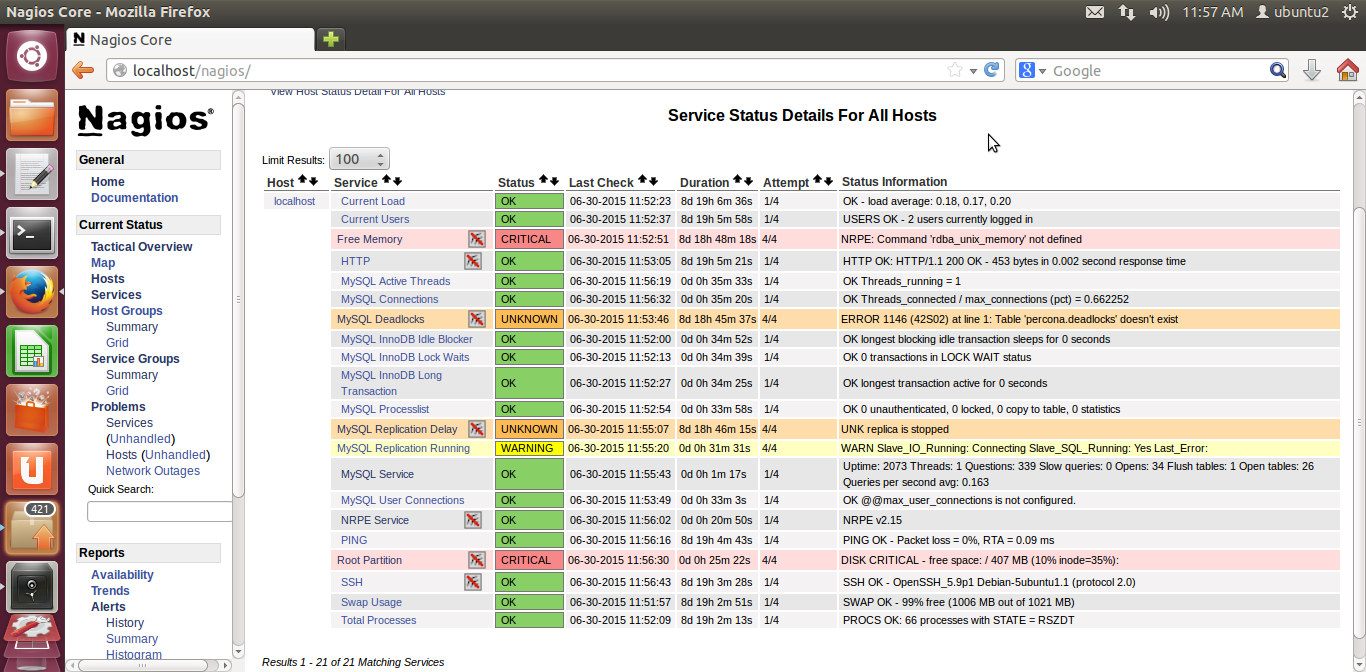
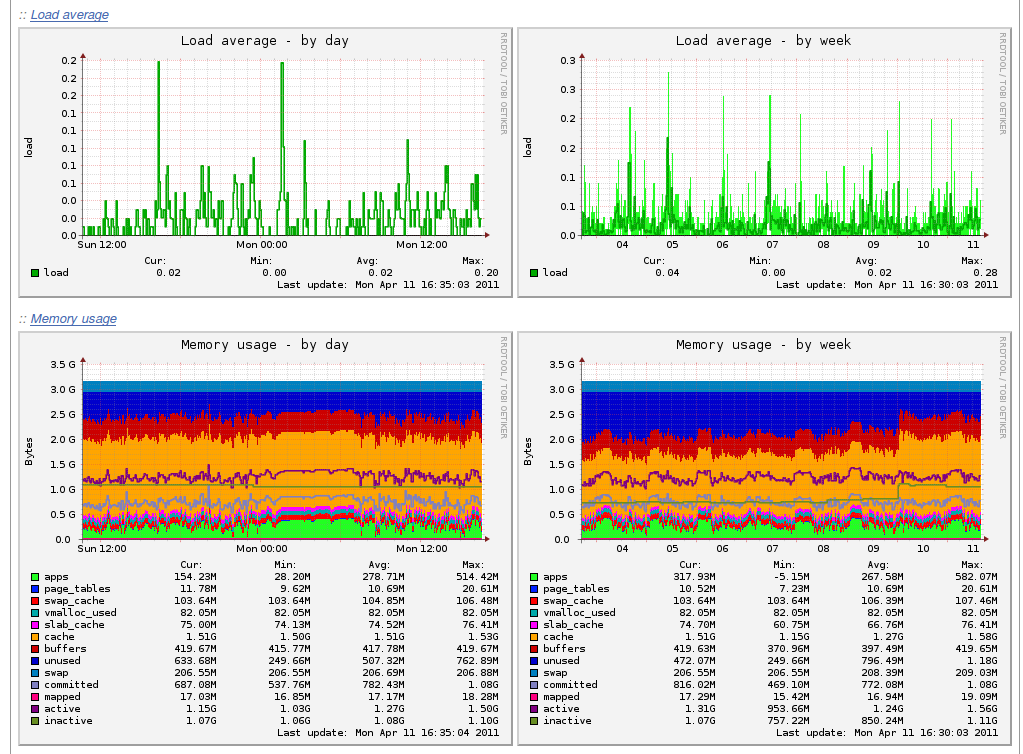
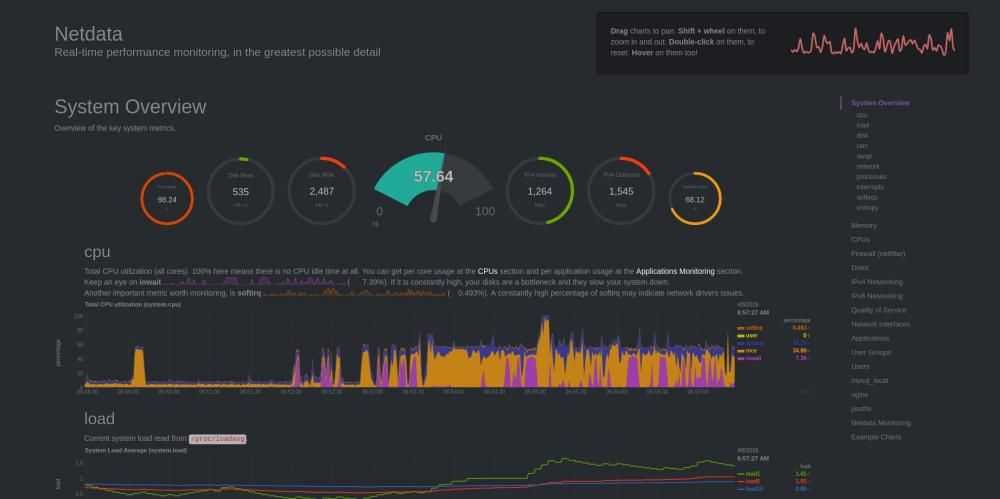
#9. Netdata
![]()
Ключевые особенности:
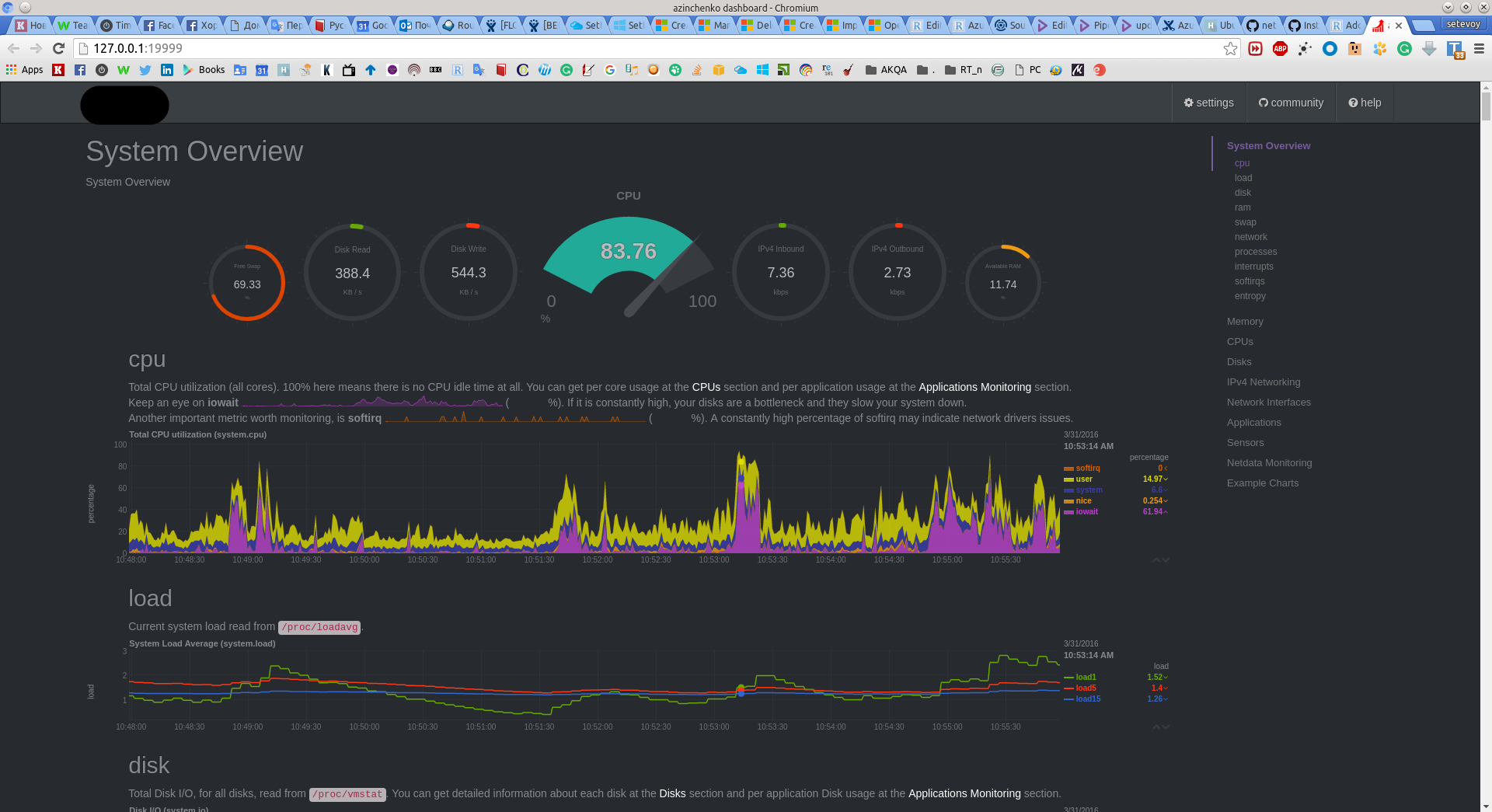
Netdata – это распределенный мониторинг производительности и работоспособности систем.
Используя Netdata, мы можем отслеживать:
- Сервер
- Системные приложения
- Контейнеры
- Веб-приложения
- Виртуальные машины
- Базы данных
- Устройства IOT.
Мы можем контролировать 1000 устройств с помощью Netdata.
Нам нужно будет установить плагин python для мониторинга баз данных PostgreSQL.
Преимущества:
- Netdata представляет собой инструмент мониторинга с открытым исходным кодом.
- Netdata также может контролировать определенные устройства SNMP.
- Netdata имеет хорошие интерактивные веб-дашборды.
- Netdata работает быстро и эффективно.
- Netdata имеет открытый исходный код и не зависит от платформы.
- Использование ОЗУ, мониторинг оптимизации ядра становится очень простым с помощью Netdata.
см. также:
Полные комплекты для обнаружения недостатков в Linux
Phoronix Test Suite, полный набор, который поможет нам
Если вы хотите сделать полный диагноз вашего компьютера или его компонентов в Linux, это более чем адекватное решение. Для начала скажем вам, что это программное решение, с помощью которого вы можете сделать это из этого та же ссылка .
Фактически, здесь мы говорим о решении, которое объединяет серию тестов, которые помогут вам проанализировать состояние множества компонентов на ПК
Таким образом, из одного окна мы получим информацию об элементах важности процессора компьютера, графического процессора, оперативной памяти, дисковых накопителей и т. Д
Кроме того, когда мы его используем, мы находим серию привлекательных графиков, которые помогут Мы оцениваем производительность этих компонентов с первого взгляда.
Конечно, мы должны иметь в виду, что это программа который сам по себе потребляет немного больше системных ресурсов, чем другие ранее использовавшиеся решения. Причина этого в том, что эта программа якобы более комплексна и эффективна при устранении неполадок в Linux.
GTKStressTesting, анализирует все компоненты ПК в одном окне
Здесь мы находим еще одну альтернативу, которую мы могли бы рассматривать как полные комплекты, чтобы охватить то, что мы здесь ищем. Фактически мы имеем в виду GTKStressTesting, полное решение, которое вы можете скачать от эту ссылку и это будет очень полезно для обнаружения проблем в Linux.
Кроме того, мы достигаем всего этого с помощью интуитивно понятного и привлекательного интерфейс пользователя это покажет нам все, что мы ищем в этом отношении. Кроме того, все это позволит нам обойтись без терминала, который, как мы видели ранее, является обычным элементом для такого типа задач. На самом деле программа выполняет серию тестов производительности для измерения поведения компонентов и обнаружения проблем в Linux. В свою очередь, для обнаружения возможных проблем он также может служить информационным инструментом с большим объемом данных, показанных здесь.
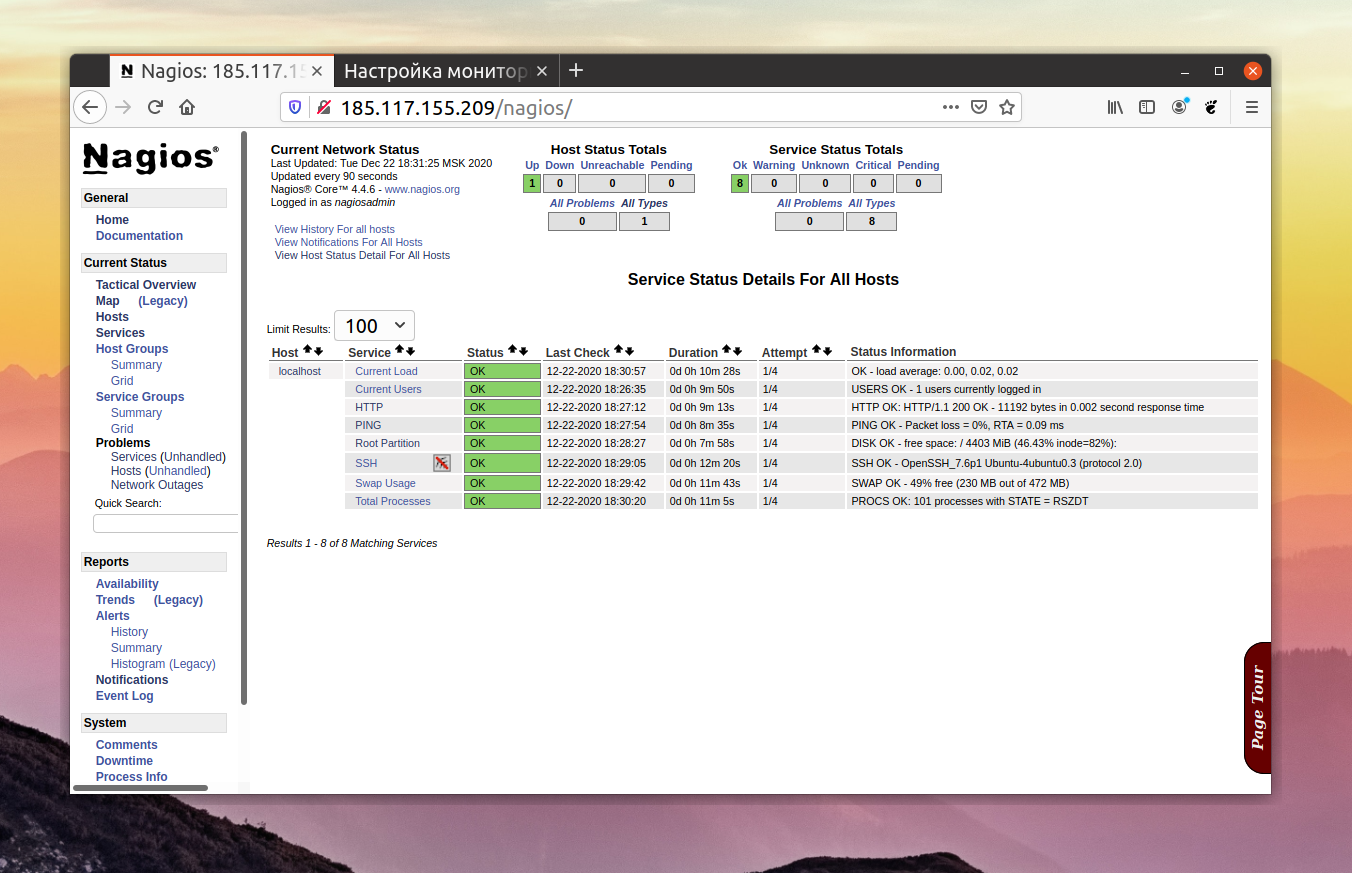
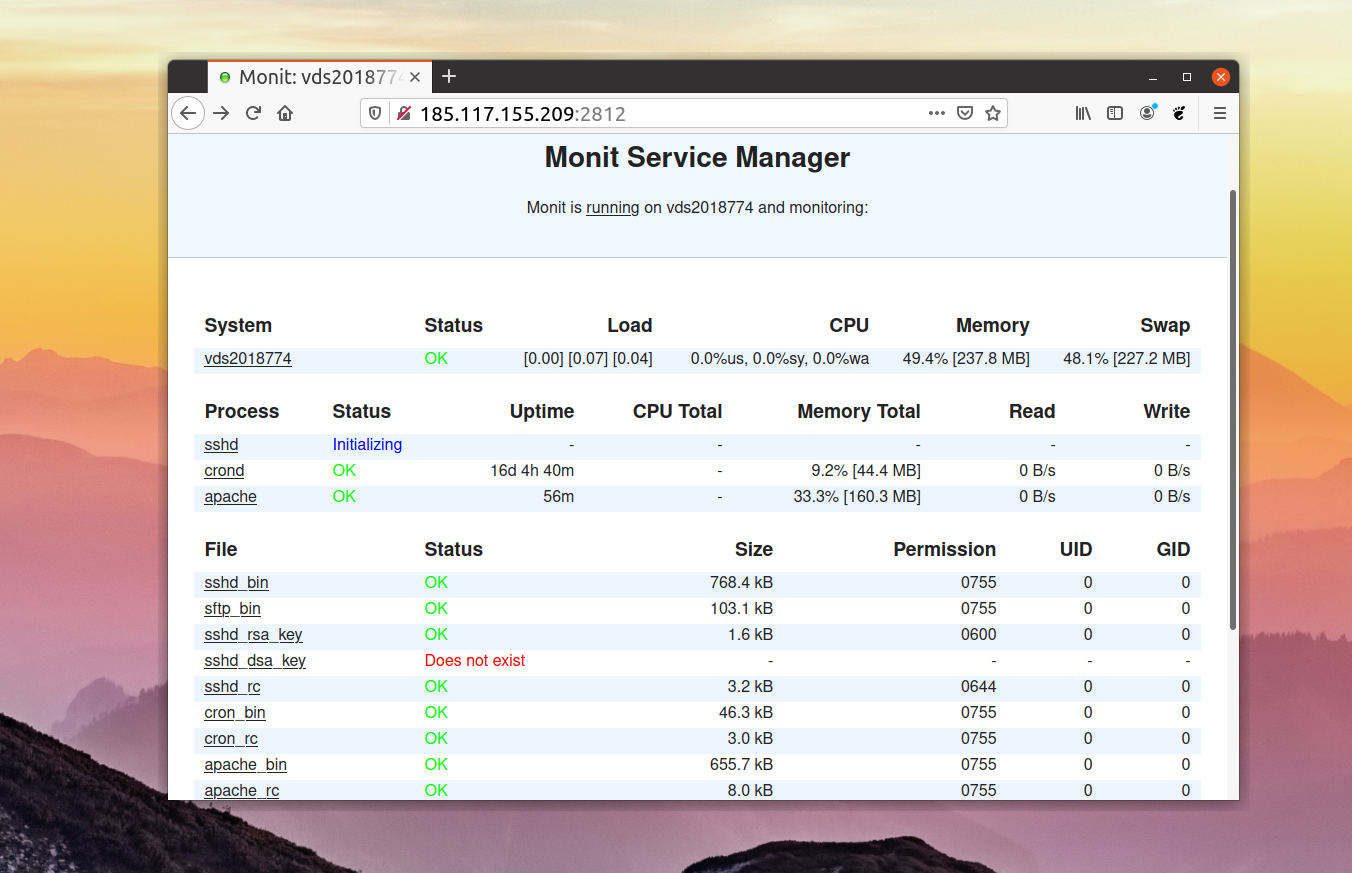
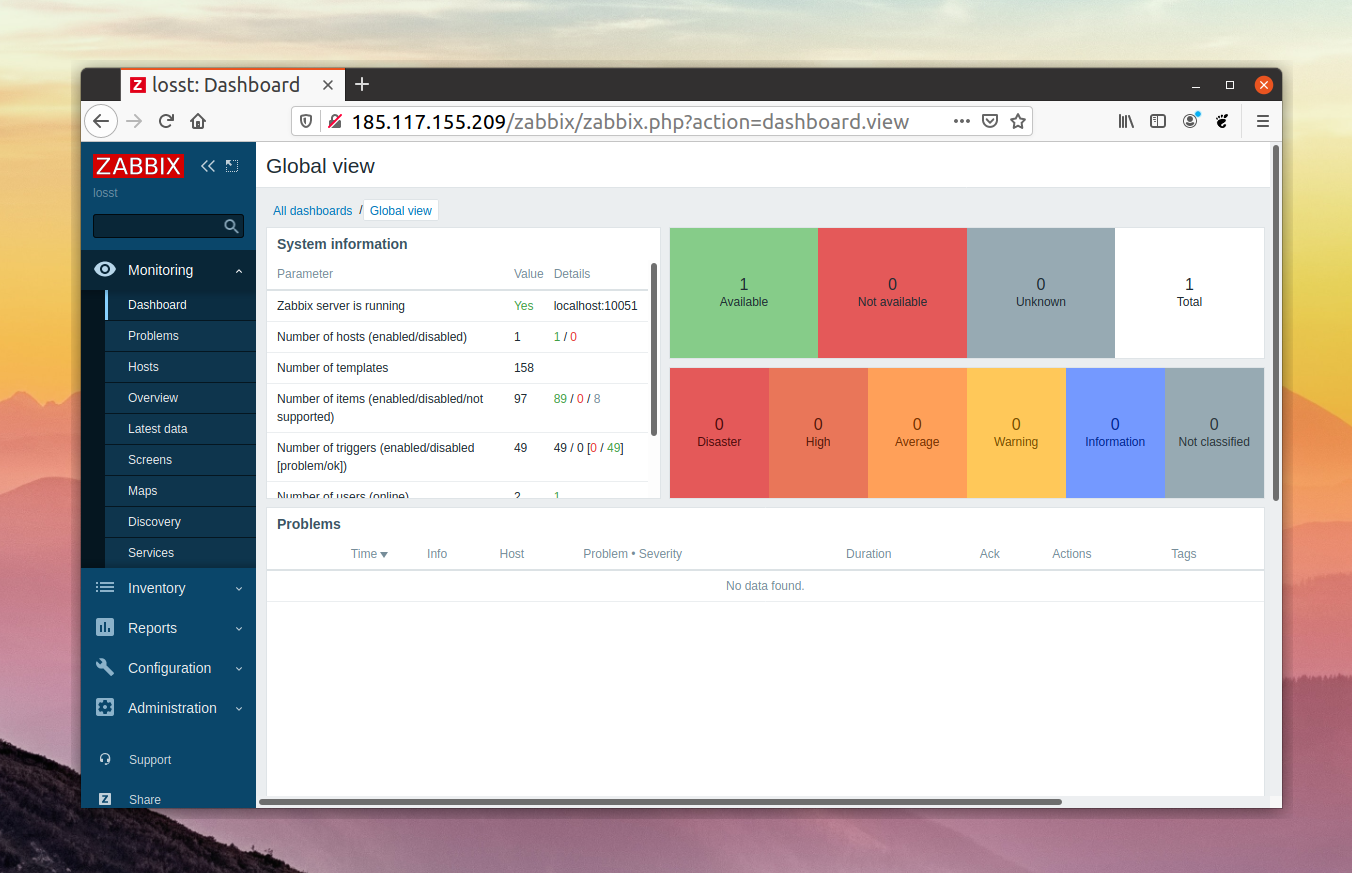
Глава 19. Мониторинг использования ресурсов системы
Процесс мониторинга использования ресурсов системы заключается в сборе информации об использовании ресурсов памяти, центрального процессора, сети и устройств для хранения данных. Вы должны начать мониторинг использования ресурсов вашей системы как можно быстрее для того, чтобы иметь возможность установления соответствующих . Убедитесь в том, что вы установили все базовые показатели использования ресурсов вашей системы! Эти базовые показатели важны, так как они позволят вам обнаружить последовательный или внезапный рост и, соответственно, последовательное (или внезапное) . Эта информация позволяет планировать масштабирование системы с целью расширения или сокращения доступных ресурсов.
Давайте рассмотрим некоторые инструменты, которые могут использоваться для мониторинга использования ресурсов системы помимо рассмотренных ранее команд , , и .
#11. Pandora FMS
Ключевые особенности:
- Pandora FMS расшифровывается как Pandora Flexible Monitoring Solution.
- Pandora FMS – это инструмент мониторинга ИТ-инфраструктуры в единой консоли.
- Элементы Pandora FMS состоят из консоли, базы данных, серверов, агентов.
Используя Pandora FMS, мы можем отслеживать:
- Сеть
- Логи
- Базы данных
- Облака
- Приложения
- Серверы
- IPAM
- SAP
- Интернет вещей
Он может выполнять как удаленный мониторинг, так и мониторинг на основе агентов, установленных на серверах.
Преимущества:
- Pandora FMS имеет версию с открытым исходным кодом.
- У него также есть также версия Enterprise, которая используется многими ИТ-компаниями.
- Версия Pandora FMS с открытым исходным кодом и корпоративная версия регулярно обновляются каждый месяц.
- Имеет прямой доступ с консоли.
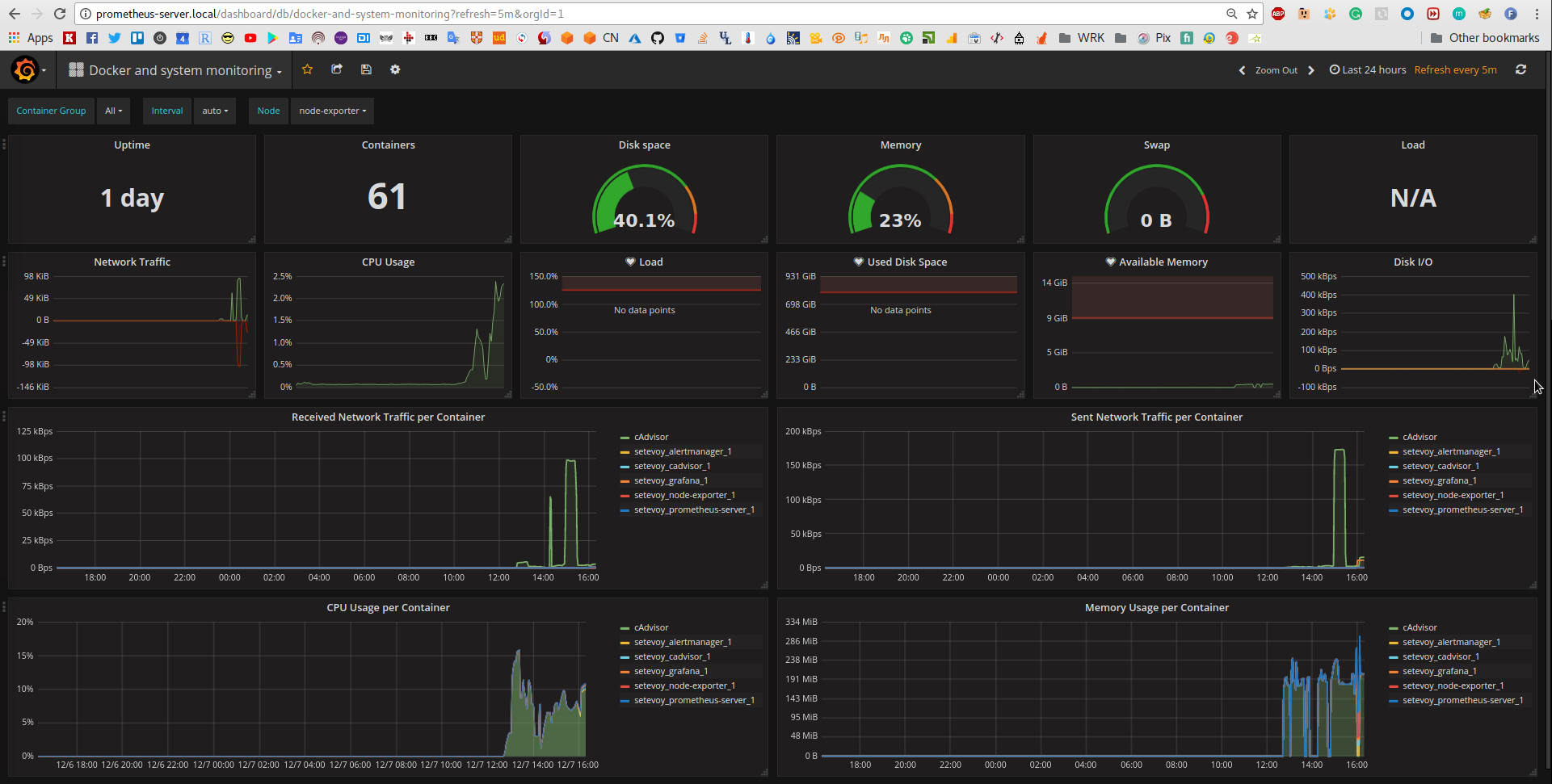
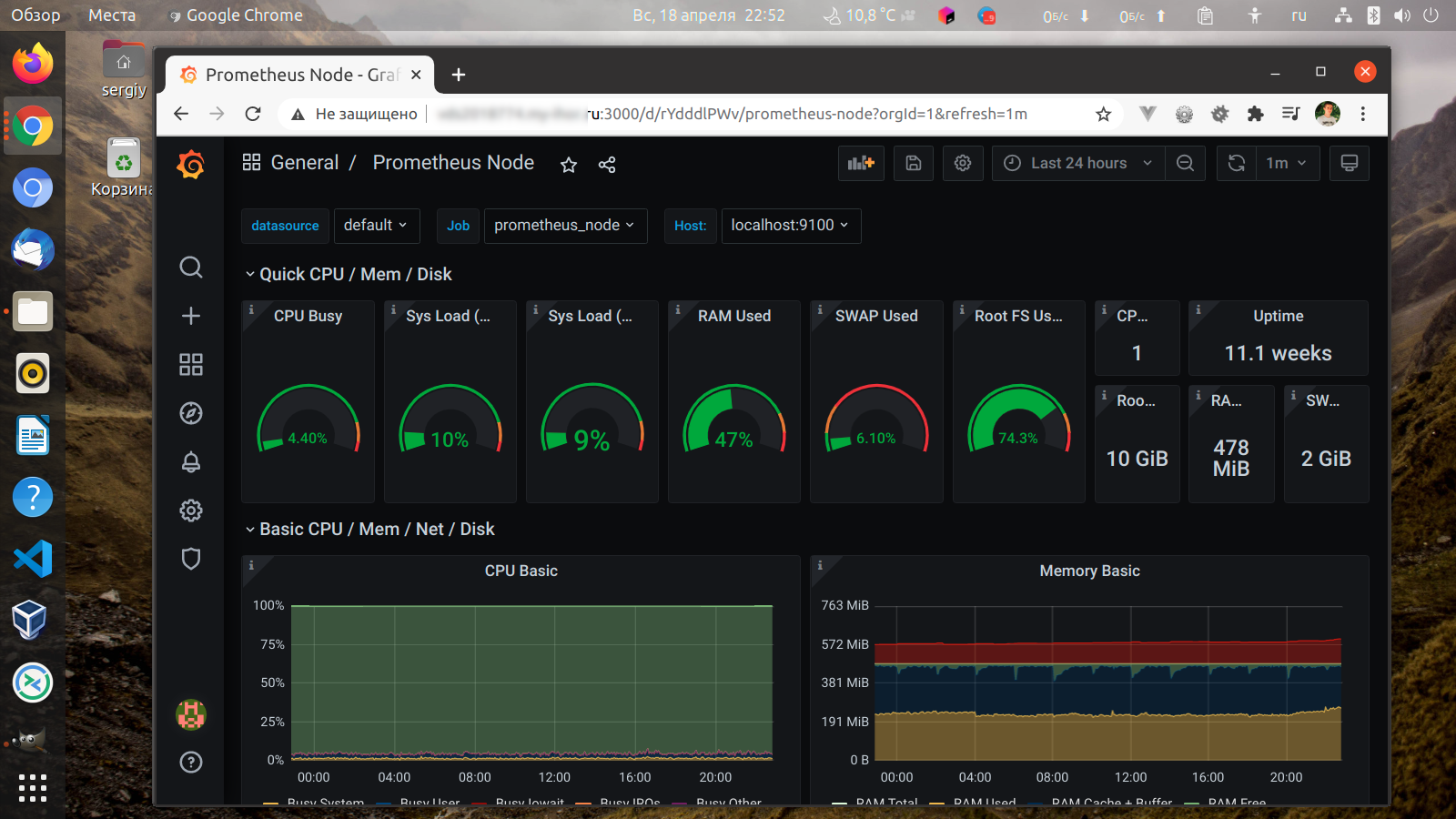
Мы рассмотрели инструменты мониторинга с открытым исходным кодом для Linux-Prometheus, Grafana, Elastic search, Nagios Core, Zabbix, Cacti, Icinga, MRTG, Netdata, Sensu, Pandora FMS.
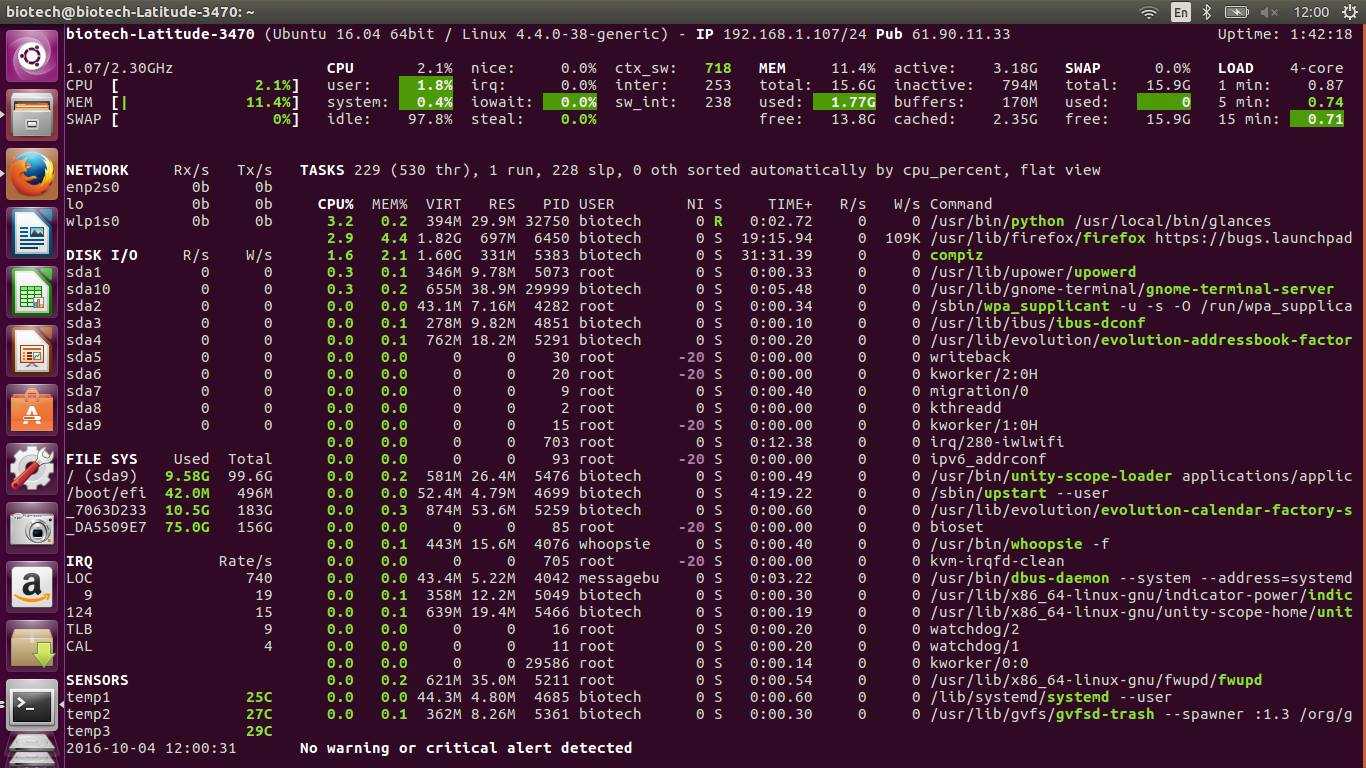
Команда mpstat — Загруженность нескольких CPU
Если в системе больше одного процессора, то команда mpstat покажет нагрузку на каждый их них, начиная с нулевого.
mpstat -P ALL
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009 06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04 06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31 06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93 06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00 06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80 06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91 06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98 06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75 06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
№ 8: sar – сбор и выдача данных о системной активности
Команда sar используется для сбора информации о системной активности и выдачи ее в виде отчета или ее сохранения. Чтобы увидеть значение считчика сетевой активности, введите:
# sar -n DEV | more
Для того, чтобы увидеть значения счетчиков сетевой активности, начиная с 24-го:
# sar -n DEV -f /var/log/sa/sa24 | more
С помощью команды sar Вы можете также выдавать данные в режиме реального времени:
# sar 4 5
Пример вывода данных:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009 06:45:12 PM CPU %user %nice %system %iowait %steal %idle 06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78 06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52 06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78 06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22 06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19 Average: all 2.02 0.00 0.27 0.01 0.00 97.70
Ссылки:
Приступая к работе с dstat
Теперь dstat должен быть установлен и готов отображать статистику производительности вашей системы.
В своей простейшей форме dstat может быть вызван с помощью команды:
# dstat
![]()
start dstat
Так же можно вызвать еще одним способом:
# dstat -c --top-cpu -d --top-bio --top-latency
![]()
запуск dstat в линукс
Чтобы направить вывод в файл CSV для последующего использования мы можем выполнить следующую команду:
# dstat --output /tmp/sampleoutput.csv -cdn
![]()
запуск dstat в Ubuntu
Файл можно посмотреть перейдя в директорию /tmp/sampleoutput.csv
![]()
экспорт данных dstat в CSV
Dstat опции:
-c, –cpu
выведет процессорую статистику
-C 0,3
общая инфо включает CPU0, CPU3 и общей
-d,–disk
позволит показать статистику дисков
-D
всего, HDA,HDA и общее
-g, —page
позволяют показать статистику страницы
-i,—int
включить статистику прерываний
-I 5, eth2 включают int5 и прерывание используется eth2
-l, —load позволяют увидеть статистику нагрузки
-m,-mem
включить статистику памяти
-n,–net
позволяют видеть сетевую статистику
-N eth1
всего,включают eth1, общее
-p,—proc
позволит увидеть статистику процесса
-r,–io
включить IO статистику (запросы ввода / вывод завершен)
-s, —swap
позволяют увидеть статистику подкачки
-S swap1
всего, включают swap1, общей
-t, —time
включения вывода даты / времени
-T,—epoch
включить счетчик времени (секунд с начала эпохи)
-y,—sys
включить статистику системы
—aio
включить статистику aio
—fs, —filesystem
включить статистику fs
—ipc
включить статистику ipc
—lock
включить статистику lock
—raw
включить статистику raw
—socket
включить статистику socket
—tcp
включить статистику tcp
—udp
включить статистику udp
—unix
включить статистику unix
—vm
включить статистику vm
—plugin-name
включить плагины для плагинного имени
—list
Лист всех доступных плагинов
Для получения полного списка всех доступных опций, выполните команду:
# dstat --help
Dstat инструмент для мониторинга в Linux очень прост и очень полезный. На этом я завершу данную тему.
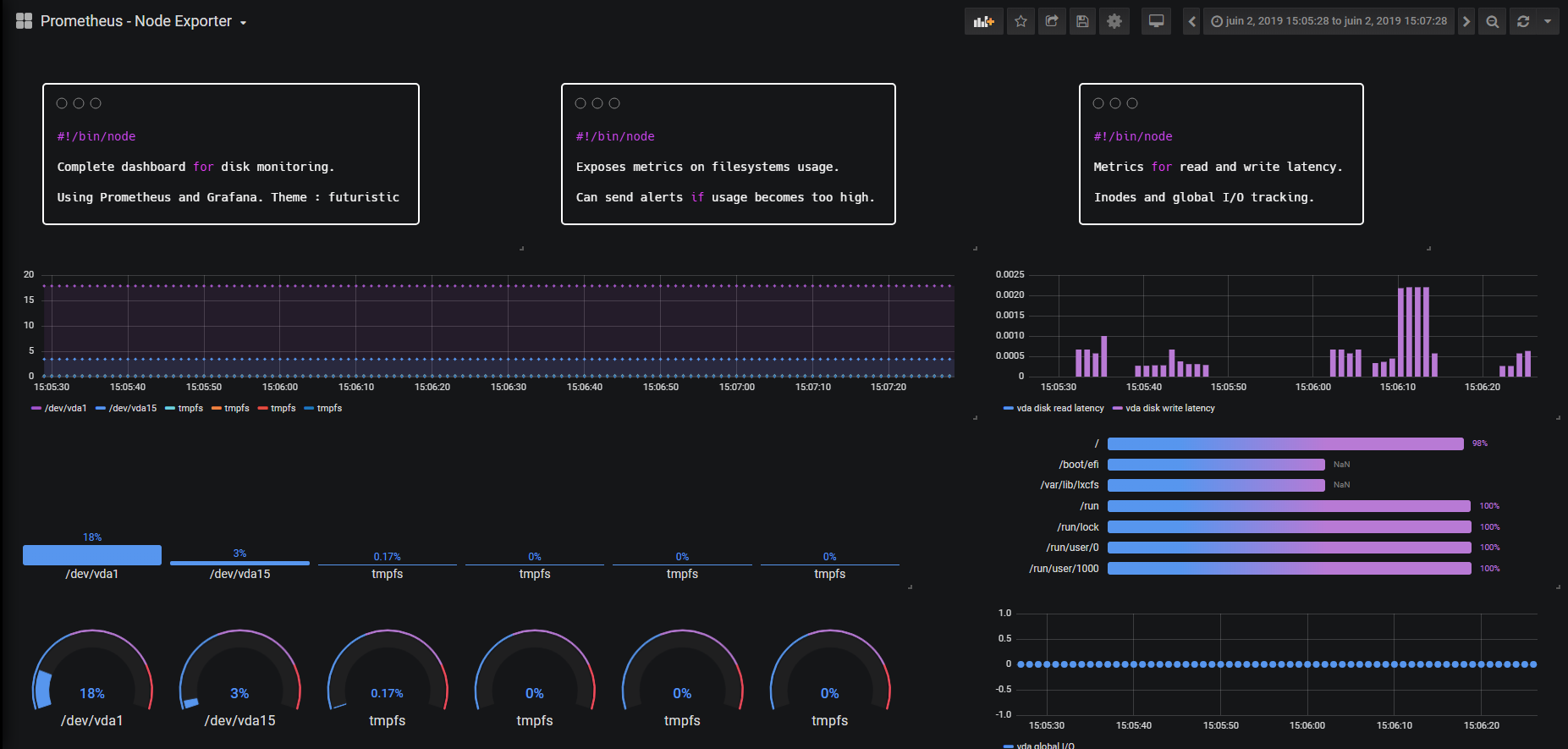
mpstat — Статистика процессоров
1. Используя команду mpstat без какой-либо опции, вы увидите глобальную среднюю активность всех процессоров.
~ $ mpstat Linux 3.11.0-23-generic (tecmint.com) четверг, 4 сентября 2014 г. _i686_ (2 процессора) 12:23:57 IST CPU% usr% nice% sys% iowait% irq% soft% steal% guest% gnice % простаивает 12:23:57 IST все 37, 35 0, 01 4, 72 2, 96 0, 00 0, 07 0, 00 0, 00 0, 00 54, 88
2. Используя mpstat с опцией ‘ -P ‘ (Укажите номер процессора) и ‘ALL’, будет отображаться статистика обо всех процессорах по одному, начиная с 0. 0 будет первым.
~ $ mpstat -P ALL Linux 3.11.0-23-generic (tecmint.com) четверг, 4 сентября 2014 г. _i686_ (2 процессора) 12:29:26 IST CPU% usr% nice% sys% iowait% irq% soft% steal% guest% gnice% idle 12:29:26 IST all 37, 33 0, 01 4, 57 2, 58 0, 00 0, 07 0, 00 0, 00 0, 00 55, 44 12:29:26 IST 0 37, 90 0, 01 4, 96 2, 62 0, 00 0, 03 0, 00 0, 00 0, 00 54, 48 12:29:26 IST 1 36, 75 0, 01 4, 19 2, 54 0, 00 0, 11 0, 00 0, 00 0, 00 56, 40
3. Чтобы отобразить статистику по N количеству итераций после интервала n секунд со средним значением для каждого процессора, используйте следующую команду.
~ $ mpstat -P ALL 2 5 Linux 3.11.0-23-generic (tecmint.com) четверг, 4 сентября 2014 г. _i686_ (2 процессора) 12:36:21 IST CPU% usr% nice% sys% iowait% irq% soft% украсть% гость% gnice% простаивает 12:36:23 IST все 53, 38 0, 00 2, 26 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 44, 36 12:36:23 IST 0 46, 23 0, 00 1, 51 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 52, 26 12:36:23 IST 1 60, 80 0, 00 3, 02 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 36, 18 12:36:23 IST CPU% usr% nice% sys% iowait% irq% soft% steal% guest% gnice% idle 12:36:25 IST all 34.18 0.00 2.30 0.00 0.00 0.00 0.00 0.00 0, 00 63, 52 12:36:25 IST 0 31, 63 0, 00 1, 53 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 66, 84 12:36:25 IST 1 36, 73 0, 00 2, 55 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 60, 71 12:36:25 IST CPU% usr% nice% sys% iowait% irq% soft% steal% guest% gnice% idle 12:36:27 IST all 33.42 0.00 5.06 0.25 0.00 0.25 0.00 0.00 0.00 0.00 61.01 12:36:27 IST 0 34.34 0.00 4.04 0.00 0.00 0.00 0.00 0.00 0.00 0.00 61.62 12:36 : 27 IST 1 32, 82 0, 00 6, 15 0, 51 0, 00 0, 00 0, 00 0, 00 0, 00 60, 51
4. Опция « I » выведет общее количество статистики прерываний по каждому процессору.
~ $ mpstat -I Linux 3.11.0-23-generic (tecmint.com) четверг, 4 сентября 2014 г. _i686_ (2 процессора) 12:39:56 IST CPU intr / s 12:39:56 IST all 651.04 12:39:56 IST CPU 0 / с 1 / с 6 / с 8 / с 9 / с 12 / с 16 / с 17 / с 20 / с 21 / с 22 / с 23 / с 45 / с 46 / с 47 / с NMI / с LOC / s SPU / s PMI / s IWI / s RTR / s RES / s CAL / s TLB / s TRM / s THR / s MCE / s MCP / s ERR / s MIS / s 12:39:56 IST 0 76.27 1, 73 0, 00 0, 00 0, 42 0, 33 0, 00 0, 06 11, 46 0, 00 0, 00 0, 01 7, 62 1, 87 0, 05 0, 33 182, 26 0, 00 0, 33 3, 03 0, 00 22, 66 0, 16 5, 14 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 12:39:56 IST 1 70, 88 1, 44 0, 00 0, 00 0, 41 0, 33 0, 00 27, 91 10, 33 0, 00 0, 00 0, 01 7, 27 1, 79 0, 05 0, 32 184, 11 0, 00 0, 32 5, 17 0, 00 22, 09 0, 13 4, 73 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 12:39:56 IST CPU HI / s ТАЙМЕР / с NET_TX / с NET_RX / с BLOCK / с BLOCK_IOPOLL / с ЗАДАЧА / с SCHED / с HRTIMER / с RCU / s 12:39:56 IST 0 0, 00 116, 49 0, 05 0, 27 7, 33 0, 00 1, 22 10, 44 0, 13 37, 47 12:39:56 IST 1 0, 00 111, 65 0, 05 0, 41 7, 07 0, 00 56, 36 9, 97 0, 13 41, 38
5. Получить всю вышеуказанную информацию в одной команде, то есть эквивалентно « -u -I ALL -p ALL ».
~ $ mpstat -A Linux 3.11.0-23-generic (tecmint.com) четверг, 4 сентября 2014 г. _i686_ (2 процессора) 12:41:39 IST CPU% usr% nice% sys% iowait% irq% soft% steal% guest % gnice% бездействует 12:41:39 IST все 38, 70 0, 01 4, 47 2, 01 0, 00 0, 06 0, 00 0, 00 0, 00 54, 76 12:41:39 IST 0 39, 15 4, 82 2, 05 0, 00 0, 02 0, 00 0, 00 0, 00 53, 95 12:41:39 IST 1 38, 24 0, 01 4, 12, 98 0, 00 0, 09 0, 00 0, 00 0, 00 55, 57 12:41:39 IST CPU intr / s 12:41:39 IST all 651.73 12:41:39 IST 0 173.16 12:41:39 IST 1 225, 89 12:41:39 IST CPU 0 / s 1 / с 6 / с 8 / с 9 / с 12 / с 16 / с 17 / с 20 / с 21 / с 22 / с 23 / с 45 / с 46 / с 47 / с NMI / с LOC / с SPU / с PMI / с IWI / с RTR / с RES / с CAL / с TLB / с TRM / с THR / с MCE / с MCP / s ERR / с MIS / с 12:41:39 IST 0 76, 04 1, 77 0, 00 0, 00 0, 4 0, 41 0, 36 0, 00 0, 06 11, 60 0, 00 0, 00 0, 01 7, 42 1, 83 0, 05 0, 34 182, 89 0, 00 0, 34 2, 97 0, 00 22, 69 0, 16 5, 22 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 0, 0041: 41 0, 00 I 0, 40 0, 00 1, 48 0, 00 0, 00 0, 40 0, 36 0, 00 27, 47 10, 46 0, 00 0, 00 0, 01 7, 08 1, 75 0, 05 0, 32 184, 83 0, 00 0, 32 5, 10 0, 00 22, 19 0, 13 4, 91 0, 00 0, 00 0, 00 0, 00 0, 00 0, 00 12:41:39 IST C PU HI / s ТАЙМЕР / с NET_TX / с NET_RX / с BLOCK / с BLOCK_IOPOLL / с ЗАДАЧА / с SCHED / с HRTIMER / с RCU / с 12:41:39 IST 0 0, 00 116, 96 0, 05 0, 26 7, 12 0, 00 1, 24 10, 42 0, 12 36, 99 12: 41:39 IST 1 0, 00 112, 25 0, 05 0, 40 6, 88 0, 00 55, 05 9, 93 0, 13 41.20
KDE System Guard — системы и отчеты Linux в режиме реального времени
KSysguard — это приложение для мониторинга системы для рабочего стола KDE. Его можно запускать через сессию ssh. Оно обеспечивает мониторинг локальных и удаленных хостов. Графический интерфейс использует так называемые датчики для извлечения отображаемой информации. Датчик может возвращать простые значения или более сложную информацию, например, таблицы. Для каждого типа информации предоставляется один или несколько дисплеев. Дисплеи организованы в виде листов, которые можно сохранять и загружать независимо друг от друга. Таким образом, KSysguard — это не только простой диспетчер задач, но и очень мощный инструмент для управления большими пулами серверов.
Средняя температура по больнице
Об одной из самых базовых метрик часто рассказывают на первых же занятиях по Linux даже в школах. Это всем известный uptime, он же время непрерывной работы системы с момента последней перезагрузки. Утилита для его измерения называется точно так же и выдает целую строчку полезной информации:
|
1 |
$uptime 1343up9days,923,2users,load averages0.010.040.01 |
В начале идет текущее время, потом собственно аптайм, потом количество залогинившихся в систему пользователей, а дальше показатели load average, те самые таинственные три цифры, о которых часто спрашивают на собеседованиях. Кстати, есть еще команда
w, которая выдает ту же самую строчку плюс чуть более подробную информацию о том, что каждый из юзеров делает.
Информацию об uptime можно посмотреть напрямую в
/proc, только в таком случае она будет слегка менее интерпретируемой:
|
1 |
$cat/proc/uptime 5348365.915172891.73 |
Здесь первое число — это сколько секунд система работала с момента старта, а второе — сколько из них она работала «вхолостую», не делая толком ничего.
Но давай остановимся подробнее на load average, ибо тут есть один подвох. Еще раз взглянем на числа, в этот раз воспользовавшись интерфейсом
/proc (числа те же самые, различается только способ):
|
1 |
$cat/proc/loadavg 0.010.040.011/217727278 |
Тебе не составит труда найти информацию, что в UNIX-системах эти числа означают усредненное количество процессов, стоящих в очереди за ресурсами CPU, причем взятые в трех временных периодах до текущего момента: 1 минуту, 5 минут и 15 минут назад. Дальше, четвертая колонка — это разделенные слешем количество процессов, выполняющихся в системе сейчас, и количество процессов в системе вообще, а пятая — последний выданный системой PID. Так где же здесь подвох?
А подвох в том, что это верно для UNIX, но не для Linux. С виду все нормально: если числа уменьшаются — нагрузка снижается, если увеличиваются — растет. Если ноль — система простаивает, если равна числу ядер — значит, загрузка под 100%, если в выводе десятки и сотни… стоп, что? Формально Linux учитывает не только процессы в статусе RUNNING, но и процессы, находящиеся в UNINTERRUPTIBLE_SLEEP, то есть висящие на вызовах в ядро. Это значит, что на эти числа могут также оказывать влияние I/O-операции, да и далеко не только они, потому что вызовы в ядро не ограничиваются I/O. Пожалуй, я здесь остановлюсь, а за подробностями рекомендую проследовать вот в эти две статьи: «Как считается Load Average», «Load Average в Linux: разгадка тайны».
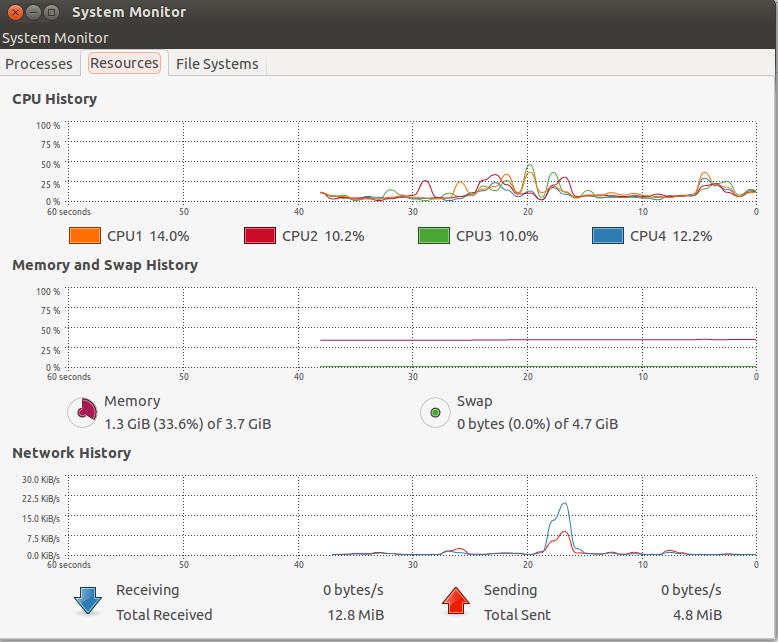
Системный монитор Gnome Linux
Приложение System Monitor позволяет отображать основную системную информацию и отслеживать системные процессы, использование системных ресурсов и файловых систем. Его также можно использовать для изменения поведения вашей системы. Хотя он и не такой мощный, как KDE System Guard, но зато он предоставляет основную информацию, которая может быть полезна для новых пользователей:
- Отображение основной информации об аппаратном и программном обеспечении компьютера.
- Версия ядра Linux
- Версия GNOME
- Аппаратные средства
- Встроенная память
- Процессоры и скорость работы
- Состояние системы
- Доступное дисковое пространство
- Процессы
- Память
- Использование сети
- Файловые системы
- Список всех файловых систем с основной информацией о каждой.
sar
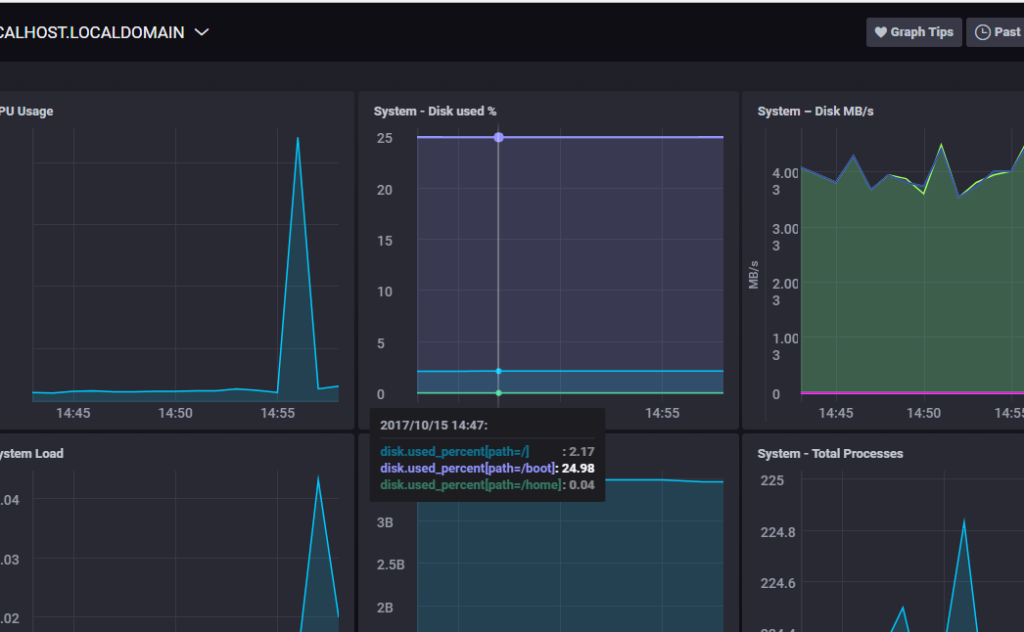
Программа является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда , на самом деле, состоит из трех программ: , которая отображает данные, и и , которые собирают и запоминают данные. После того, как программа установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между и в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
Cacti — веб-инструмент для мониторинга Linux
Cacti — это комплексное решение для построения сетевых графиков, предназначенное для использования возможностей RRDTool по хранению и графическому отображению данных. В Cacti есть функционал для обследования сети, расширенные шаблоны графиков, несколько методов сбора данных и функции управления пользователями. Все это сведено в интуитивно понятный и простой в использовании интерфейс, который подходит даже для сложных сетей с сотнями устройств. Он может предоставлять данные о сети, процессоре, памяти, пользователях вошедших в систему, Apache, DNS-серверах и многое другое.
Системные команды Linux
Эти команды используются для просмотра информации и управления, связанной с системой Linux.
1. uname
Команда Uname используется в Linux для поиска информации об операционных системах. В Uname существует много опций, которые могут указывать имя ядра, версию ядра, тип процессора и имя хоста.
Следующая команда uname с опцией отображает всю информацию об операционной системе.
2. uptime
Информация о том, как долго работает система Linux, отображается с помощью команды uptime. Информация о времени безотказной работы системы собирается из файла ‘/proc/uptime‘. Эта команда также отобразит среднюю нагрузку на систему.
Из следующей команды мы можем понять, что система работает в течение последних 36 минут.
Полное руководство команды Uptime
3. hostname
Вы можете отобразить имя хоста вашей машины, введя в своем терминале. С помощью опции вы можете просмотреть ip-адрес компьютера. А с помощью параметра вы можете просмотреть доменное имя.
4. last
Команда last в Linux используется для определения того, кто последним вошел в систему на вашем сервере. Эта команда отображает список всех пользователей, вошедших (и вышедших) из «/var/log/wtmp » с момента создания файла.
Вам просто нужно ввести «last» в своем терминале.
5. date
В Linux команда date используется для проверки текущей даты и времени системы. Эта команда позволяет задать пользовательские форматы для дат.
Рекомендуем статью Команда Date (Дата) в Linux с примерами использования
Например, используя «date +%D«, вы можете просмотреть дату в формате «ММ/ДД/ГГ«.
6. cal
По умолчанию команда cal отображает календарь текущего месяца. С помощью опции вы можете просмотреть календарь на весь год.
9. reboot
Команда reboot используется для перезагрузки системы Linux. Вы должны запустить эту команду из терминала с правами суперпользователя sudo.
10. shutdown
Команда shutdown используется для выключения или перезагрузки системы Linux. Эта команда позволяет планировать завершение работы и уведомлять пользователей сообщениями о выключении и перезагрузке.
По умолчанию компьютер (сервер) выключится через 1 минуту. Вы можете отменить расписание, выполнив команду:
Немедленное отключение тоже возможно, для этого используется опция «now»