Как найти самые большие файлы на жёстком диске
1. CCleaner![]()
В разделе «Сервис» находится полезный инструмент — «Анализ дисков», который используется для поиска больших файлов.
Использование дискового пространства иллюстрируется с помощью круговой диаграммы, отображающей распределение между основными типами файлов — изображениями, документами, видео.
Также вы можете перейти в раздел очистки системы, включить автоматическое определение файлов, которые могут быть удалены из оперативной памяти и жесткого диска за ненадобностью.
Однако рекомендуем внимательно ознакомиться с результатами вывода, чтобы не затронуть важные файлы, необходимые для функционирования ваших программ.
2. WinDirStat![]()
После запуска и предварительной оценки заполненности жёсткого диска WinDirStat выдаёт полную карту его состояния. Она состоит из различных квадратов, размер которых соответствует размеру файла, а цвет — его типу. Клик по любому элементу позволяет узнать его точный размер и месторасположение на диске. С помощью кнопок на панели инструментов можно удалить любой файл или просмотреть его в файловом менеджере.
3. SpaceSniffer![]()
Это приложение показывает карту заполненности диска, можно регулировать глубину просмотра и количество отображаемых деталей.
Для сбора данных Windows сервера можно также воспользоваться Performance Monitor.![]() Однако данный функционал нуждается в небольшой предварительной настройке.
Однако данный функционал нуждается в небольшой предварительной настройке.
Для оценки базовой производительности сервера достаточно собрать информацию:
- Average Disk Queue — для жестких дисков
- % Processor Time — для процессора и процессов
- Committed Bytes — для оперативной памяти
Когда процессу нужен доступ к физическому ресурсу, операционная система ставит запрос в очередь. Если в очереди стабильно больше 2 элементов, значит, ресурс становится узким местом.
Анализ данных с помощью утилиты PAL![]()
Утилита написана Клинтом Хаффманом, который является PFE-инженером Microsoft и занимается анализом производительности систем.
На вкладке Counter Log задаётся путь к файлу данных со счетчиками производительности, собранными ранее.![]()
Также мы можем задать интервал, за который будет производиться анализ.
На вкладке Threshold File находится список шаблонов, которые можно экспортировать в формат xml и использовать как список счетчиков для сборщика данных.![]()
Вот и всё. Здесь собрано значительное количество, однако далеко не все инструменты, которые можно использовать для анализа производительности на сервере
Важно понимать, какой критерий в производительности является для вас основополагающим. И выбирать программное обеспечение, отталкиваясь от заданных целей
Удачной работы.
![]()
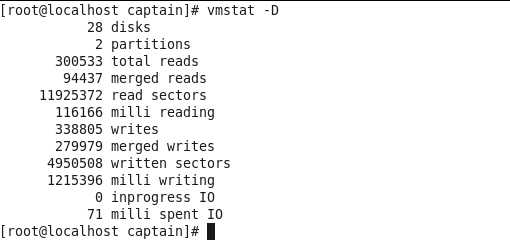
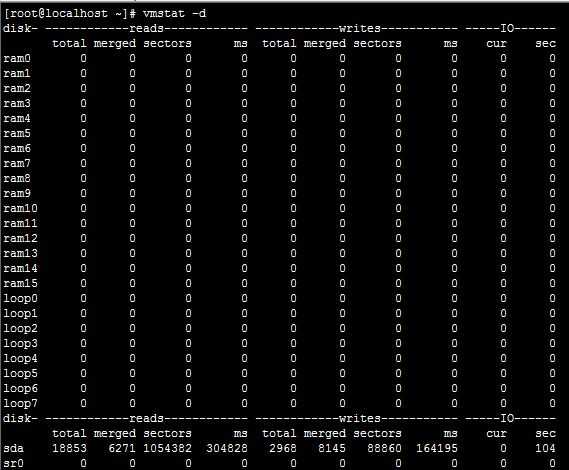
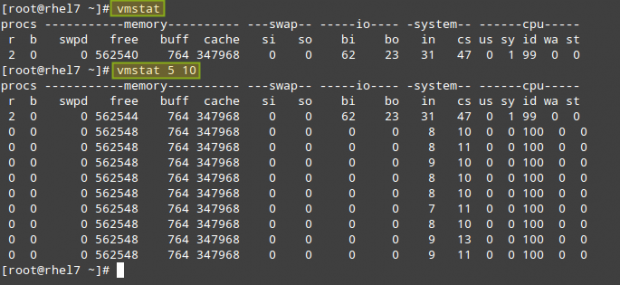
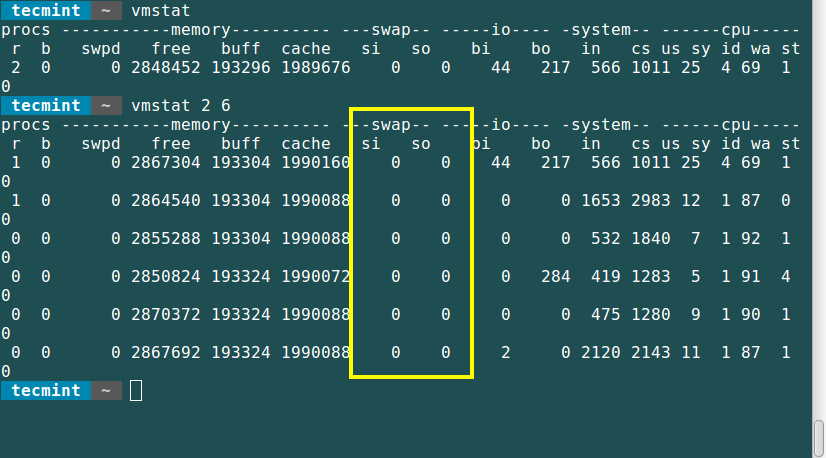
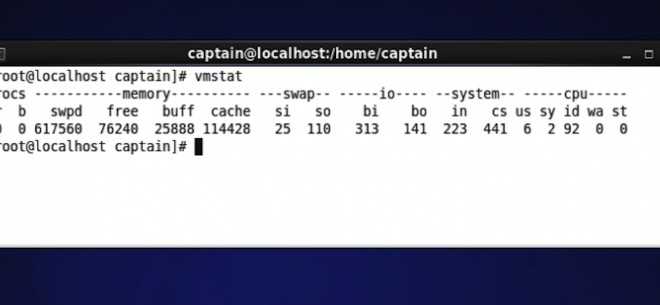
19.6. Утилита iostat
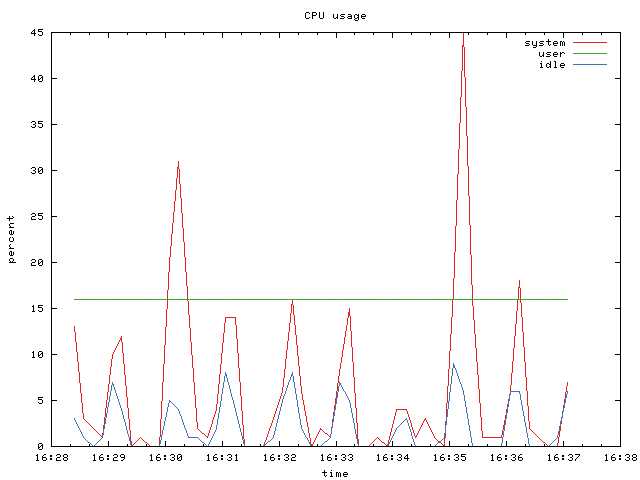
Утилита может выводить статистическую информацию об использовании ресурсов устройств для хранения данных и центрального процессора. Использованный в примере ниже параметр -d сообщает утилите iostat о необходимости вывода информации об использовании ресурсов устройств для хранения данных (500 раз в течение каждых двух секунд). В первом блоке данных приведена статистическая информация об использовании описанных ресурсов с момента последней перезагрузки системы.
$ iostat -d 2 500 Linux 2.6.9-34.EL (RHELv4u3.localdomain) 01/27/2007 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn hdc 0.00 0.01 0.00 1080 0 sda 0.52 5.07 7.78 941798 1445148 sda1 0.00 0.01 0.00 968 4 sda2 1.13 5.06 7.78 939862 1445144 dm-0 1.13 5.05 7.77 939034 1444856 dm-1 0.00 0.00 0.00 360 288 Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn hdc 0.00 0.00 0.00 0 0 sda 0.00 0.00 0.00 0 0 sda1 0.00 0.00 0.00 0 0 sda2 0.00 0.00 0.00 0 0 dm-0 0.00 0.00 0.00 0 0 dm-1 0.00 0.00 0.00 0 0 ... $
Вы можете получать больший объем статистических данных, использовав команду , или получать исключительно статистические данные, касающиеся центрального процессора, воспользовавшись командой .
$ iostat -c 5 500 Linux 2.6.9-34.EL (RHELv4u3.localdomain) 01/27/2007 avg-cpu: %user %nice %sys %iowait %idle 0.31 0.02 0.52 0.23 98.92 avg-cpu: %user %nice %sys %iowait %idle 0.62 0.00 52.16 47.23 0.00 avg-cpu: %user %nice %sys %iowait %idle 2.92 0.00 36.95 60.13 0.00 avg-cpu: %user %nice %sys %iowait %idle 0.63 0.00 36.63 62.32 0.42 avg-cpu: %user %nice %sys %iowait %idle 0.00 0.00 0.20 0.20 99.59 $
Команды Linux для работы с пользователями
Эти команды используются для управления пользователями Linux.
25. id
Команда ID используется в Linux для отображения реального и эффективного идентификатора пользователя (UID) и идентификатора группы (GID). UID — это единый идентификатор пользователя. В то время как идентификатор группы (GID) может состоять из нескольких идентификаторов UID.
27. who
Команда who — это инструмент для отображения информации о пользователях, которые в данный момент вошли в систему. who может видеть только реального пользователя, вошедшего в систему. Он не увидит пользователя, выполняющего команду su.
Команда Groupadd используется для создания группы в Linux.
Следующая команда добавит в систему группу «setiwiki«.
29. useradd
В операционных системах Linux и Unix — подобных наиболее распространенной командой для создания пользователей является «useradd» или «adduser«.
Давайте посмотрим, как создать нового пользователя «setiwik» и установить пароль. Команда добавляет запись в файлы /etc/passwd, /etc/shadow, /etc/group и /etc/gshadow.
30. userdel
Userdel — это низкоуровневая утилита для удаления пользователей. Команда Userdel будет искать файлы системных учетных записей, такие как «/etc/password » и «/etc/group«, а затем удалит оттуда все записи, связанные с именем пользователя.
31. usermod
Команда Linux usermod используется для изменения атрибутов существующего пользователя. Атрибутами пользователя являются домашний каталог, оболочка, дата истечения срока действия пароля, группы, UID и т.д.
32. passwd
Passwd — это команда, используемая в Linux (Redhat, Centos, Ubuntu, Debian, Fedora) и UNIX-подобных операционных системах для смены паролей.
Wireshark
Программа , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
19.2. Утилита top
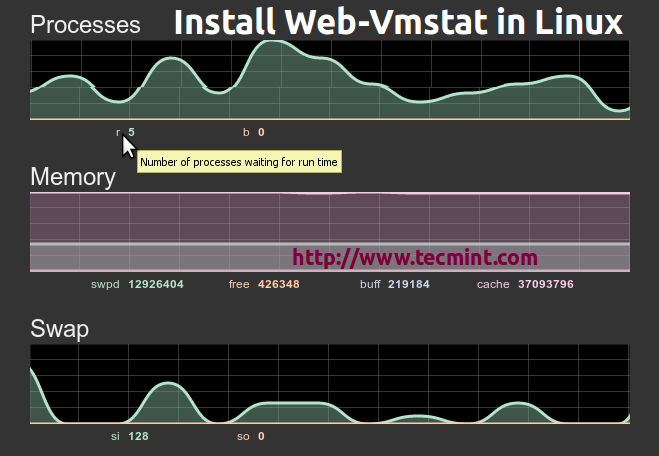
В начале процесса мониторинга использования ресурсов системы вы можете прибегнуть к использованию утилиты . Данная утилита позволяет осуществлять мониторинг использования ресурсов оперативной памяти, центрального процессора и пространства подкачки. Утилита автоматически обновляет вывод. После запуска данной утилиты вы можете использовать множество команд, таких, как команда , предназначенная для завершения работы процессов, команды или , предназначенные для показа и скрытия информации о процессах и использовании памяти или команда , предназначенная для переключения между режимами вывода информации об использовании ресурсов каждого отдельного центрального процессора или всех центральных процессоров.
top - 12:23:16 up 2 days, 4:01, 2 users, load average: 0.00, 0.00, 0.00 Tasks: 61 total, 1 running, 60 sleeping, 0 stopped, 0 zombie Cpu(s): 0.3% us, 0.5% sy, 0.0% ni, 98.9% id, 0.2% wa, 0.0% hi, 0.0% si Mem: 255972k total, 240952k used, 15020k free, 59024k buffers Swap: 524280k total, 144k used, 524136k free, 112356k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 16 0 2816 560 480 S 0.0 0.2 0:00.91 init 2 root 34 19 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/0 3 root 5 -10 0 0 0 S 0.0 0.0 0:00.57 events/0 4 root 5 -10 0 0 0 S 0.0 0.0 0:00.00 khelper 5 root 15 -10 0 0 0 S 0.0 0.0 0:00.00 kacpid 16 root 5 -10 0 0 0 S 0.0 0.0 0:00.08 kblockd/0 26 root 15 0 0 0 0 S 0.0 0.0 0:02.86 pdflush ...
Вы можете настроить утилиту top таким образом, чтобы осуществлялся вывод исключительно выбранных вами столбцов или вывод параметров единственного процесса, который вас интересует.
$ top p 3456 p 8732 p 9654
Что такое Phoronix Test Suite?
С помощью Phoronix Test Suite вы можете найти узкое место в своей конфигурации компьютера, сравнить вашу систему с аналогичными системами других пользователей, оценить общую производительность или производительность конкретных узлов ПК. Для всех этих целей пакет предлагает широкий выбор тестов, разделённый на несколько категорий:
- System — тесты общей производительности системы.
- Processor — тесты производительности процессора.
- Memory — тесты производительности оперативной памяти.
- Graphics — тестирование производительности видеокарты.
- Disk — тесты производительности дисковой подсистемы.
Рассмотрим каждую категорию отдельно, составив список интересных бенчмарков.
#5. Zabbix
Ключевые особенности:
- Zabbix – это бесплатный инструмент для мониторинга серверов с открытым исходным кодом.
- Мы можем легко контролировать серверы, приложения и сетевые устройства, что дает точную статистику и данные о производительности.
- Данные, собранные Zabbix, позволяют легко проанализировать нашу инфраструктуру.
Типы мониторинга, выполняемые Zabbix:
- Мониторинг сети
- Мониторинг сервера
- Облачный мониторинг
- Мониторинг приложений
- Мониторинг служб
Zabbix имеет сквозное шифрование и хорошую аутентификацию, и благодаря этому Zabbix имеет надежную защиту.
В Zabbix есть несколько веток, поэтому распределенный мониторинг возможен одновременно.
Преимущества:
- Zabbix разработан для масштабирования от небольших сред до больших сред.
- Zabbix доверяют такие мировые бренды, как Dell, HP, Salesforce, T Systems и т. Д.
- Zabbix имеет высокую доступность, потому что у него несколько серверов, таких как прокси-серверы, поэтому нагрузка распределяется.
см. также:
46. csysdig – ncurses интерфейс для sysdig
csysdig экспортирует функциональность sysdig через интуитивный и мощный пользовательский интерфейс, основанный на ncurses.
csysdig создана похожей на инструменты вроде top и htop, но программа предлагает более богатую функциональность, включая:
- Поддержку живого анализа и файлов трассировки sysdig. Файлы трассировки могут быть с этой же машины или с другой машины.
- Видимость широкого диапазона метрик, включая центральной процессор, память, дисковый вводы/вывод, сетевой вводы/вывод.
- Возможность наблюдать активности ввода/вывода для процессов, файлов, сетевых подключений и прочего.
- Возможность углубляться в процессы, файлы, сетевые соединения и многое другое для более глубокого изучения их поведения.
- Полная поддержка настройки под пользователя.
- Поддержка языка фильтров sysdig.
- Поддержка LXC.
- csysdig может работать в любом терминале и имеет поддержку цветов и ввода мышью.
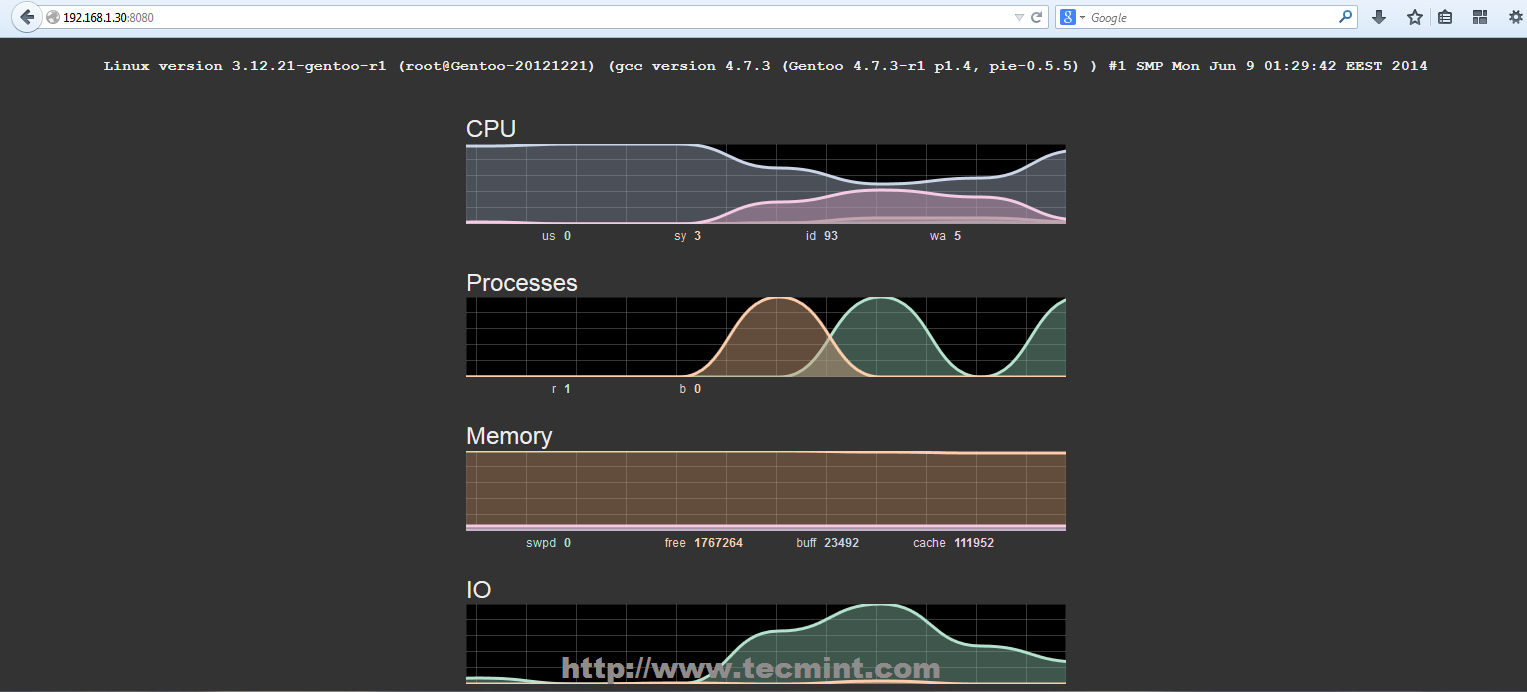
Приступая к работе с dstat
Теперь dstat должен быть установлен и готов отображать статистику производительности вашей системы.В своей простейшей форме dstat может быть вызван с помощью команды:
start dstat
Так же можно вызвать еще одним способом:
запуск dstat в линукс
Чтобы направить вывод в файл CSV для последующего использования мы можем выполнить следующую команду:
запуск dstat в Ubuntu
Файл можно посмотреть перейдя в директорию /tmp/sampleoutput.csv
экспорт данных dstat в CSV
Dstat опции:
-c, –cpuвыведет процессорую статистику
-C 0,3общая инфо включает CPU0, CPU3 и общей
-d,–diskпозволит показать статистику дисков
-Dвсего, HDA,HDA и общее
-g, —pageпозволяют показать статистику страницы
-i,—intвключить статистику прерываний
-I 5, eth2 включают int5 и прерывание используется eth2
-l, —load позволяют увидеть статистику нагрузки
-m,-memвключить статистику памяти
-n,–netпозволяют видеть сетевую статистику
-N eth1всего,включают eth1, общее
-p,—procпозволит увидеть статистику процесса
-r,–ioвключить IO статистику (запросы ввода / вывод завершен)
-s, —swapпозволяют увидеть статистику подкачки
-S swap1всего, включают swap1, общей
-t, —timeвключения вывода даты / времени
-T,—epochвключить счетчик времени (секунд с начала эпохи)
-y,—sysвключить статистику системы
—aioвключить статистику aio
—fs, —filesystemвключить статистику fs
—ipcвключить статистику ipc
—lockвключить статистику lock
—rawвключить статистику raw
—socketвключить статистику socket
—tcpвключить статистику tcp
—udpвключить статистику udp
—unixвключить статистику unix
—vmвключить статистику vm
—plugin-nameвключить плагины для плагинного имени
—listЛист всех доступных плагинов
Для получения полного списка всех доступных опций, выполните команду:
Dstat инструмент для мониторинга в Linux очень прост и очень полезный. На этом я завершу данную тему.
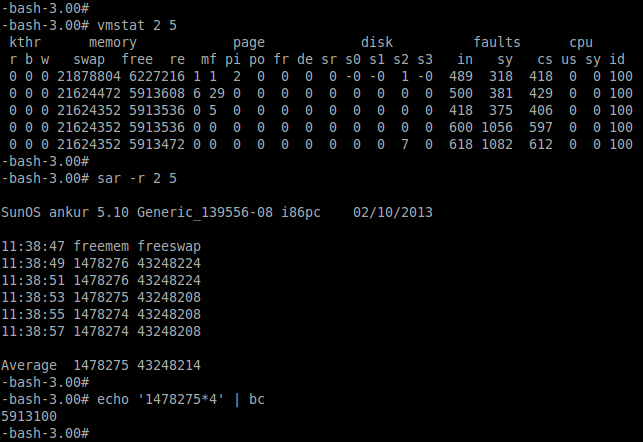
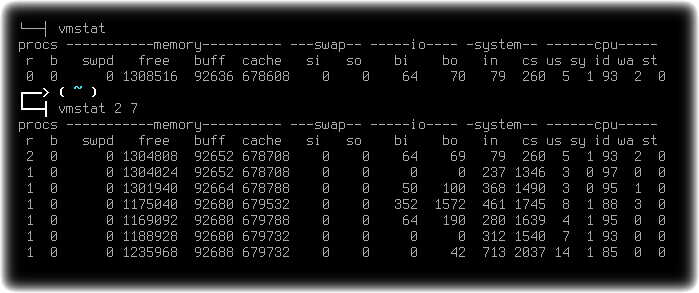
№ 9: mpstat – использование мультипроцессора
Команда mpstat выводит данные об активности каждого имеющегося в наличие процессора, процессор 0 будет первым. Команда mpstat -P ALL выводит данные о среднем использовании ресурсов для каждого из процессоров:
# mpstat -P ALL
Пример вывода данных:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009 06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s 06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04 06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31 06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93 06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00 06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80 06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91 06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98 06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75 06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
Ссылки:
Информация о процессоре
Команды для получения данных о процессоре.
1. lscpu (Linux)
Команда показывает информацию о характеристиках процессора в удобном виде:
lscpu
Пример ответа:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 1
Core(s) per socket: 4
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 62
Model name: Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
Stepping: 4
CPU MHz: 2592.918
BogoMIPS: 5187.50
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 20480K
NUMA node0 CPU(s): 0-7
* больше всего нас интересует:
- Architecture — архитектура процессора — 32 бит или 64.
- Core(s) per socket — количество ядер на процессор.
- Socket(s) — количество физических/виртуальных процессоров.
- CPU(s) — суммарное количество процессорных ядер.
- Model name — модель процессора.
2. sysctl -a (FreeBSD)
Команда отображает множество данных, поэтому добавляем фильтр:
sysctl -a | egrep -i ‘hw.machine|hw.model|hw.ncpu’
Пример ответа:
hw.model: Intel(R) Xeon(R) CPU X5690 @ 3.47GHz
hw.machine: amd64
hw.ncpu: 2
* на самом деле, команда sysctl работает и в Linux, но формат вывода менее удобен, по сравнению с вышерассмотренной lscpu.
3. Файл /proc/cpuinfo (Linux)
Позволяет увидеть подробную информацию по каждому ядру:
cat /proc/cpuinfo
Команда для подсчета количества ядер:
cat /proc/cpuinfo | grep processor | wc -l
Linux
Сначала необходимо установить утилиту.
На CentOS (RPM):
yum install lm_sensors
Ubuntu (Deb):
apt-get install lm-sensors
После установки утилиты выполняем:
sensors-detect
sensors
FreeBSD
Загружаем необходимый модуль:
kldload coretemp
* для автоматической его загрузки добавляем в файл /boot/loader.conf строку coretemp_load=»YES»
Вводим команду:
sysctl -a | grep temperature
Пример ответа:
dev.cpu.0.temperature: 40.0C
dev.cpu.1.temperature: 41.0C
Файлы, которых нет
Если говорить совсем откровенно, в Linux основным источником информации как о процессах, так и о железе служит именно файловая виртуальная файловая система
procfs(/proc), а также
sysfs(/sys). И у них довольно богатая и интересная история.
Дело в том, что одно из официальных положений идеологии UNIX гласит: «Всё есть файл», то есть взаимодействие с любым системным компонентом теоретически должно вестись через реальный или виртуальный файл, доступный через обычное дерево каталогов. Эту идею до абсолюта довели в наследнике UNIX под названием Plan 9, где все процессы превратились в каталоги и взаимодействовать с ними можно было даже посредством команд
cat и
ls, поскольку они были текстовыми. Именно так появилась файловая система procfs, которая позже перекочевала в Linux и BSD.
Но, как и в случае с load average, конкретно в Linux есть свои тонкости (это я так политкорректно называю адскую кашу-малашу). Например, линуксовый
/proc, вопреки названию, с самого начала был универсальным интерфейсом получения информации от ядра в целом, а не только от процессов. Более того, именно взаимодействовать с процессами через эту систему практически не получается, только извлекать информацию по их PID’ам.
С течением времени в
/proc появлялось все больше и больше файлов, содержащих информацию о самых разных подсистемах ядра, железе и многом другом. В конечном итоге он превратился в помойку, и разработчики решили вынести информацию хотя бы о железе в отдельную файловую систему, которую к тому же можно было бы использовать для формирования каталога
/dev. Так и появилась
/sys со своей странной структурой каталогов — ее трудно разгребать вручную, но она очень удобна для автоматического анализа другими приложениями (такими как udev, который и формирует содержимое каталога
/dev на основе информации из
/sys).
В итоге куча информации до сих пор дублируется в
/proc и
/sys просто потому, что, если выкинуть файлы из
/proc, можно сломать некоторые фундаментальные системные компоненты (легаси!), которые до сих пор не переписаны.
Ну а еще есть
/run, конечно же. Это файловая система, которая монтируется одной из первых и служит перевалочным пунктом для данных рантайма основных системных демонов, в частности udev и systemd (о нем поговорим отдельно чуть позже). Кстати, сам проект udev в 2012 году влился в systemd и дальше развивается как его часть.
В общем, как писал Льюис Кэрролл, «все чудесатее и чудесатее».
Но вернемся к нашим замерам. Для того чтобы смотреть, какие PID присвоены процессам, есть команды
pidstat и
htop (из одноименного пакета, более продвинутая версия top, заодно показывает чертову прорву всего, аналог графического диспетчера задач).


Кроме того, команда time позволяет запустить процесс, попутно измерив время его выполнения, точнее, целых три времени:
|
1 |
$time python3-c»import time; time.sleep(1)» python3-c»import time; time.sleep(1)»0.04suser0.01ssystem4%cpu1.053total |
Как выше я уже проговорился, любая программа может проводить разное время в kernel space и user space, то есть выполняя вызовы в ядро или свой собственный код. Поэтому при базовом взгляде на эти цифры можно в некоторых случаях уже сделать вывод об узком месте в программе: если первый показатель сильно выше, то, вполне возможно, затык в I/O, а если второй — то, возможно, в коде есть неэффективно написанные куски, которые стоит запрофилировать подробнее.
А вот третье время, total time, оно же wall clock time или real time, — это время, которое реально заняло выполнение программы с момента запуска до момента возврата управления. Кстати, user time может быть сильно больше real time, потому что оно рассчитывается как сумма по всем ядрам CPU. Если такое происходит — значит, программа неплохо параллелится.
Ну и напоследок, чтобы посмотреть загрузку для каждого ядра в отдельности, можно использовать вот такую команду:
| 1 | $mpstat-PALL1 |
Если будут сильные перекосы в загрузке ядер — значит, какая-то из программ, напротив, параллелится крайне плохо. А единичка значит «обновляй-ка раз в секунду».
Как работает мониторинг сети?
Все данные, которые распространяются через интернет передаются в виде пакетов определенного размера. Данные разделяются на части определенного размера и из них составляются пакеты, которые будут отправлены в ядро системы а затем в сеть, где пройдут путь из многих компьютеров и маршрутизаторов пока достигнут цели
С помощью специального программного обеспечения мы можем отслеживать сколько пакетов и какого размера проходит через наш компьютер и неважно, были они созданы локальной программой или получены из сети
Таким образом, очень просто можно узнать какая сейчас нагрузка на сеть, какие программы или сервисы создали пакеты, и даже что содержится в этих пакетах и что делает пользователь.
Получение информации о жестком диске (Hard Disk).
1. Команда hdparm -I /dev/sda выводит подробную информацию о жестком диске.
# hdparm -I /dev/sda /dev/sda: ATA device, with non-removable media Model Number: Hitachi HDS721050CLA662 Serial Number: JP1572JE3A9VUK Firmware Revision: JP2OA41A Transport: Serial, ATA8-AST, SATA 1.0a, SATA II Extensions, SATA Rev 2.5, SATA Rev 2.6, SATA Rev 3.0 . . . . . . . . . . . . . . . . . . . .
2. Команда smartctl -a /dev/sda выводит информацию о параметрах, атрибутах smart диска, используется для тестирования диска.
# smartctl -a /dev/sda Device Model: Hitachi HDS721050CLA662 Serial Number: JP1572JE3A9VUK LU WWN Device Id: 5 000cca 397eef741 Firmware Version: JP2OA41A User Capacity: 500,107,862,016 bytes Sector Size: 512 bytes logical/physical . . . . . . . . . . . . . . 1 Raw_Read_Error_Rate 0x002f 100 099 016 Pre-fail Always - 0 2 Throughput_Performance 0x0027 136 100 054 Pre-fail Always - 92 3 Spin_Up_Time 0x0023 125 100 024 Pre-fail Always - 174 (Average 192) 4 Start_Stop_Count 0x0022 100 100 000 Old_age Always - 31 5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0 7 Seek_Error_Rate 0x002f 100 100 067 Pre-fail Always - 0 . . . . . . . . . . . . . . . . . . . .
3. Утилита df -h отображает точки монтирования, тип файловой системы, использование места на диске.
# df -h Filesystem Size Used Avail Use% Mounted on rootfs 454G 30G 424G 7% / devtmpfs 1.7G 52K 1.7G 1% /dev /dev/sda2 454G 30G 424G 7% /
4. Утилита fdisk -l выводит информацию о жестком диске — партициях, секторах, и т.д.
# fdisk -l Disk /dev/sda: 500.1 GB, 500107862016 bytes 255 heads, 63 sectors/track, 60801 cylinders, total 976773168 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk identifier: 0xb447e346 Device Boot Start End Blocks Id System /dev/sda1 63 9767519 4883728+ 82 Linux swap / Solaris /dev/sda2 * 9767520 976773167 483502824 83 Linux
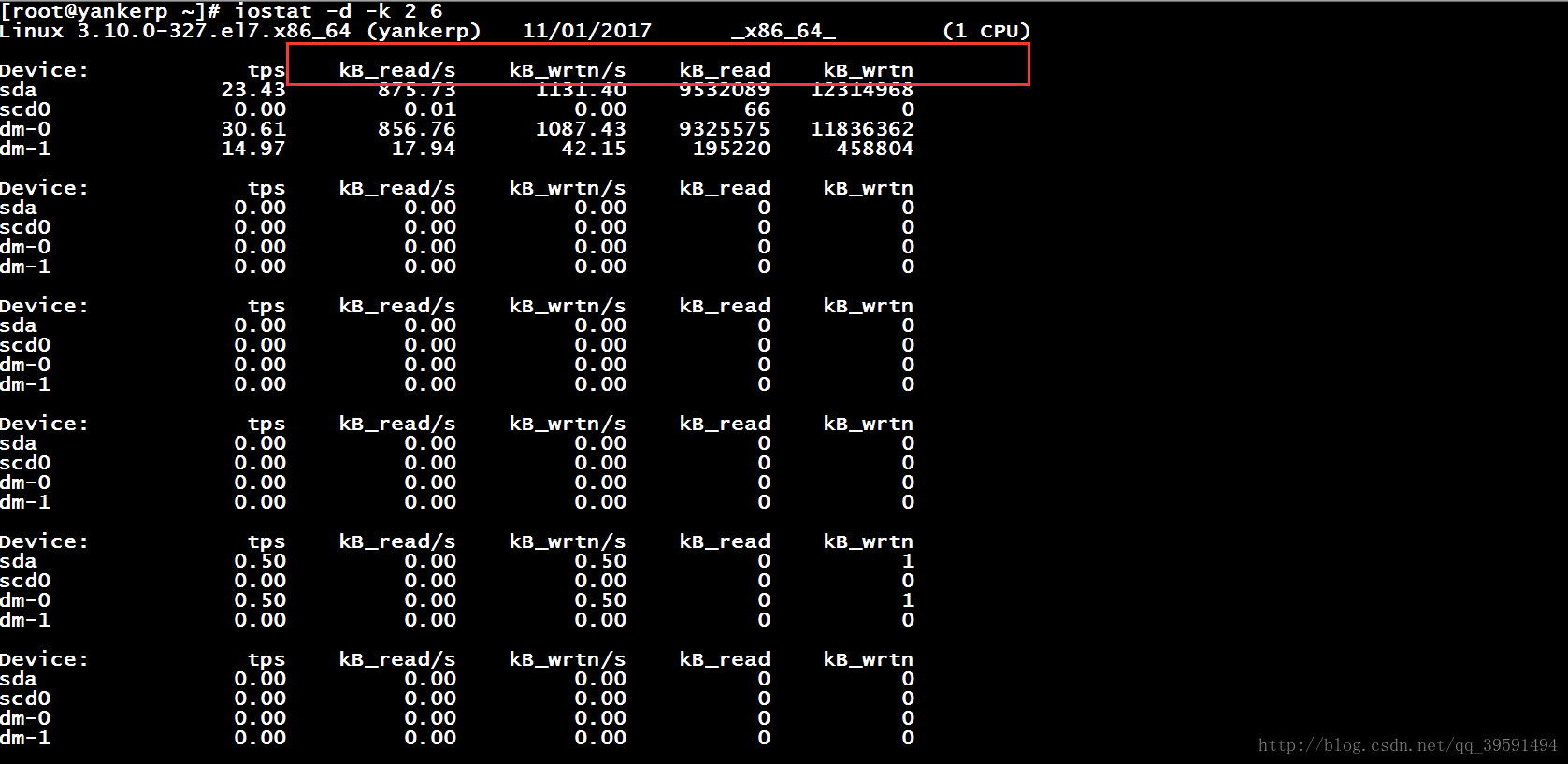
8. Iostat – Статистика ввода/вывода
IoStat – это простой инструмент, который собирает и показывает статистику по системному вводу и выводу на устройства хранения. Этот инструмент часто используется для отслеживания проблем производительности, в том числе на устройствах, локальных дисках, удалённых дисках таких как NFS. Программа по умолчанию недоступна. Она включена в пакет sysstat, т.е. для её использования нужно установить этот пакет.
iostat
Linux 4.9.6-1-ARCH (HackWare) 29.01.2017 _x86_64_ (3 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
3,42 0,00 0,11 0,51 0,00 95,97
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 1,57 23,90 1,79 372283 27897
Немного о вводе-выводе
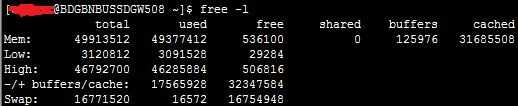
Операции ввода-вывода в большинстве случаев осуществляются не через механизм отображения памяти, а операциями read()/write(). Это универсальный способ, который подходит не только для блочных устройств, но и для устройств последовательного доступа и для сетей передачи данных.
Данные, которые читаются и пишутся подобным образом, используют буферизацию ввода-вывода. В самом деле, к примеру — бывает, что программа способна накидать много данных и даже закончить свою работу (или прерваться на время), а медленное дисковое устройство все еще будет их принимать.
Для операционной системы, при наличии свободного места в памяти, выгоднее принять эти данные максимально возможной порцией и дать программе заниматься чем-то еще, пока другие процессы спокойно пишут на устройство.
В таких случаях из свободной оперативной памяти выделяется пространство под «буферы» (buffers), которые также могут раздуваться и освобождаться и считаются потенциально частью реально свободной оперативной памяти.
В то же время, так же как и с Cached-памятью, если система осуществляет массивный ввод-вывод, невозможность роста buffers будет приводить к тому, что процессы будут чаще ожидать окончания операций ввода-вывода, вместо выполнения полезной нагрузки.