5.3 Эксплуатация
Войдите в каталог elasticsearch / bin, вы увидите следующие исполняемые файлы:
Затем введите команду:
Обнаружено, что сообщается об ошибке и запуск не удался.
5.3.1 Ошибка 1: ядро слишком мало
[Не удалось передать изображение по внешней ссылке. На исходном сайте может быть механизм ссылки, предотвращающий пиявку. Рекомендуется сохранить изображение и загрузить его напрямую (img-hEfdofMh-1584342573897) (mdpic / 1558339701613.jpg)]
Мы используем centos6, а его версия ядра Linux — 2.6. Для подключаемого модуля Elasticsearch требуется версия не ниже 3.5. Но это не беда, мы можем отключить этот плагин.
Измените файл elasticsearch.yml и добавьте следующую конфигурацию внизу:
Затем перезапустите
5.3.2 Ошибка 2: недостаточные права доступа к файлу
Запустился снова, произошла еще одна ошибка: Мы используем пользователя es вместо root, поэтому прав доступа к файлу недостаточно.
Сначала войдите в систему как пользователь root.
Затем измените файл конфигурации:
Добавьте следующий контент:
5.3.3 Ошибка 3: недостаточно потоков
В отчете об ошибке есть еще одна строка:
На это не хватает тем.
Продолжайте изменять конфигурацию:
Измените следующее содержимое:
Кому:
5.3.4 Ошибка 4: Виртуальная память процесса
vm.max_map_count: ограничить количество VMA (области виртуальной памяти), которое может иметь процесс, продолжить изменение файла конфигурации:
Добавьте следующий контент:
Затем выполните команду:
5.3.5 Перезапустить окно терминала
После исправления всех ошибок необходимо перезапустить терминал виртуальной машины, иначе конфигурация будет недействительной.
5.3.6 Пуск
Начать заново и наконец-то удалось!
Вы можете видеть, что два порта связаны:
- 9300: Интерфейс связи между узлами кластера.
- 9200: Интерфейс клиентского доступа
Заходим в браузере: http://192.168.82.193:9200
Настройка Elasticsearch
Данные Elasticsearch хранятся в каталоге , файлы конфигурации находятся в а параметры запуска Java можно настроить в .
По умолчанию Elasticsearch настроен на прослушивание только на локальном хосте. Если клиент, подключающийся к базе данных, также работает на том же хосте, и вы настраиваете кластер с одним узлом, вам не нужно изменять файл конфигурации по умолчанию.
Удаленный доступ
По умолчанию Elasticsearch не реализует аутентификацию, поэтому к нему может получить доступ любой, кто имеет доступ к HTTP API. Если вы хотите разрешить удаленный доступ к серверу Elasticsearch, вам нужно будет настроить брандмауэр и разрешить доступ к порту 9200 Elasticsearch только для доверенных клиентов.
Ubuntu поставляется с инструментом настройки брандмауэра под названием UFW . По умолчанию UFW установлен, но не включен. Перед включением брандмауэра UFW сначала добавьте правило, разрешающее входящие соединения SSH:
Разрешить оценку с удаленного доверенного IP-адреса:
Не забудьте изменить на свой удаленный IP-адрес.
Включите UFW, набрав:
Наконец, проверьте статус брандмауэра:
Результат должен выглядеть примерно так:
После настройки брандмауэра следующим шагом будет редактирование конфигурации Elasticsearch и разрешение Elasticsearch прослушивать внешние подключения.
Для этого откройте файл конфигурации :
Найдите строку, содержащую , раскомментируйте ее и измените значение на :
/etc/elasticsearch/elasticsearch.yml
Если у вас есть несколько сетевых интерфейсов на вашем компьютере, вы можете указать IP-адрес интерфейса, который заставит Elasticsearch прослушивать только указанный интерфейс.
Перезапустите сервис Elasticsearch, чтобы изменения вступили в силу:
Вот и все. Теперь вы можете подключиться к серверу Elasticsearch из своего удаленного местоположения.
Установка ElasticSearch (один сервер) кластер в Unix/Linux
Проверка Java
Java является основным требованием при установке ES. Поэтому, убедитесь что в вашей системе установлена Java:
Если в вашей системе не установлена Java, используйте одну из следующих ссылок для ее установки:
Установка JAVA (JDK) на CentOS/RHEL/Fedora
Установка JAVA 9 (JDK9) на Debian/Ubuntu/LinuxMint
Установка Java на Debian/Ubuntu/Mint
Вот еще полезное чтиво:
Узнать размер Java Heap Memory Size
Установка переменных JAVA_HOME / PATH в Linux
Установка ElasticSearch (один сервер) кластер в Debian/Ubuntu
-===СПОСОБ 1 — использовать репозиторий ===-
Импортируем ключ Eliteearch PGP ключ:
Возможно, вам придется установить пакет apt-transport-https на Debian:
Добавлем репозиторий:
Выполняем установку ES:
-===СПОСОБ 2 — использовать DEB пакет ===-
-===СПОСОБ 3 — использовать исходный код ===-
Будет описан ниже.
Установка ElasticSearch (один сервер) кластер в CentOS/Fedora/RHEL
-===СПОСОБ 1 — использовать репозиторий ===-
Загружаем ключ:
Добавляем репозиторий:
И прописываем:
Выполняем установку ES:
Если используете Fedora:
-===СПОСОБ 2 — использовать RPM пакет ===-
-===СПОСОБ 3 — использовать исходный код ===-
Будет описан ниже.
Установка ElasticSearch (один сервер) кластер в Mac OS X
Для начала, устанавливаем HOMEBREW — Установка HOMEBREW на Mac OS X после чего, выполняем поиск пакета:
Вывод:
Как уже поняли, имеется несколько пакетов, я установлю:
Установка ElasticSearch (один сервер) кластер в других Unix/Linux ОС
-===Docker===-
Можно запустить докер контейнер с ES, но мне не приходилось этого делать. Т.к не было нужды. Если появится такая возможность, я обязательно дополню данную тему.
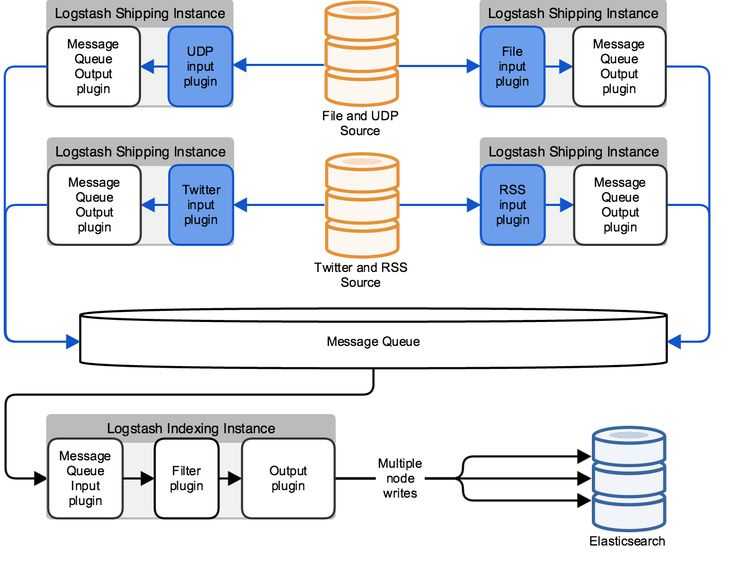
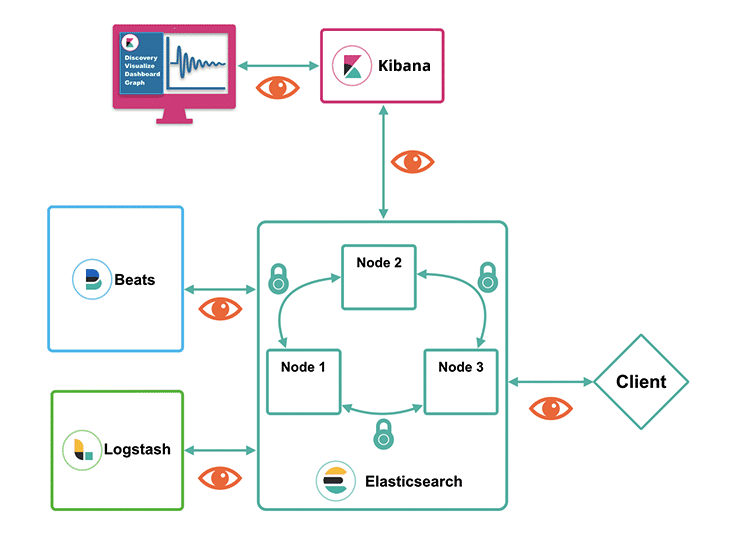
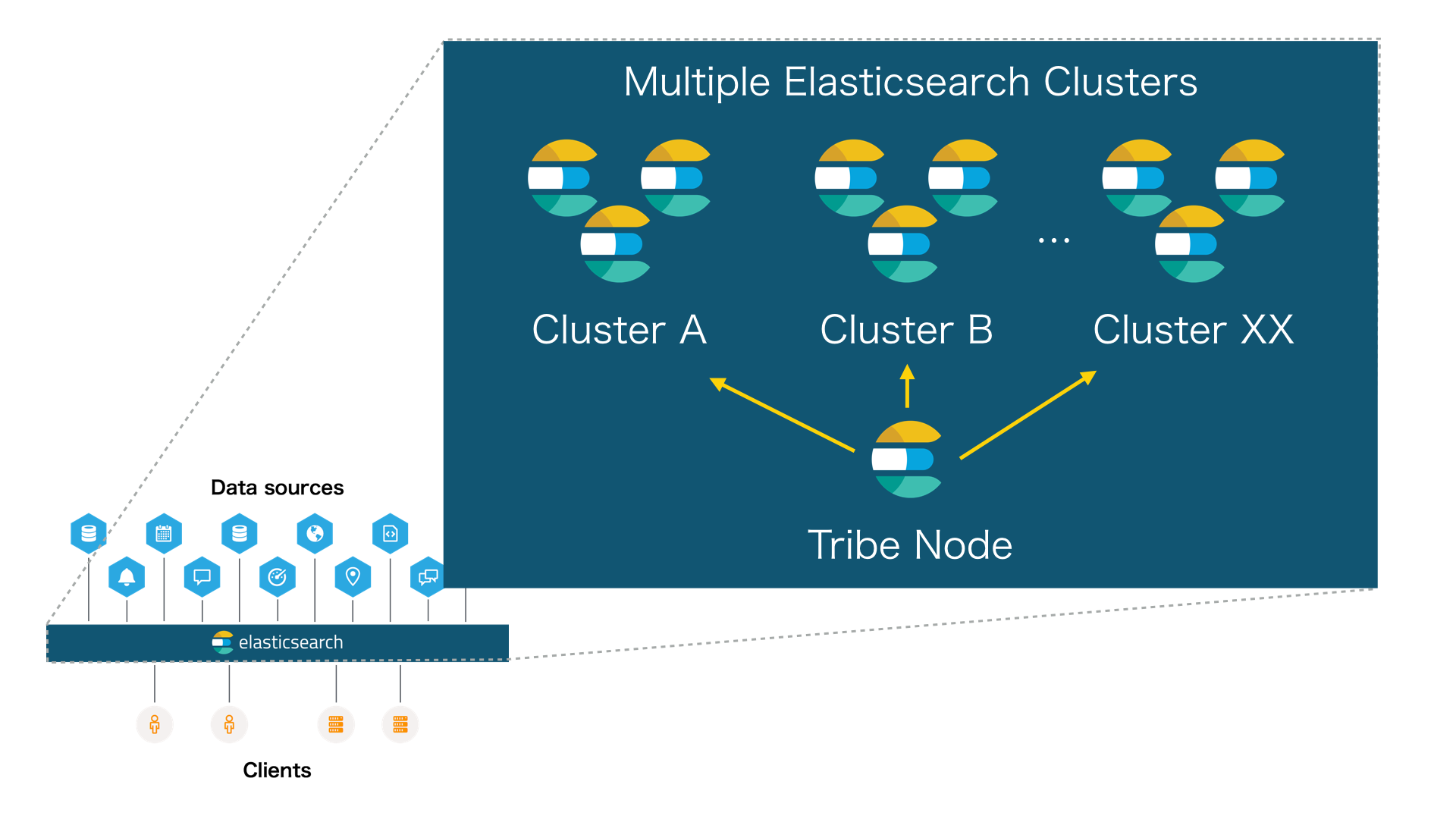
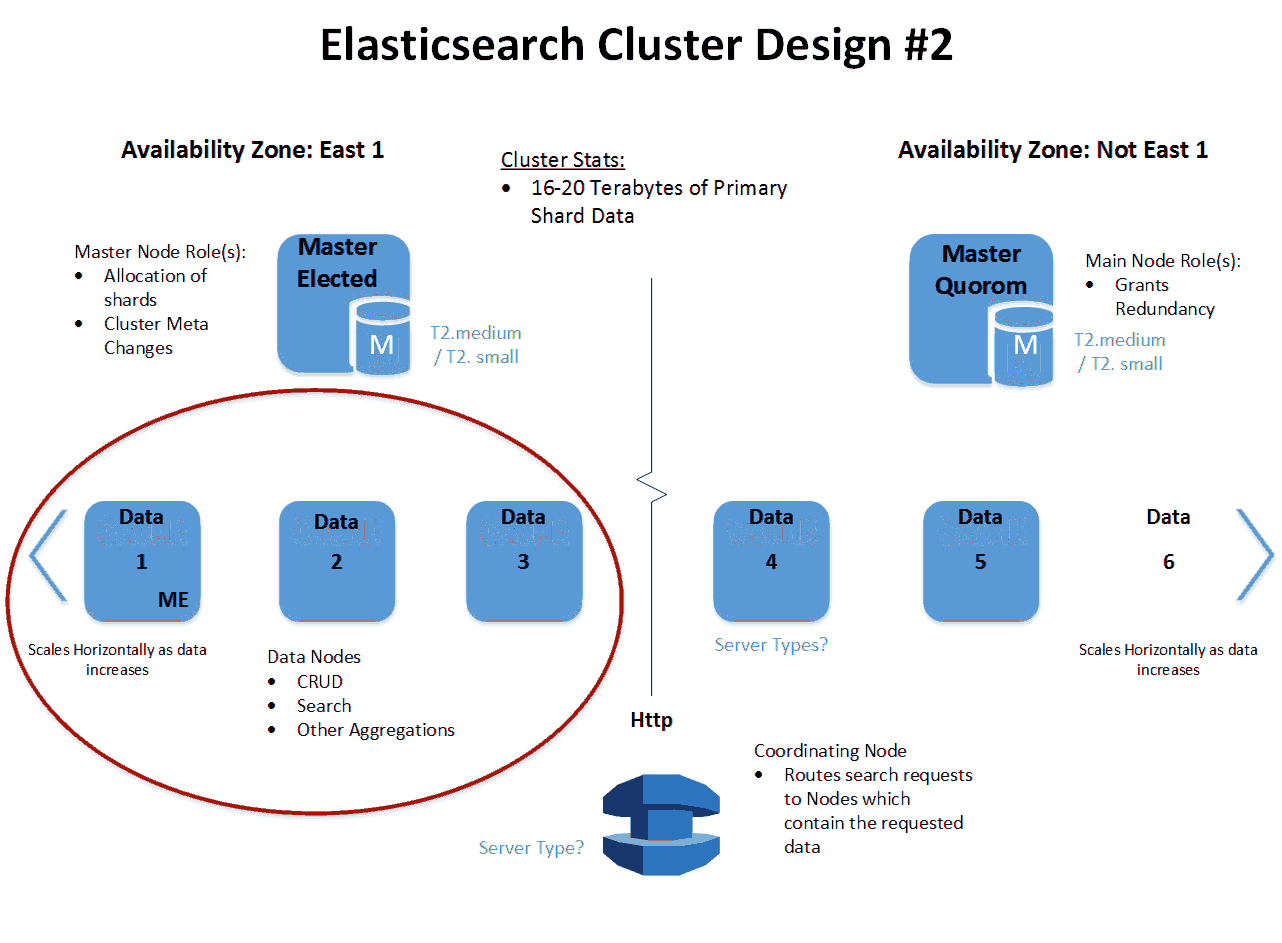
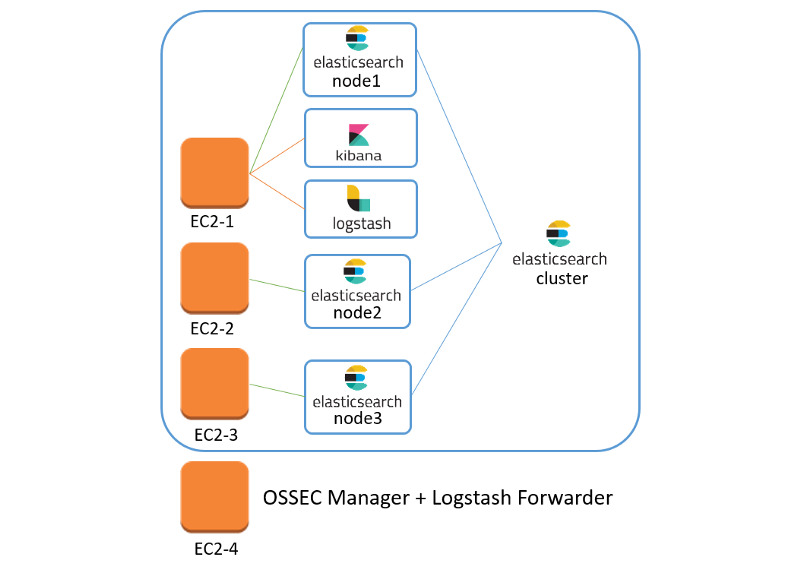
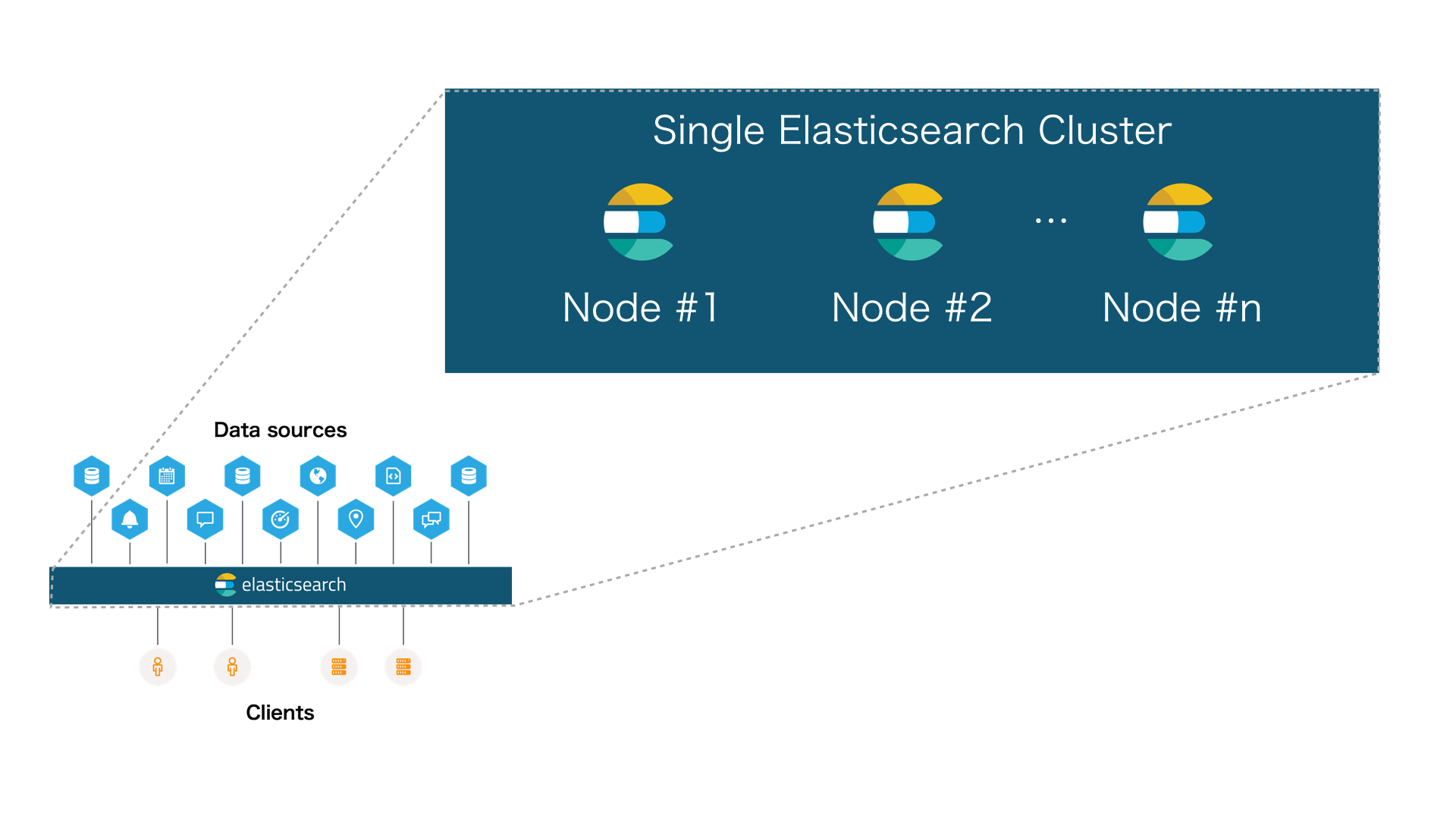
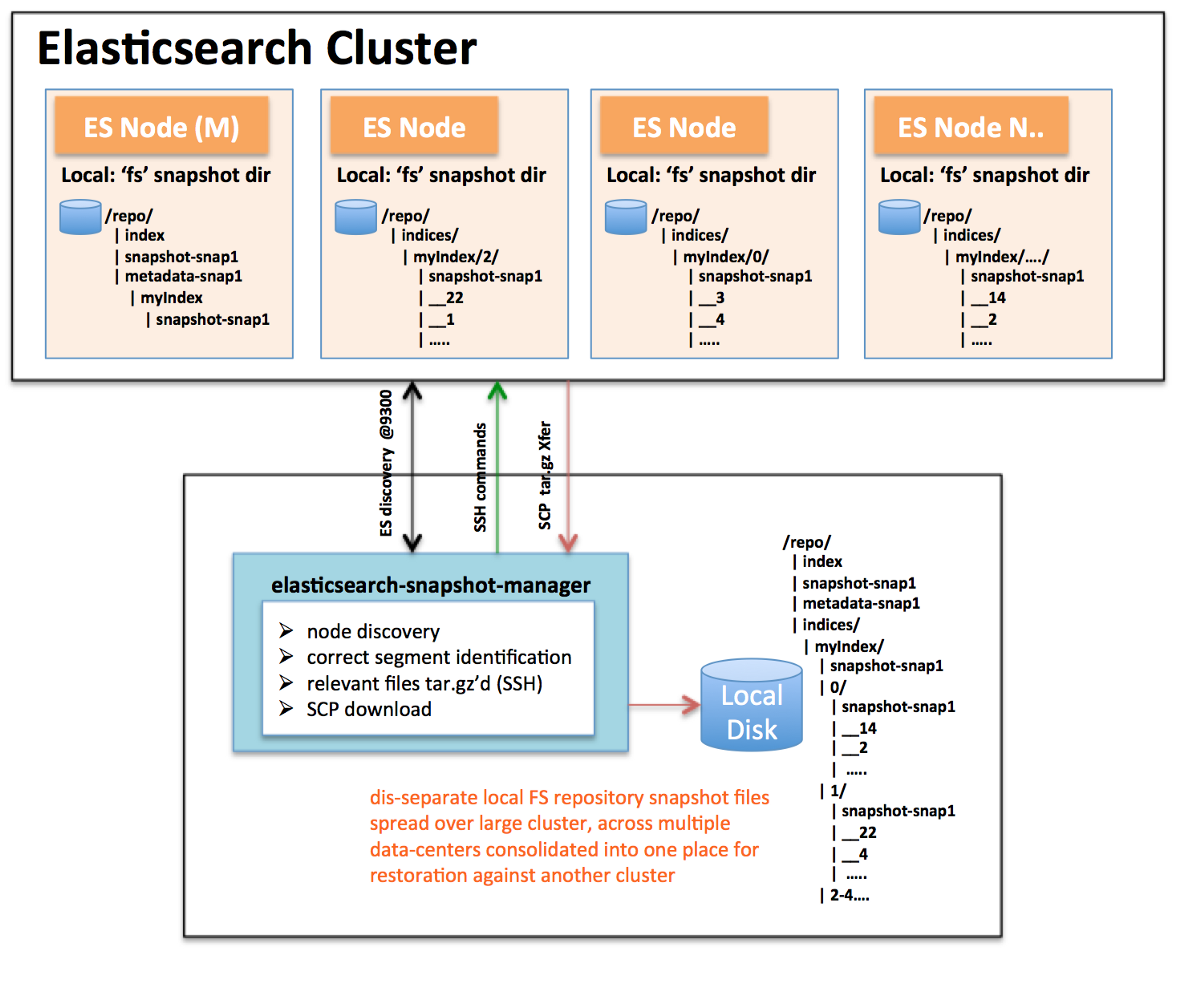
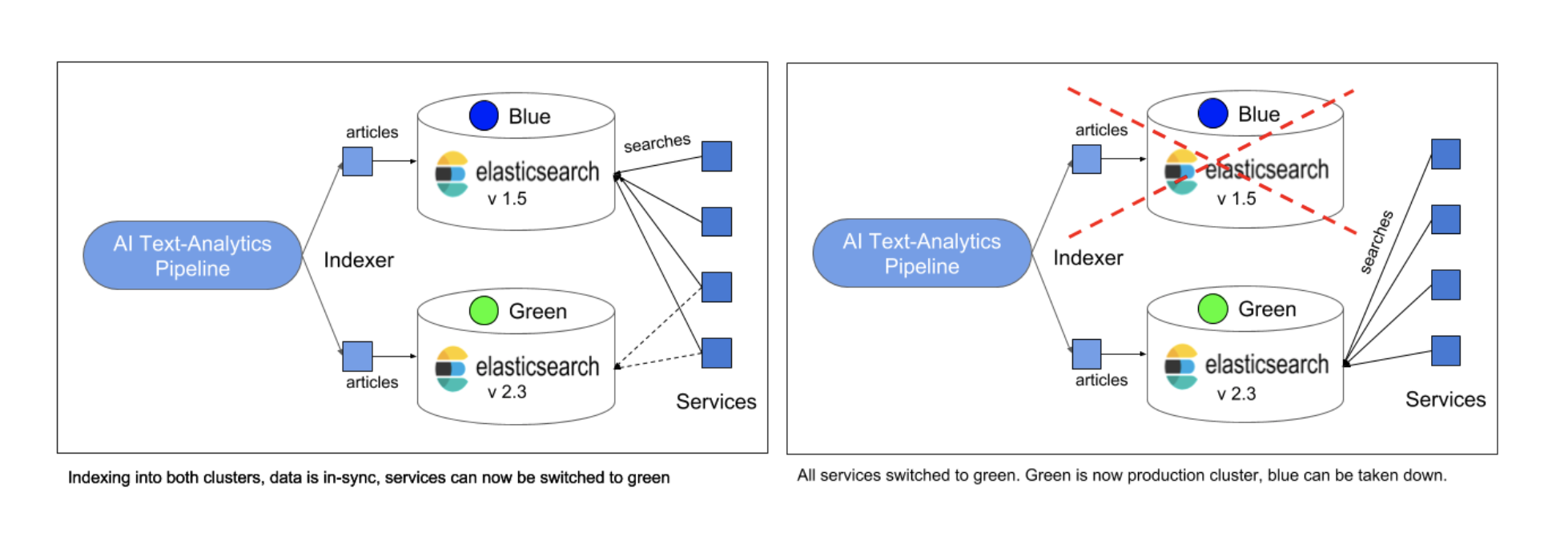
-===архив===-
Теперь загрузите архив Elasticsearch с официального сайта:
Распакуем архив:
Перемещаем распакованную папку в удобное место ( для простоты использования ):
И, переходим к настройке.
Тестирование Elasticsearch
Открываем браузер:
http://es.linux-notes.org:9200/
Или, можно выполнить в консоле:
# curl -X GET 'http://localhost:9200'
{
"name" : "My DataCenter",
"cluster_name" : "linux_notes_cluster_1",
"cluster_uuid" : "sXHdudwXRnODMpPBA2NA6Q",
"version" : {
"number" : "5.3.0",
"build_hash" : "3adb13b",
"build_date" : "2017-03-23T03:31:50.652Z",
"build_snapshot" : false,
"lucene_version" : "6.4.1"
},
"tagline" : "You Know, for Search"
}
Основные примеры использования Elasticearch
Следующие примеры помогут вам добавить, получить и найти данные в кластере Elasticsearch. Начнем, с создания бакета:
$ curl -XPUT http://localhost:9200/mybucket
Получаем:
{"acknowledged":true,"shards_acknowledged":true}
PS: Можно открыть ссылку в браузере.
Добавление данных в Elasticsearch
Чтобы начать использовать Elasticsearch, давайте сначала добавим некоторые данные. Как уже упоминалось, Elasticsearch использует API RESTful, который отвечает обычным командам CRUD: Create, Read, Update и Delete. Для работы с ним мы будем использовать curl.
$ curl -X POST 'http://localhost:9200/tutorial/helloworld/1' -d '{ "message": "Hello World!" }'
Вывод:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"created":true}
Я курлом, отправил HTTP POST реквест на Elasticseach сервер. УРЛа запроса, была /tutorial/helloworld/1
Здесь важно понять параметры:
- tutorial — Является индексом данных в Elasticsearch.
- helloworld — Это тип.
- 1 — Является идентификатором нашей записи под указанным выше индексом и типом.
Вы можете получить эту первую запись с HTTP GET-запросом:
$ curl -X GET 'http://localhost:9200/tutorial/helloworld/1'
Вывод:
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":1,"found":true,"_source":{ "message": "Hello World!" }}
Чтобы изменить существующую запись, вы можете использовать HTTP PUT-запрос следующим образом:
$ curl -X PUT 'localhost:9200/tutorial/helloworld/1?pretty' -d '
{
"message": "Hello Man!"
}'
И снова проверяем:
$ curl -X GET 'http://localhost:9200/tutorial/helloworld/1'
{"_index":"tutorial","_type":"helloworld","_id":"1","_version":3,"found":true,"_source":
{
"message": "Hello Man!"
Возможно, вы заметили дополнительный аргумент в приведенном выше запросе. Он позволяет читаемым человеком формате, чтобы вы могли писать каждое поле данных в новой строке. Вы также можете «приукрасить» свои результаты при извлечении данных и получить гораздо более приятный результат, например:
# curl -X GET 'http://localhost:9200/tutorial/helloworld/1?pretty'
{
"_index" : "tutorial",
"_type" : "helloworld",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"message" : "Hello Man!"
}
}
Проверка работы состояния кластера
И так, можно проверить состояния кластера следующим образом:
# curl -XGET 'http://localhost:9200/_cluster/health'
Зачастую, многие для более надежной безоспастности, используют авторизацию и по этому — стоит выполнять команду следующим образом:
# curl --user Your_USER:Your_Password -XGET 'http://localhost:9200/_cluster/health'
Или в более красивом виде:
# curl --user Your_USER:Your_Password -XGET 'http://localhost:9200/_cluster/health?pretty'
Вывод получим:
{
"cluster_name" : "cluster",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 1800,
"active_shards" : 3600,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
По статусу можно понять что все — ОК. Если будет другой цвет, скажем — красный (red) или желтый (yellow) — это уже не есть хорошо.
Вот и все, установка «Установка ElasticSearch (один сервер) кластер в Unix/Linux» завершена.
Модуль 2. Синхронизация файлов конфигураций узлов
Лабораторные работы
2.1 С использованием сервиса SSH
- Настройка доступа по протоколу ssh пользователя root с node1 на node2 ()
- Настройка безпарольного доступа пользователя root с node1 на node2 ()
node1# ssh-keygen ... Enter passphrase (empty for no passphrase): Пароль на ключ пустой!!! ... node1# ssh-copy-id node2
Проверка:
node1# scp /etc/hosts node2:/etc/
2.2 С использованием пакета CSYNC2
Сценарий: настроить DNS на node1, на node2 конфигурация появится автоматически
- Финальная настройка DNS сервера
- Устанавливаем и ЗАПУСКАЕМ на двух узлаx, настраиваем на node1
node1# sh dns.sh node1# cat /etc/bind/corpX.un
$TTL 3h
@ SOA ns root.ns 1 1d 12h 1w 3h
NS ns
ns A 192.168.X.1
ns A 192.168.X.2
node1 A 192.168.X.1
node2 A 192.168.X.2
gate A 192.168.X.254
node2# apt install bind9
-
Пакет CSYNC2
node1# csync2 -xv node1# host node1 node1# host node2 node1# host ns
2.3 С использованием пакета Ansible
Сценарий: на обоих узлах создаем пользователя user1 с uid=10001
Примечание: выполнить в 5-м модуле
Сервис Ansible
- Команда ssh-copy-id копирует …
- Где располагается файл с публичными ключами пользователей ssh?
- На каком узле будет сохранен файл в результате выполнения команды ssh node2 iptables-save > /etc/iptables.rules
- Что определяет параметр конфигурации auto younger в пакете csync2
- Перечислите известные Вам варианты тиражирования файлов конфигурации в кластере?
Настроить Elasticsearch в Linux
После установки Elasticsearch на машину Linux вам может потребоваться настроить его с IP-адресом вашего сервера, чтобы загрузить его вместе с вашим сервером. Здесь я использую адрес localhost (127.0.0.1) для его загрузки. Вы можете запустить следующую команду в оболочке терминала, чтобы открыть сценарий конфигурации.
sudo nano /etc/elasticsearch/elasticsearch.yml
Когда скрипт откроется, найдите параметр network.host и замените существующее значение на адрес вашего активного сервера. После изменения IP-адреса сохраните и выйдите из файла.
network.host: локальный
Теперь запустите и включите Elasticsearch в вашей системе Linux, чтобы перезагрузить его на вашем компьютере.
sudo systemctl start elasticsearch sudo systemctl enable elasticsearch
Когда вы добавляете новый IP-адрес с новым портом, всегда полезно добавить его в брандмауэр. Надо сказать, что по умолчанию Elasticsearch использует сетевые порты 9200-9300. Здесь я буду использовать порт 9200 для настройки Elasticsearch с адресом localhost.
Поскольку Ubuntu использует инструмент UFW для настройки брандмауэра, вы можете запустить следующие команды UFW в оболочке терминала, чтобы разрешить порт 9200 в вашей системе.
sudo ufw разрешить с 127.0.0.1 на любой порт 9200 sudo ufw enable
Теперь вы можете проверить статус UFW в оболочке терминала, чтобы проверить, добавлен ли порт в сетевой системе.
sudo ufw статус
Если вы используете Fedora, Red Hat Linux и другие дистрибутивы Linux, вы используете команду Firewalld, чтобы включить порт 9200 для вашей среды. Сначала включите Firewalld в вашей системе Linux.
systemctl status firewalld systemctl enable firewalld sudo firewall-cmd —reload
Теперь добавьте правило в настройки Firewalld. Затем перезапустите систему Angular CLI.
брандмауэр-cmd —add-port = 9200 / tcp firewall-cmd —list-все
Добавление ограничения совместного размещения
Почти каждое решение в кластере Pacemaker, например выбор места запуска ресурса, принимается путем сравнения оценок. Оценки вычисляются для каждого ресурса, а диспетчер ресурсов кластера выбирает узел с наивысшей оценкой для конкретного ресурса. (Если узел имеет отрицательную оценку для ресурса, последний не может выполняться в этом узле.) Используйте ограничения для настройки решений в кластере. Ограничения имеют оценку. Если ограничение имеет оценку меньше бесконечности (INFINITY), то это только рекомендация. Оценка, равная INFINITY, указывает на обязательный характер. Чтобы убедиться, что первичная реплика и ресурс виртуального IP-адреса находятся на одном узле, определите ограничение совместного размещения с оценкой INFINITY. Чтобы добавить ограничение совместного размещения, выполните приведенную ниже команду на одном узле.
Начать работу с Elasticsearch
После установки, настройки IP-адреса сервера и добавления правил брандмауэра в нашу систему Linux пришло время начать с ним. Здесь я запускаю команду cURL, чтобы отправить запрос на ваш сервер через Elasticsearch. В свою очередь, вы увидите имя хоста, имя кластера, UUID и строку тега Elasticsearch внизу страницы возврата.
curl -X GET ‘http: // localhost: 9200’
Мы можем попытаться вставить строковые данные в базу данных Elasticsearch и извлечь данные, чтобы проверить, работает ли она правильно или нет. Выполните следующую команду cURL, чтобы протолкнуть данные внутрь системы.
curl -X POST ‘http: // localhost: 9200 / ubuntupit / hello / 1’ -H ‘Content-Type: application / json’ -d ‘{«name»: «ubuntupit»}’
Чтобы получить строковые данные через Elasticsearch, выполните следующую команду в оболочке терминала вашей системы.
curl -X GET ‘http: // localhost: 9200 / ubuntupit / hello / 1’
Шаг 3 — Защита Elasticsearch
По умолчанию любой пользователь, который имеет доступ к HTTP API может контролировать Elasticsearch. Это не всегда связано с риском для безопасности, так как Elasticsearch прослушивает только циклический интерфейс (имеется в виду ), доступ к которому только локальный. Таким образом, невозможно получить публичный доступ к серверу, и, пока все пользователи сервера являются проверенными, вопрос безопасности не будет для вас серьезной проблемой.
Если вам потребуется разрешить удаленный доступ к HTTP API, вы можете ограничить открытость сети с помощью настроек брандмауэра Ubuntu по умолчанию, UFW. Этот брандмауэр уже должен быть активирован, если вы выполнили все предварительные шаги по начальной настройке сервера с Ubuntu 20.04.
Теперь мы настроим брандмауэр для доступа к порту HTTP API Elasticsearch по умолчанию (TCP 9200) для доверенного удаленного хоста. Как правило, это сервер, который вы используете при настройке на одном сервере, например . Для доступа введите следующую команду:
После этого вы можете активировать UFW с помощью команды:
В заключение проверьте статус UFW с помощью следующей команды:
Если вы правильно указали правила, вы должны получить следующий результат:
Теперь UFW должен быть активирован и настроен на защиту порта Elasticsearch 9200.
Если вы хотите инвестировать в дополнительную защиту, Elasticsearch предлагает к покупке платный плагин Shield.
Установка и настройка Winlogbeat
Для настройки централизованного сервера сбора логов с Windows серверов, установим сборщика системных логов winlogbeat. Для этого скачаем его и установим в качестве службы. Идем на страницу загрузок и скачиваем версию под вашу архитектуру — 32 или 64 бита.
Распаковываем скачанный архив и копируем его содержимое в директорию C:\Program Files\Winlogbeat. Сразу же создаем там папку logs для хранения логов самого winlogbeat.


Запускаем консоль Powershell от администратора и выполняем команды:
У меня был такой вывод:
Служба установилась и в данный момент она остановлена. Правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
В принципе, по тексту все понятно. Я беру 3 системных лога Application, Security, System (для русской версии используются такие же названия) и отправляю их на сервер с logstash. Настраиваю хранение логов и включаю мониторинг по аналогии с filebeat
Отдельно обращаю внимание на tags: . Этим тэгом я помечаю все отправляемые сообщения, чтобы потом их обработать в logstash и отправить в elasticsearch с отдельным индексом
Я не смог использовать поле type, по аналогии с filebeat, потому что в winlogbeat в поле type жестко прописано wineventlog и изменить его нельзя. Если у вас данные со всех серверов будут идти в один индекс, то можно tag не добавлять, а использовать указанное поле type для сортировки. Если же вы данные с разных среверов хотите помещать в разные индексы, то разделяйте их тэгами.
После настройки можно запустить службу winlogbeat, которая появится в списке служб windows. Но для того, чтобы логи виндовых журналов пошли в elasticsearch не в одну кучу вместе с nginx логами, нам надо настроить для них отдельный индекс в logstash в разделе output. Идем на сервер с logstash и правим конфиг output.conf.
Думаю, по тексту понятен смысл. Я разделил по разным индексам логи nginx, системные логи виндовых серверов и добавил отдельный индекс unknown_messages, в который будет попадать все то, что не попало в предыдущие. Это просто задел на будущее, когда конфигурация будет более сложная, можно будет ловить сообщения, которые по какой-то причине не попали ни в одно из приведенных выше правил.
Я не смог в одно правило поместить оба типа nginx_error и nginx_access, потому что не понял сходу, как это правильно записать, а по документации уже устал лазить, выискивать информацию. Так получился рабочий вариант. После этого перезапустил logstash, подождал немного, пока появятся новые логи на виндовом сервере, зашел в kibana и добавил новые индексы. Напомню, что делается это в разделе Management -> Kibana -> Index Patterns.
Можно идти в раздел Discover и просматривать логи с Windows серверов.
У меня без проблем все заработало на серверах с русской версией Windows. Все логи, тексты в сообщениях на русском языке нормально обрабатываются и отображаются. Проблем не возникло нигде.
На этом я закончил настройку стека Elasticsearch, Logstash, Kibana, Filebeat и Winlogbeat. Описал основной функционал по сбору логов. Дальше с ними уже можно работать по ситуации — строить графики, отчеты, собирать дашборды и т.д. Возможно, опишу это отдельно.
Шаг 4 — Тестирование Elasticsearch
Сейчас система Elasticsearch должна работать на порту 9200 Вы можете протестировать ее с помощью cURL и запроса GET.
Вы должны увидеть следующий ответ:
Если вы получите ответ, аналогичный вышеуказанному, значит Elasticsearch работает корректно. Если нет, убедитесь, что вы правильно выполнили инструкции по установке и дали время системе Elasticsearch для полного запуска.
Для более тщательной проверки Elasticsearch выполните следующую команду:
В выводе для команды, указанной выше, вы можете проверить все текущие настройки для узла, кластера, путей приложения, модулей и т.д.
Создание ресурса группы доступности
Чтобы создать ресурс группы доступности, используйте команду и задайте свойства ресурса. Приведенная ниже команда создает ресурс типа «основной/подчиненный» для группы доступности .
Примечание
При создании ресурса и периодически после этого агент ресурсов Pacemaker автоматически задает в группе доступности значение на основе ее конфигурации. Например, если группа доступности содержит три синхронные реплики, агент задаст для значение . Дополнительную информацию и параметры конфигурации см. в разделе High Availability and Data Protection for Availability Group Configurations (Высокий уровень доступности и защита данных для конфигураций групп доступности).
Создание кластера
Удалите любые существующие конфигурации кластера со всех узлов.
Команда sudo apt-get install pcs одновременно устанавливает pacemaker, corosync и pcs и запускает все 3 эти службы. При запуске corosync создается файл шаблона /etc/cluster/corosync.conf. Для успешного выполнения дальнейших действий этот файл должен отсутствовать, поэтому можно остановить выполнение pacemaker/corosync и удалить /etc/cluster/corosync.conf, тогда дальнейшие действия пройдут успешно. Команда pcs cluster destroy делает то же самое, и вы можете использовать ее в качестве средства однократной начальной настройки кластера.
Следующая команда удаляет все существующие файлы конфигурации кластера и останавливает все службы кластера. Это приводит к окончательному уничтожению кластера. Запустите ее в качестве первого шага в подготовительной среде
Обратите внимание, что команда pcs cluster destroy отключает службу pacemaker, которую требуется снова включить. Выполните на всех узлах следующую команду.
Предупреждение
Команда уничтожает все существующие ресурсы кластера.
Создайте кластер.
Предупреждение
Из-за известной проблемы, изучением которой уже занимается поставщик услуг кластеризации, при запуске кластера (pcs cluster start) возникает указанная ниже ошибка
Это связано с тем, что файл журнала, который настроен в /etc/corosync/corosync.conf и создается при выполнении команды установки кластера, является неверным. Чтобы обойти эту ошибку, измените файл журнала на /var/log/corosync/corosync.log. Кроме того, можно создать файл /var/log/cluster/corosync.log.
Указанная ниже команда создает кластер с тремя узлами. Перед выполнением данного сценария замените значения между . Выполните следующую команду на первичном узле.
Примечание
Если кластер был настроен ранее на тех же узлах, используйте параметр —force при выполнении команды pcs cluster setup
Обратите внимание, что это эквивалентно команде pcs cluster destroy. Службу Pacemaker необходимо включить повторно с помощью команды sudo systemctl enable pacemaker
5: Использование Elasticsearch
Чтобы начать работу с Elasticsearch, попробуйте добавить какие-нибудь данные. как уже говорилось, Elasticsearch использует RESTful API, отвечающий за простые операции CRUD (Create, Read, Update, Delete).
Используйте curl, чтобы добавить первую запись:
Команда вернёт:
Инструмент curl отправил HTTP POST-запрос серверу Elasticseach. URI запроса – /tutorial/helloworld/1. Рассмотрим параметры подробнее:
- tutorial – индекс данных Elasticsearch.
- helloworld – это тип данных.
- 1 – порядковый номер записи с таким индексом и типом.
Чтобы извлечь эту запись, создайте HTTP GET-запрос:
Результат выглядит так:
Чтобы отредактировать запись, создайте HTTP PUT-запрос:
Elasticsearch сообщит об удачном изменении данных:
В приведённом выше примере сообщение (message) было изменено на Hello People!. При этом номер записи был изменен на 2.
Возможно, вы обратили внимание на аргумент pretty в предыдущем запросе. Он включает удобочитаемый формат, благодаря чему можно вносить каждое поле данных с новой строки
Также можно улучшить внешний вид извлечённых данных и получить более понятный вывод:
Результат:
Чтобы ознакомиться с другими операциями Elasticsearch, читайте эту документацию.
Как видите, производительная платформа Elasticsearch довольно проста в установке и использовании.
ElasticSearchOracle JDK 8Ubuntu 16.04UFW
Создание ресурса виртуального IP-адреса
Чтобы создать ресурс виртуального IP-адреса, выполните указанную ниже команду на одном узле. Используйте доступный статический IP-адрес из сети. Перед выполнением этого скрипта замените значения между на допустимый IP-адрес.
В Pacemaker эквивалент имени виртуального сервера отсутствует. Чтобы использовать строку подключения, указывающую на строковое имя сервера, а не IP-адрес, зарегистрируйте IP-адрес ресурса и требуемое имя виртуального сервера в DNS. Для конфигураций аварийного восстановления зарегистрируйте имя и IP-адрес нужного виртуального сервера на DNS-серверах на основном сайте и сайте аварийного восстановления.
Установка Elasticsearch
Elasticsearch недоступен в стандартных репозиториях Debian 10. Мы установим его из репозитория Elasticsearch APT.
Импортируйте открытый ключ репозитория с помощью следующей команды :
Приведенная выше команда должна вывести , что означает, что ключ был успешно импортирован, и пакеты из этого репозитория будут считаться доверенными.
Добавьте репозиторий Elasticsearch в систему, запустив:
На момент написания этой статьи последняя версия Elasticsearch — . Если вы хотите установить предыдущую версию Elasticsearch, замените в приведенной выше команде на нужную вам версию.
Обновите индекс пакетов и установите движок Elasticsearch:
После завершения процесса установки запустите и включите службу:
Чтобы убедиться, что Elasticsearch запущен, используйте для отправки HTTP-запроса на порт 9200 на локальном хосте:
Результат будет выглядеть примерно так:
Запуск службы может занять 5–10 секунд. Если вы видите , подождите несколько секунд и повторите попытку.
Чтобы просмотреть сообщения, зарегистрированные службой Elasticsearch, используйте следующую команду:
Вот и все. Elasticsearch установлен на вашем сервере Debian.
Копирование числовых ячеек из 1С в Excel Промо
Решение проблемы, когда значения скопированных ячеек из табличных документов 1С в Excel воспринимаются последним как текст, т.е. без дополнительного форматирования значений невозможно применить арифметические операции. Поводом для публикации послужило понимание того, что целое предприятие с более сотней активных пользователей уже на протяжении года мучилось с такой, казалось бы на первый взгляд, тривиальной проблемой. Варианты решения, предложенные специалистами helpdesk, обслуживающими данное предприятие, а так же многочисленные обсуждения на форумах, только подтвердили убеждение в необходимости описания способа, который позволил мне качественно и быстро справиться с ситуацией.
5.5 Установите ik tokenizer
IK-токенизатор Lucene не поддерживался еще в 2012 году. Теперь мы собираемся использовать обновленную версию, основанную на нем, и он был разработан как интегрированный плагин для ElasticSearch. Он поддерживается и обновляется вместе с Elasticsearch. Версия также согласована, последняя Версия: 6.3.0
5.5.1. Установка
Загрузите zip-пакет в материалы предварительного курса и распакуйте его в каталог плагинов каталога Elasticsearch:
Используйте команду unzip для распаковки:
Затем перезапустите elasticsearch:
[Не удалось передать изображение по внешней ссылке. На исходном сайте может быть механизм ссылки, предотвращающий пиявку. Рекомендуется сохранить изображение и загрузить его напрямую (img-tRWoOxVR-1584342573903) (mdpic / 1558340588420.jpg)]
![Создание_отказоустойчивых_linux_решений_2020 [методические материалы лохтурова вячеслава]](https://myeditor.ru/wp-content/uploads/7/b/b/7bb896b87de5af1ba94efff2b1a47ae7.png)
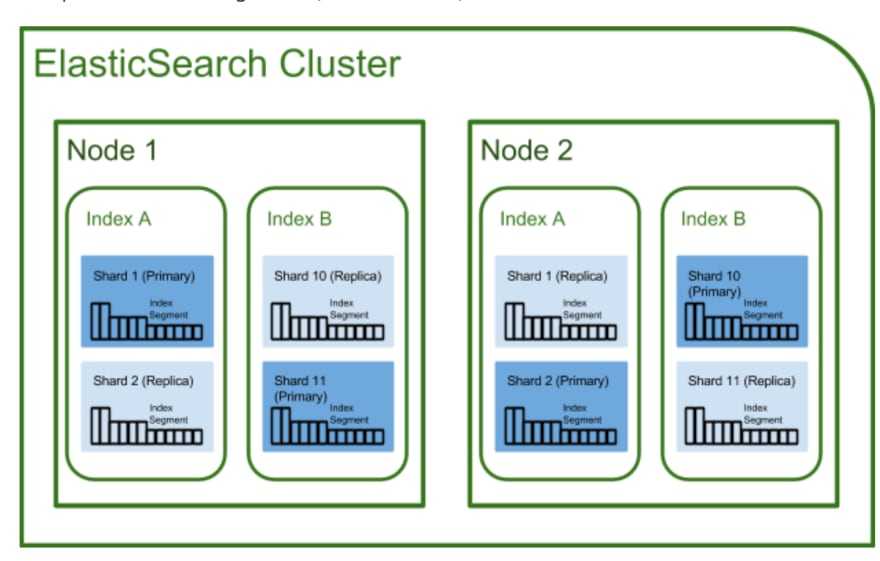
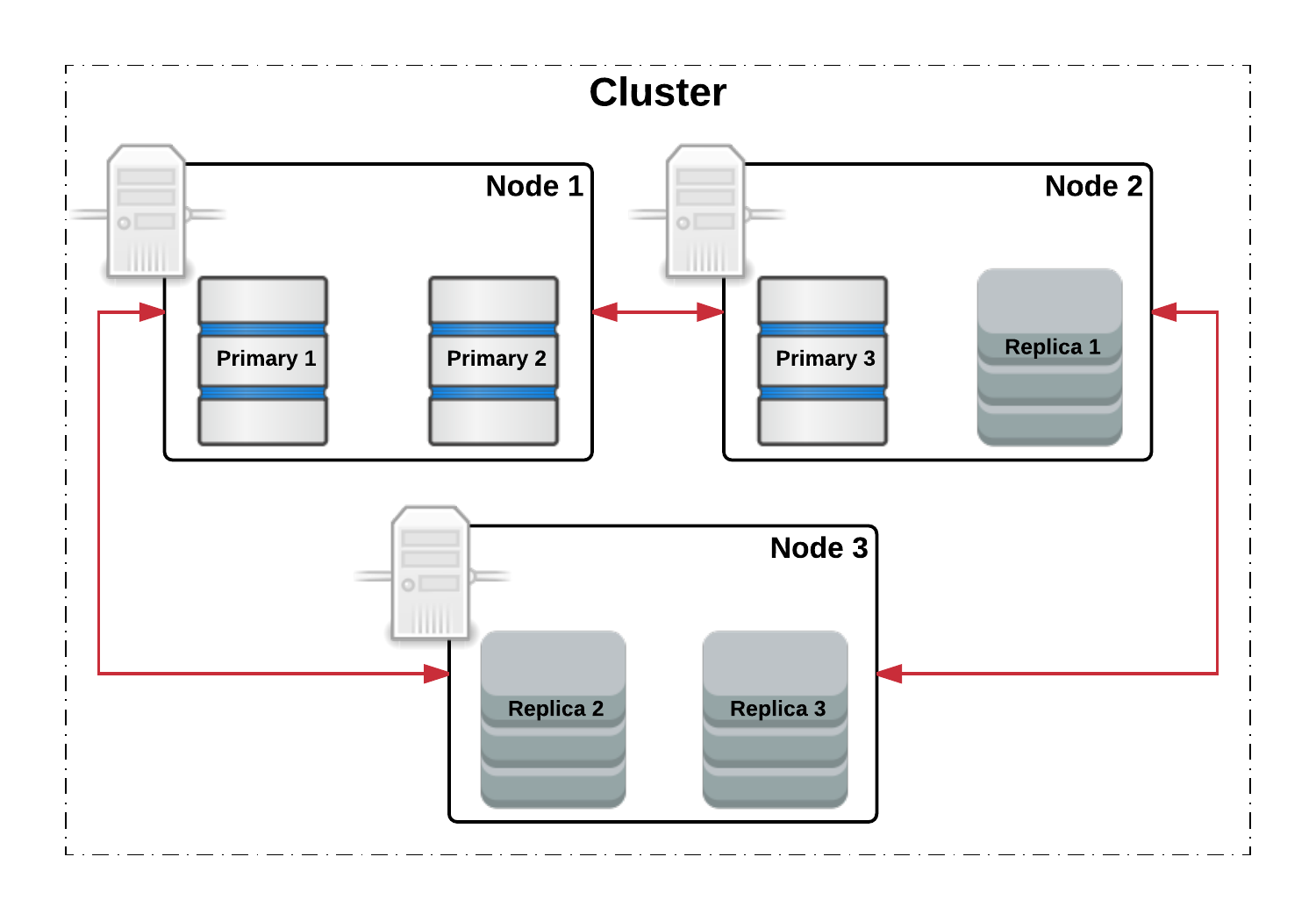
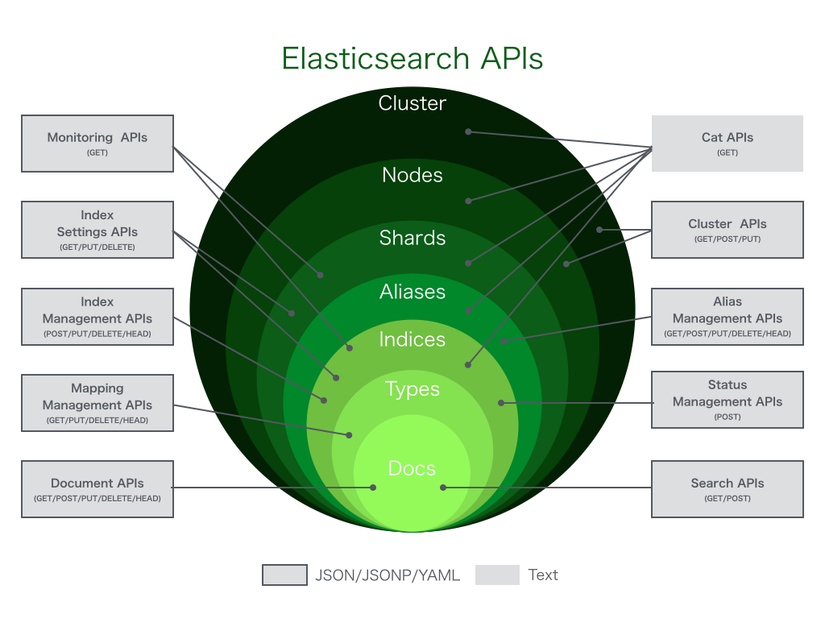
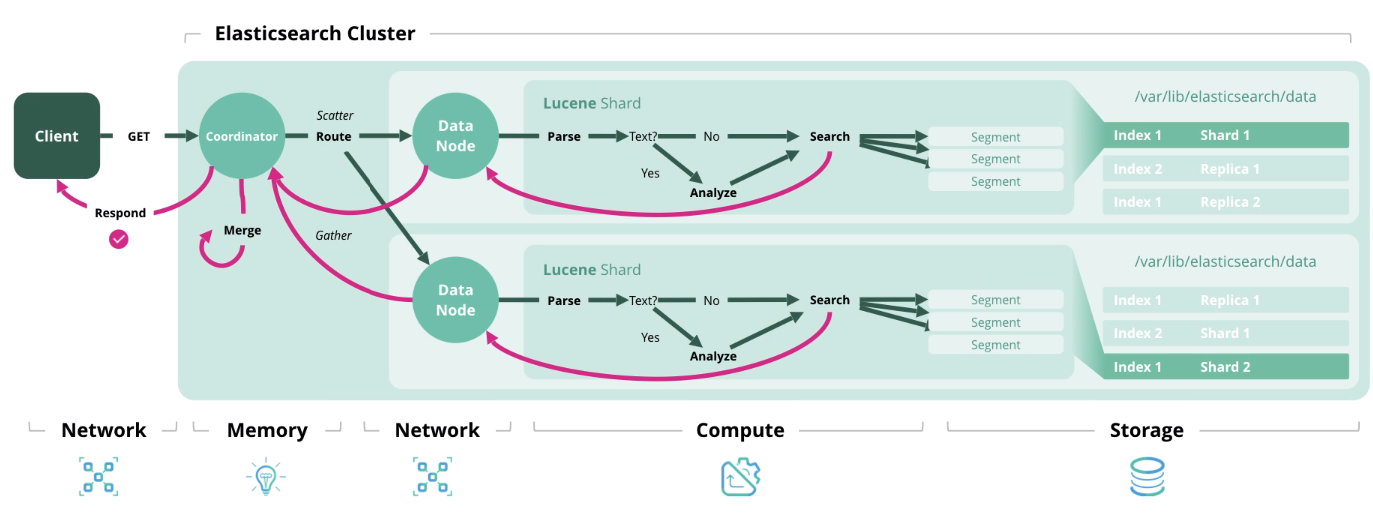
5.5.2. Тест
Независимо от грамматики, давайте сначала проверим это.
В консоли кибаны введите следующий запрос:
http://192.168.82.188:9200/_analyze
Беги за результатом:
Дополнительные настройки для обеспечения высокой доступности и производительности кластера Elasticsearch
Предотвращение ситуации split brain
Split brain — это ситуация, при которой соединение между узлами в кластере прерывается из-за сбоя в сети или внутреннего сбоя одного из узлов. В таком случае сразу несколько узлов могут назначить себя главным, что приведет к состоянию несогласованности данных.
Чтобы избежать данной ситуации, необходимо изменить директиву в файле конфигурации Elasticsearch, которая определяет, сколько узлов должно объединиться друг с другом (создать кворум) для выбора главного узла.
Чтобы определить это число, рекомендуется использовать следующую формулу: ОКРУГЛЕНИЕ_ВНИЗ [N / 2] + 1, где N — это общее число главных узлов в кластере.
Например, для кластера с тремя узлами:
discovery.zen.minimum_master_nodes: 2
Настройка размера JVM heap
Чтобы снизить риск появления ошибки в работе кластера Elasticsearch по причине недостаточности ресурсов, необходимо изменить размер кучи (JVM heap), заданный по умолчанию (минимум/максимум 1 Гбайт).
Как правило, максимальный размер кучи должен составлять не более 50% оперативной памяти, и не более 32 Гбайт (из-за неэффективности указателя Java в больших кучах). Elastic также рекомендует, чтобы значение для максимального и минимального размера было одинаковым.
Эти значения можно настроить с помощью параметров и в файле :
sudo nano /etc/elasticsearch/jvm.options -Xms2g -Xmx2g
Отключение подкачки
Подкачка в контексте Elasticsearch может привести к разрыву соединения, плохой производительности и в целом нестабильности кластера.
Чтобы не использовать подкачку, можно либо полностью отключить ее (рекомендуется, если Elasticsearch — единственная служба, работающая на сервере), либо использовать для блокировки оперативной памяти процесса Elasticsearch.
Для этого откройте файл конфигурации Elasticsearch на всех узлах кластера:
sudo vim /etc/elasticsearch/elasticsearch.yml
Раскомментируйте строку:
bootstrap.mlockall: true
Затем откройте файл :
sudo vim /etc/default/elasticsearch
Задайте настройку:
MAX_LOCKED_MEMORY=unlimited
Перезапустите Elasticsearch.
Настройка виртуальной памяти
Чтобы избежать ситуации, при которой виртуальной памяти становится недостаточно, увеличьте количество ограничений на счетчики :
sudo vim /etc/sysctl.conf
Обновите соответствующие настройки:
vm.max_map_count=262144
Увеличение предела количества дескрипторов открытых файлов
Другая важная конфигурация — ограничение на количество дескрипторов открытых файлов. Поскольку Elasticsearch использует большое количество файловых дескрипторов, необходимо убедиться, что установленного предела достаточно, иначе можно потерять данные.
Рекомендуемое значение для этого параметра — 65536 и выше. Настройки по умолчанию уже заданы в соответствии с этим требованием, но, конечно, их можно уточнить.
sudo nano /etc/security/limits.conf
Установите лимит:
- nofile 65536
Задание свойства кластера cluster-recheck-interval
указывает интервал опроса, с которым кластер проверяет наличие изменений в параметрах ресурсов, ограничениях или других параметрах кластера. Если реплика выходит из строя, кластер пытается перезапустить ее с интервалом, который связан со значениями и . Например, если для установлено значение 60 с, а для — 120 с, то повторная попытка перезапуска предпринимается с интервалом, который больше 60 с, но меньше 120 с. Мы рекомендуем установить для failure-timeout значение, равное 60 с, а для cluster-recheck-interval значение больше 60 с. Задавать для cluster-recheck-interval небольшое значение не рекомендуется.
Чтобы изменить значение свойства на , выполните следующую команду:
Важно!
Если у вас уже есть ресурс группы доступности, управляемый кластером Pacemaker, обратите внимание, что все дистрибутивы, использующие последний доступный пакет Pacemaker 1.1.18-11.el7, вносят изменение в поведение для параметра start-failure-is-fatal cluster, когда его значение равно false. Это изменение влияет на рабочий процесс отработки отказа
В случае сбоя первичной реплики ожидается, что будет выполнена отработка отказа кластера на одну из доступных вторичных реплик. Вместо этого пользователи увидят, что кластер продолжает попытки запустить первичную реплику с ошибкой. Если первичная реплика не включается (из-за постоянного сбоя), кластер не выполняет отработку отказа на другую доступную вторичную реплику. Из-за этого изменения рекомендуемая ранее конфигурация для установки параметра start-failure-is-fatal больше не действительна, и для этого параметра нужно вернуть значение по умолчанию . Кроме того, нужно обновить ресурс группы доступности для включения свойства .
Чтобы изменить значение свойства на , выполните следующую команду:
Измените существующее свойство ресурса группы доступности на выполнение (замените именем ресурса группы доступности).
Выводы
Elasticsearch — популярный инструмент для создания собственной поисковой системы. Вы должны знать, что крупный гигант электронной коммерции Amazon использует Elasticsearch для поиска в своих магазинах. Во всем посте я описал, как вы можете установить, настроить и запустить свой первый запрос в Elasticsearch. Вы также можете запустить логический запрос, разбить данные на страницы с помощью Elasticseach и использовать инструменты пользовательского интерфейса, такие как Kibana, для использования Elasticsearch с существующей базой данных.
Пожалуйста, поделитесь этим постом со своими друзьями и сообществом Linux, если вы сочтете его полезным и удобным. Вы также можете записать свое мнение об этом сообщении в разделе комментариев.
Заключение
Вы установили, настроили и начали использовать Elasticsearch. С момента первоначального выпуска Elasticsearch команда Elastic разработала три дополнительных инструмента, Logstash, Kabana и Beats, предназначенные для использования совместно с Elasticsearch в составе комплекса Elastic. Вместе эти инструменты обеспечивают возможность поиска, анализа и визуализации журналов в любом формате, сгенерированных любым источником, посредством практики, называемой централизованным ведением журнала. Чтобы познакомиться с использованием комплекса Elastic в Ubuntu 18.04, воспользуйтесь нашим руководством Установка Elasticsearch, Logstash и Kibana (комплекс Elastic) в Ubuntu 18.04.





